 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Character-based Diffusion Embedding Algorithm for Enhancing the Generation Quality of Generative Linguistic Steganographic Texts
May 02, 2025Generating high-quality steganographic text is a fundamental challenge in the field of generative linguistic steganography. This challenge arises primarily from two aspects: firstly, the capabilities of existing models in text generation are limited; secondly, embedding algorithms fail to effectively mitigate the negative impacts of sensitive information's properties, such as semantic content or randomness. Specifically, to ensure that the recipient can accurately extract hidden information, embedding algorithms often have to consider selecting candidate words with relatively low probabilities. This phenomenon leads to a decrease in the number of high-probability candidate words and an increase in low-probability candidate words, thereby compromising the semantic coherence and logical fluency of the steganographic text and diminishing the overall quality of the generated steganographic material. To address this issue, this paper proposes a novel embedding algorithm, character-based diffusion embedding algorithm (CDEA). Unlike existing embedding algorithms that strive to eliminate the impact of sensitive information's properties on the generation process, CDEA leverages sensitive information's properties. It enhances the selection frequency of high-probability candidate words in the candidate pool based on general statistical properties at the character level and grouping methods based on power-law distributions, while reducing the selection frequency of low-probability candidate words in the candidate pool. Furthermore, to ensure the effective transformation of sensitive information in long sequences, we also introduce the XLNet model. Experimental results demonstrate that the combination of CDEA and XLNet significantly improves the quality of generated steganographic text, particularly in terms of perceptual-imperceptibility.
Looking From the Future: Multi-order Iterations Can Enhance Adversarial Attack Transferability
Jul 02, 2024



Various methods try to enhance adversarial transferability by improving the generalization from different perspectives. In this paper, we rethink the optimization process and propose a novel sequence optimization concept, which is named Looking From the Future (LFF). LFF makes use of the original optimization process to refine the very first local optimization choice. Adapting the LFF concept to the adversarial attack task, we further propose an LFF attack as well as an MLFF attack with better generalization ability. Furthermore, guiding with the LFF concept, we propose an $LLF^{\mathcal{N}}$ attack which entends the LFF attack to a multi-order attack, further enhancing the transfer attack ability. All our proposed methods can be directly applied to the iteration-based attack methods. We evaluate our proposed method on the ImageNet1k dataset by applying several SOTA adversarial attack methods under four kinds of tasks. Experimental results show that our proposed method can greatly enhance the attack transferability. Ablation experiments are also applied to verify the effectiveness of each component. The source code will be released after this paper is accepted.
Robust Model Aggregation for Heterogeneous Federated Learning: Analysis and Optimizations
May 11, 2024



Conventional synchronous federated learning (SFL) frameworks suffer from performance degradation in heterogeneous systems due to imbalanced local data size and diverse computing power on the client side. To address this problem, asynchronous FL (AFL) and semi-asynchronous FL have been proposed to recover the performance loss by allowing asynchronous aggregation. However, asynchronous aggregation incurs a new problem of inconsistency between local updates and global updates. Motivated by the issues of conventional SFL and AFL, we first propose a time-driven SFL (T-SFL) framework for heterogeneous systems. The core idea of T-SFL is that the server aggregates the models from different clients, each with varying numbers of iterations, at regular time intervals. To evaluate the learning performance of T-SFL, we provide an upper bound on the global loss function. Further, we optimize the aggregation weights to minimize the developed upper bound. Then, we develop a discriminative model selection (DMS) algorithm that removes local models from clients whose number of iterations falls below a predetermined threshold. In particular, this algorithm ensures that each client's aggregation weight accurately reflects its true contribution to the global model update, thereby improving the efficiency and robustness of the system. To validate the effectiveness of T-SFL with the DMS algorithm, we conduct extensive experiments using several popular datasets including MNIST, Cifar-10, Fashion-MNIST, and SVHN. The experimental results demonstrate that T-SFL with the DMS algorithm can reduce the latency of conventional SFL by 50\%, while achieving an average 3\% improvement in learning accuracy over state-of-the-art AFL algorithms.
Boost Adversarial Transferability by Uniform Scale and Mix Mask Method
Nov 18, 2023Adversarial examples generated from surrogate models often possess the ability to deceive other black-box models, a property known as transferability. Recent research has focused on enhancing adversarial transferability, with input transformation being one of the most effective approaches. However, existing input transformation methods suffer from two issues. Firstly, certain methods, such as the Scale-Invariant Method, employ exponentially decreasing scale invariant parameters that decrease the adaptability in generating effective adversarial examples across multiple scales. Secondly, most mixup methods only linearly combine candidate images with the source image, leading to reduced features blending effectiveness. To address these challenges, we propose a framework called Uniform Scale and Mix Mask Method (US-MM) for adversarial example generation. The Uniform Scale approach explores the upper and lower boundaries of perturbation with a linear factor, minimizing the negative impact of scale copies. The Mix Mask method introduces masks into the mixing process in a nonlinear manner, significantly improving the effectiveness of mixing strategies. Ablation experiments are conducted to validate the effectiveness of each component in US-MM and explore the effect of hyper-parameters. Empirical evaluations on standard ImageNet datasets demonstrate that US-MM achieves an average of 7% better transfer attack success rate compared to state-of-the-art methods.
Real-centric Consistency Learning for Deepfake Detection
May 15, 2022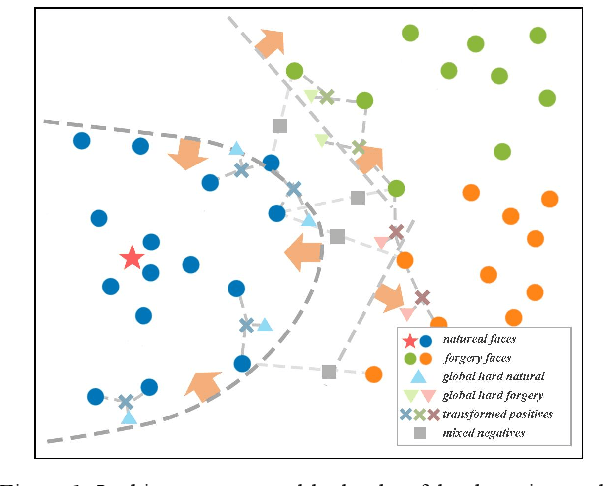


Most of previous deepfake detection researches bent their efforts to describe and discriminate artifacts in human perceptible ways, which leave a bias in the learned networks of ignoring some critical invariance features intra-class and underperforming the robustness of internet interference. Essentially, the target of deepfake detection problem is to represent natural faces and fake faces at the representation space discriminatively, and it reminds us whether we could optimize the feature extraction procedure at the representation space through constraining intra-class consistence and inter-class inconsistence to bring the intra-class representations close and push the inter-class representations apart? Therefore, inspired by contrastive representation learning, we tackle the deepfake detection problem through learning the invariant representations of both classes and propose a novel real-centric consistency learning method. We constraint the representation from both the sample level and the feature level. At the sample level, we take the procedure of deepfake synthesis into consideration and propose a novel forgery semantical-based pairing strategy to mine latent generation-related features. At the feature level, based on the centers of natural faces at the representation space, we design a hard positive mining and synthesizing method to simulate the potential marginal features. Besides, a hard negative fusion method is designed to improve the discrimination of negative marginal features with the help of supervised contrastive margin loss we developed. The effectiveness and robustness of the proposed method has been demonstrated through extensive experiments.
Understanding CNNs from excitations
May 04, 2022
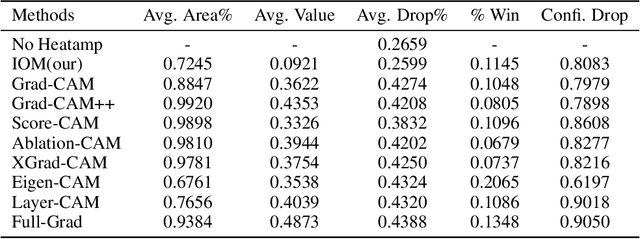
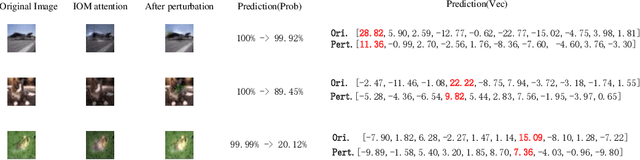
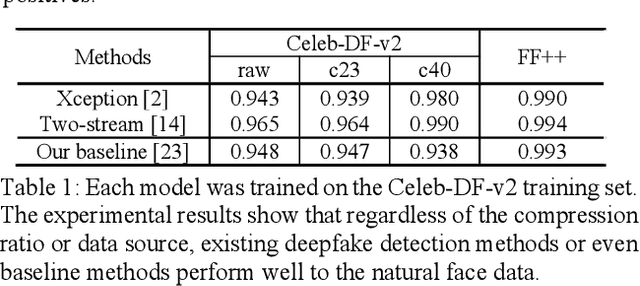
For instance-level explanation, in order to reveal the relations between high-level semantics and detailed spatial information, this paper proposes a novel cognitive approach to neural networks, which named PANE. Under the guidance of PANE, a novel saliency map representation method, named IOM, is proposed for CNN-like models. We make the comparison with eight state-of-the-art saliency map representation methods. The experimental results show that IOM far outperforms baselines. The work of this paper may bring a new perspective to understand deep neural networks.
Can We Leverage Predictive Uncertainty to Detect Dataset Shift and Adversarial Examples in Android Malware Detection?
Sep 20, 2021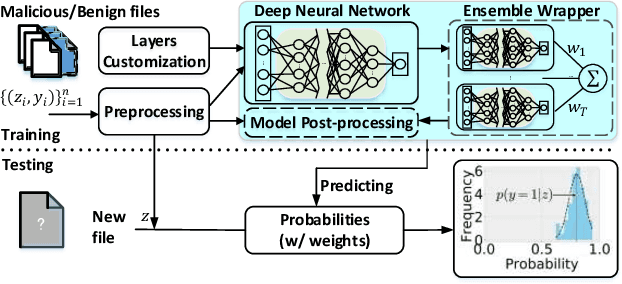
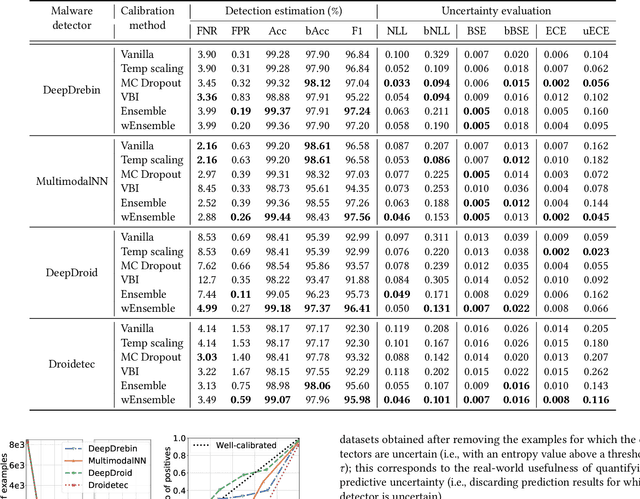
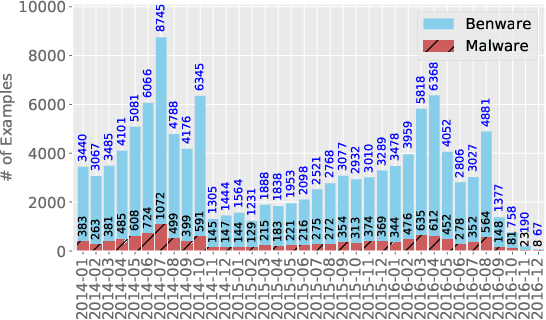
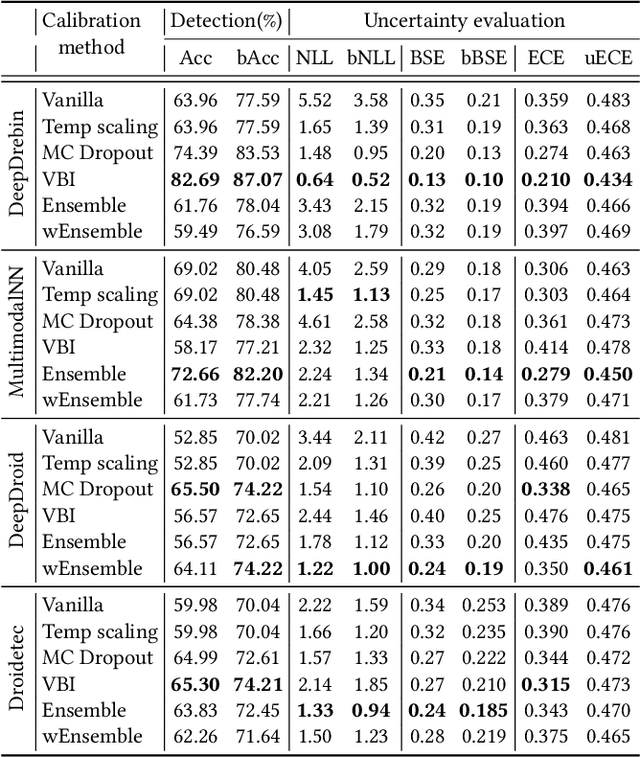
The deep learning approach to detecting malicious software (malware) is promising but has yet to tackle the problem of dataset shift, namely that the joint distribution of examples and their labels associated with the test set is different from that of the training set. This problem causes the degradation of deep learning models without users' notice. In order to alleviate the problem, one approach is to let a classifier not only predict the label on a given example but also present its uncertainty (or confidence) on the predicted label, whereby a defender can decide whether to use the predicted label or not. While intuitive and clearly important, the capabilities and limitations of this approach have not been well understood. In this paper, we conduct an empirical study to evaluate the quality of predictive uncertainties of malware detectors. Specifically, we re-design and build 24 Android malware detectors (by transforming four off-the-shelf detectors with six calibration methods) and quantify their uncertainties with nine metrics, including three metrics dealing with data imbalance. Our main findings are: (i) predictive uncertainty indeed helps achieve reliable malware detection in the presence of dataset shift, but cannot cope with adversarial evasion attacks; (ii) approximate Bayesian methods are promising to calibrate and generalize malware detectors to deal with dataset shift, but cannot cope with adversarial evasion attacks; (iii) adversarial evasion attacks can render calibration methods useless, and it is an open problem to quantify the uncertainty associated with the predicted labels of adversarial examples (i.e., it is not effective to use predictive uncertainty to detect adversarial examples).
Adversarial Deep Ensemble: Evasion Attacks and Defenses for Malware Detection
Jun 30, 2020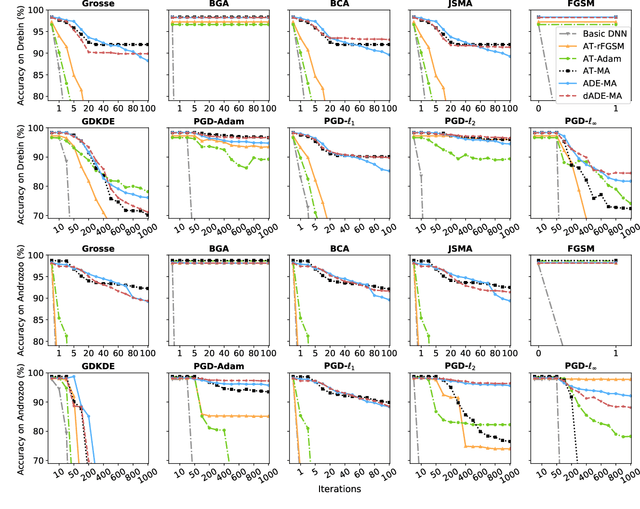
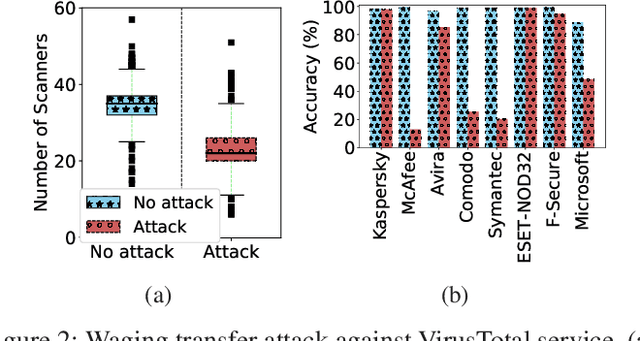

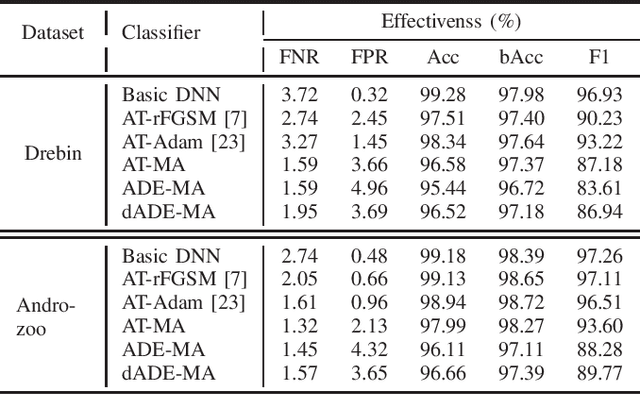
Malware remains a big threat to cyber security, calling for machine learning based malware detection. While promising, such detectors are known to be vulnerable to evasion attacks. Ensemble learning typically facilitates countermeasures, while attackers can leverage this technique to improve attack effectiveness as well. This motivates us to investigate which kind of robustness the ensemble defense or effectiveness the ensemble attack can achieve, particularly when they combat with each other. We thus propose a new attack approach, named mixture of attacks, by rendering attackers capable of multiple generative methods and multiple manipulation sets, to perturb a malware example without ruining its malicious functionality. This naturally leads to a new instantiation of adversarial training, which is further geared to enhancing the ensemble of deep neural networks. We evaluate defenses using Android malware detectors against 26 different attacks upon two practical datasets. Experimental results show that the new adversarial training significantly enhances the robustness of deep neural networks against a wide range of attacks, ensemble methods promote the robustness when base classifiers are robust enough, and yet ensemble attacks can evade the enhanced malware detectors effectively, even notably downgrading the VirusTotal service.
SoK: Arms Race in Adversarial Malware Detection
Jun 15, 2020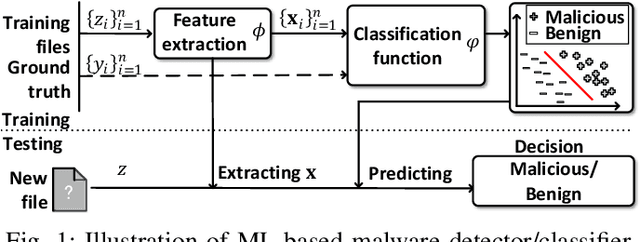
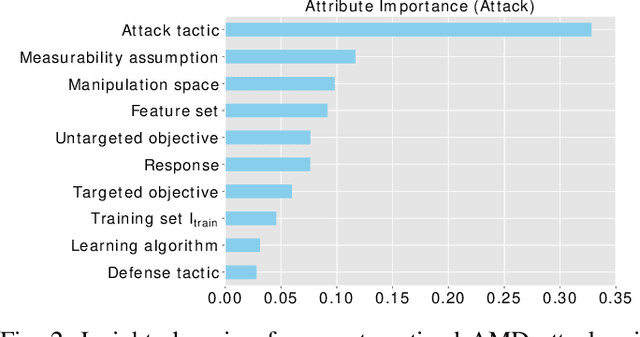
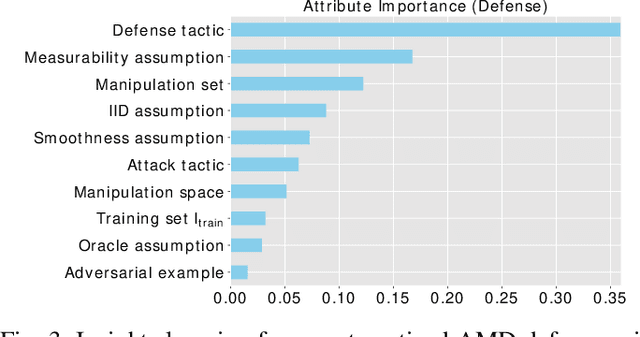
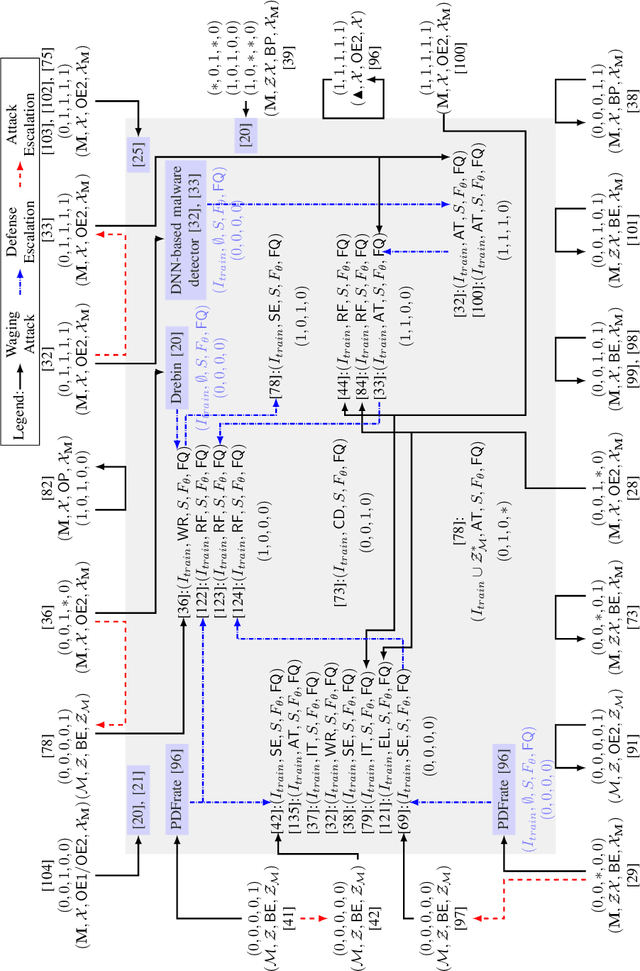
Malicious software (malware) is a major cyber threat that shall be tackled with Machine Learning (ML) techniques because millions of new malware examples are injected into cyberspace on a daily basis. However, ML is known to be vulnerable to attacks known as adversarial examples. In this SoK paper, we systematize the field of Adversarial Malware Detection (AMD) through the lens of a unified framework of assumptions, attacks, defenses and security properties. This not only guides us to map attacks and defenses into some partial order structures, but also allows us to clearly describe the attack-defense arms race in the AMD context. In addition to manually drawing insights, we also propose using ML to draw insights from the systematized representation of the literature. Examples of the insights are: knowing the defender's feature set is critical to the attacker's success; attack tactic (as a core part of the threat model) largely determines what security property of a malware detector can be broke; there is currently no silver bullet defense against evasion attacks or poisoning attacks; defense tactic largely determines what security properties can be achieved by a malware detector; knowing attacker's manipulation set is critical to defender's success; ML is an effective method for insights learning in SoK studies. These insights shed light on future research directions.
Enhancing Deep Neural Networks Against Adversarial Malware Examples
Apr 15, 2020
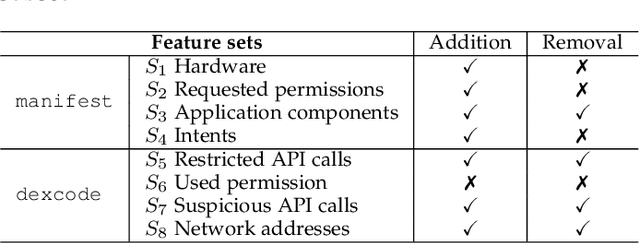
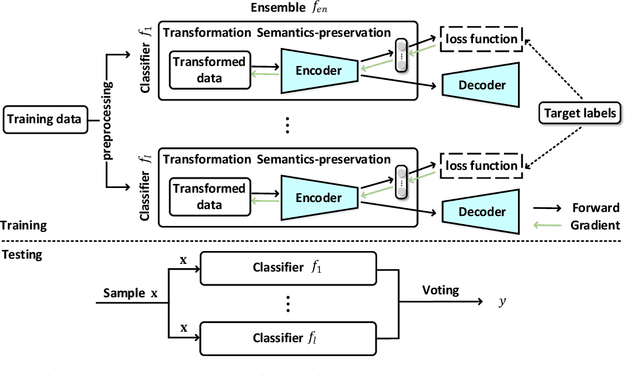
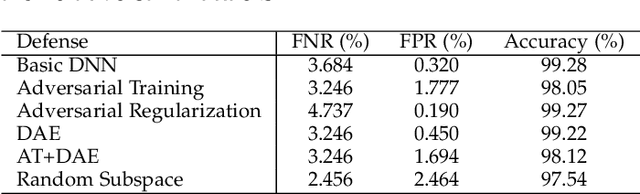
Machine learning based malware detection is known to be vulnerable to adversarial evasion attacks. The state-of-the-art is that there are no effective countermeasures against these attacks. Inspired by the AICS'2019 Challenge organized by the MIT Lincoln Lab, we systematize a number of principles for enhancing the robustness of neural networks against adversarial malware evasion attacks. Some of these principles have been scattered in the literature, but others are proposed in this paper for the first time. Under the guidance of these principles, we propose a framework for defending against adversarial malware evasion attacks. We validated the framework using the Drebin dataset of Android malware. We applied the defense framework to the AICS'2019 Challenge and won, without knowing how the organizers generated the adversarial examples. However, we see a ~22\% difference between the accuracy in the experiment with the Drebin dataset (for binary classification) and the accuracy in the experiment with respect to the AICS'2019 Challenge (for multiclass classification). We attribute this gap to a fundamental barrier that without knowing the attacker's manipulation set, the defender cannot do effective Adversarial Training.