 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic AI for Cybersecurity: State of the Art, Challenges, and Opportunities
Sep 08, 2025
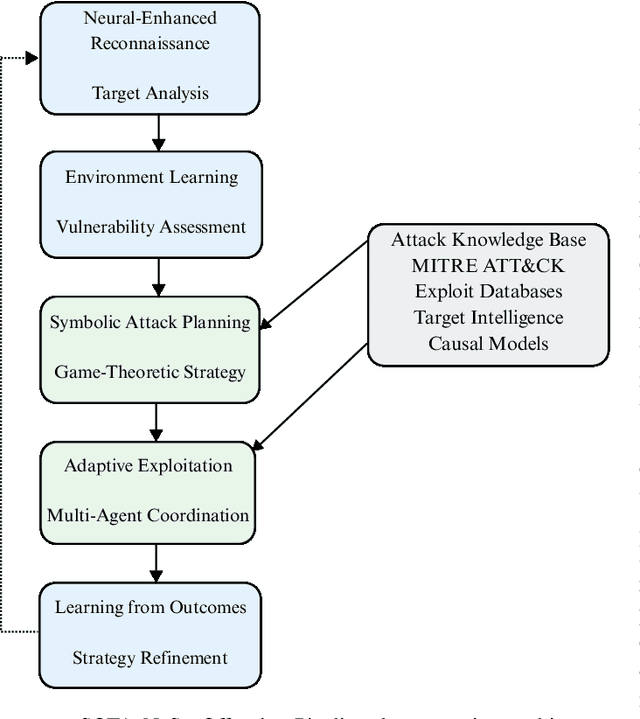


Traditional Artificial Intelligence (AI) approaches in cybersecurity exhibit fundamental limitations: inadequate conceptual grounding leading to non-robustness against novel attacks; limited instructibility impeding analyst-guided adaptation; and misalignment with cybersecurity objectives. Neuro-Symbolic (NeSy) AI has emerged with the potential to revolutionize cybersecurity AI. However, there is no systematic understanding of this emerging approach. These hybrid systems address critical cybersecurity challenges by combining neural pattern recognition with symbolic reasoning, enabling enhanced threat understanding while introducing concerning autonomous offensive capabilities that reshape threat landscapes. In this survey, we systematically characterize this field by analyzing 127 publications spanning 2019-July 2025. We introduce a Grounding-Instructibility-Alignment (G-I-A) framework to evaluate these systems, focusing on both cyber defense and cyber offense across network security, malware analysis, and cyber operations. Our analysis shows advantages of multi-agent NeSy architectures and identifies critical implementation challenges including standardization gaps, computational complexity, and human-AI collaboration requirements that constrain deployment. We show that causal reasoning integration is the most transformative advancement, enabling proactive defense beyond correlation-based approaches. Our findings highlight dual-use implications where autonomous systems demonstrate substantial capabilities in zero-day exploitation while achieving significant cost reductions, altering threat dynamics. We provide insights and future research directions, emphasizing the urgent need for community-driven standardization frameworks and responsible development practices that ensure advancement serves defensive cybersecurity objectives while maintaining societal alignment.
PAD: Towards Principled Adversarial Malware Detection Against Evasion Attacks
Feb 22, 2023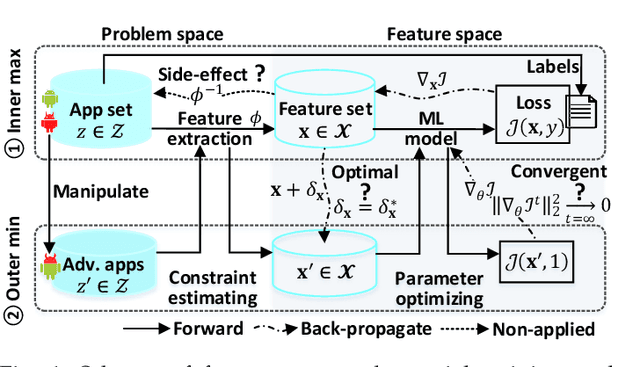
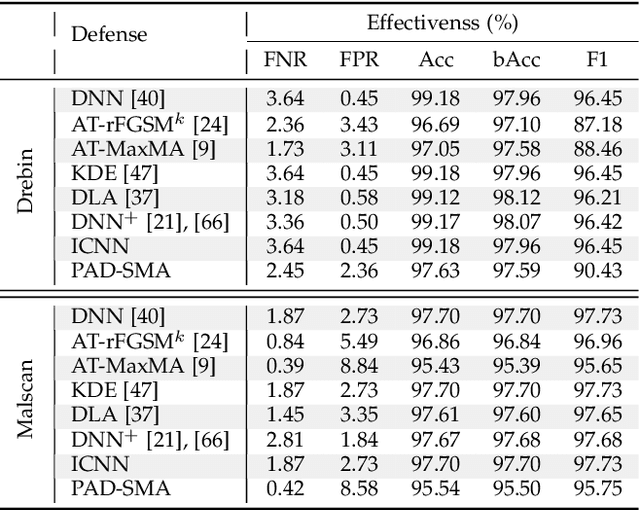
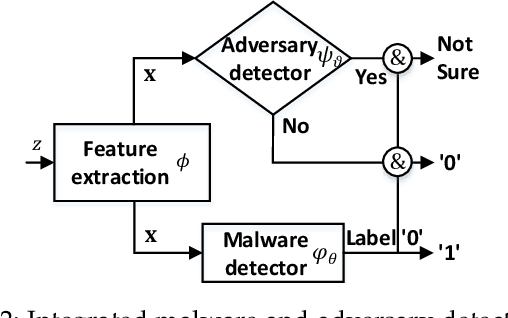
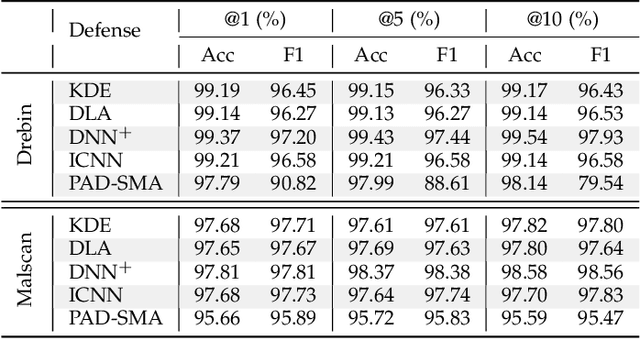
Machine Learning (ML) techniques facilitate automating malicious software (malware for short) detection, but suffer from evasion attacks. Many researchers counter such attacks in heuristic manners short of both theoretical guarantees and defense effectiveness. We hence propose a new adversarial training framework, termed Principled Adversarial Malware Detection (PAD), which encourages convergence guarantees for robust optimization methods. PAD lays on a learnable convex measurement that quantifies distribution-wise discrete perturbations and protects the malware detector from adversaries, by which for smooth detectors, adversarial training can be performed heuristically with theoretical treatments. To promote defense effectiveness, we propose a new mixture of attacks to instantiate PAD for enhancing the deep neural network-based measurement and malware detector. Experimental results on two Android malware datasets demonstrate: (i) the proposed method significantly outperforms the state-of-the-art defenses; (ii) it can harden the ML-based malware detection against 27 evasion attacks with detection accuracies greater than 83.45%, while suffering an accuracy decrease smaller than 2.16% in the absence of attacks; (iii) it matches or outperforms many anti-malware scanners in VirusTotal service against realistic adversarial malware.
RoPGen: Towards Robust Code Authorship Attribution via Automatic Coding Style Transformation
Feb 12, 2022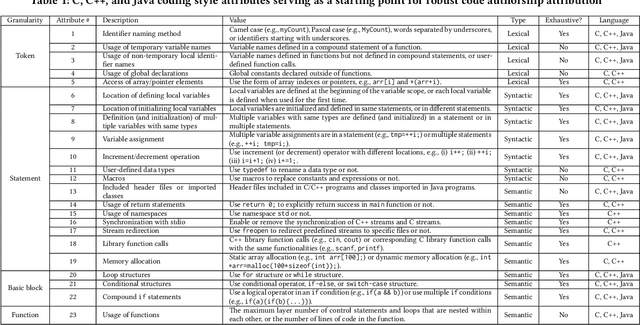
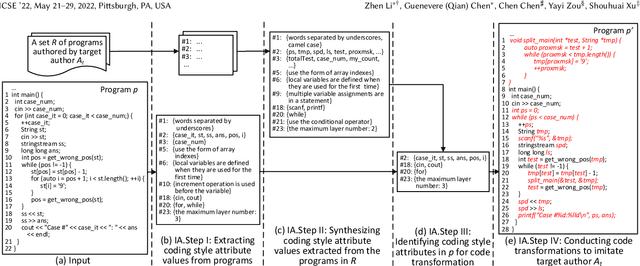
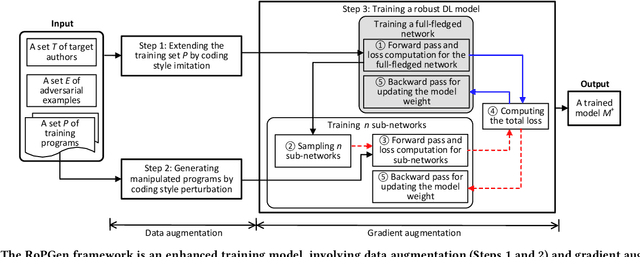

Source code authorship attribution is an important problem often encountered in applications such as software forensics, bug fixing, and software quality analysis. Recent studies show that current source code authorship attribution methods can be compromised by attackers exploiting adversarial examples and coding style manipulation. This calls for robust solutions to the problem of code authorship attribution. In this paper, we initiate the study on making Deep Learning (DL)-based code authorship attribution robust. We propose an innovative framework called Robust coding style Patterns Generation (RoPGen), which essentially learns authors' unique coding style patterns that are hard for attackers to manipulate or imitate. The key idea is to combine data augmentation and gradient augmentation at the adversarial training phase. This effectively increases the diversity of training examples, generates meaningful perturbations to gradients of deep neural networks, and learns diversified representations of coding styles. We evaluate the effectiveness of RoPGen using four datasets of programs written in C, C++, and Java. Experimental results show that RoPGen can significantly improve the robustness of DL-based code authorship attribution, by respectively reducing 22.8% and 41.0% of the success rate of targeted and untargeted attacks on average.
Can We Leverage Predictive Uncertainty to Detect Dataset Shift and Adversarial Examples in Android Malware Detection?
Sep 20, 2021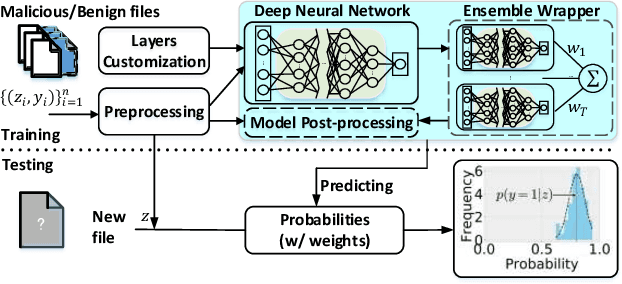
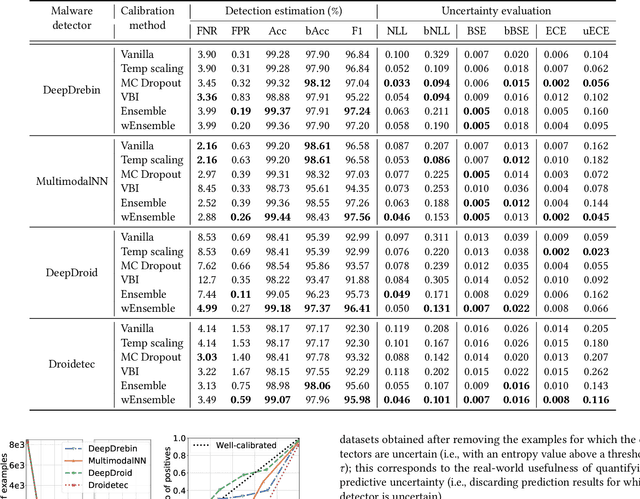
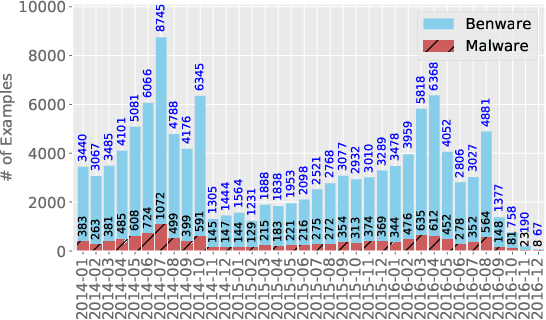
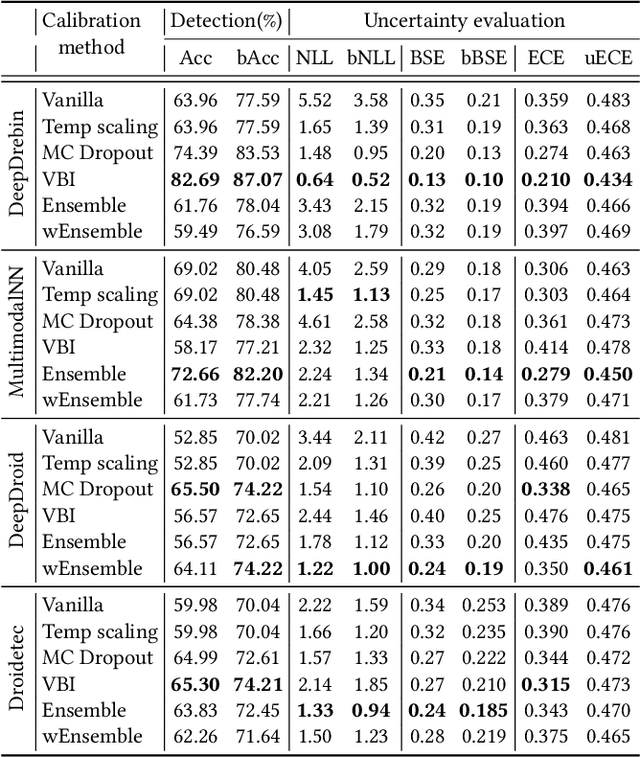
The deep learning approach to detecting malicious software (malware) is promising but has yet to tackle the problem of dataset shift, namely that the joint distribution of examples and their labels associated with the test set is different from that of the training set. This problem causes the degradation of deep learning models without users' notice. In order to alleviate the problem, one approach is to let a classifier not only predict the label on a given example but also present its uncertainty (or confidence) on the predicted label, whereby a defender can decide whether to use the predicted label or not. While intuitive and clearly important, the capabilities and limitations of this approach have not been well understood. In this paper, we conduct an empirical study to evaluate the quality of predictive uncertainties of malware detectors. Specifically, we re-design and build 24 Android malware detectors (by transforming four off-the-shelf detectors with six calibration methods) and quantify their uncertainties with nine metrics, including three metrics dealing with data imbalance. Our main findings are: (i) predictive uncertainty indeed helps achieve reliable malware detection in the presence of dataset shift, but cannot cope with adversarial evasion attacks; (ii) approximate Bayesian methods are promising to calibrate and generalize malware detectors to deal with dataset shift, but cannot cope with adversarial evasion attacks; (iii) adversarial evasion attacks can render calibration methods useless, and it is an open problem to quantify the uncertainty associated with the predicted labels of adversarial examples (i.e., it is not effective to use predictive uncertainty to detect adversarial examples).
Towards Making Deep Learning-based Vulnerability Detectors Robust
Aug 04, 2021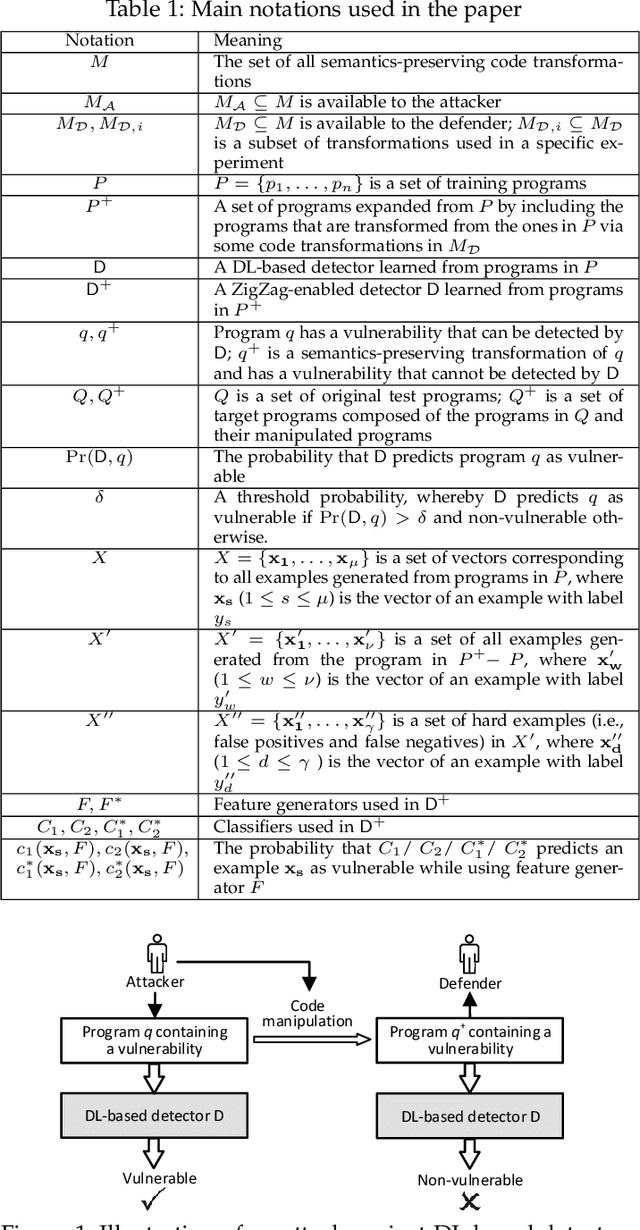
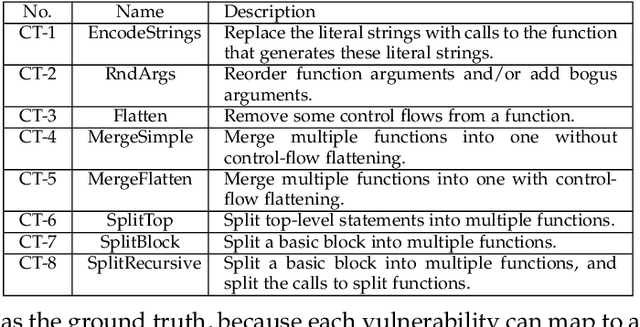
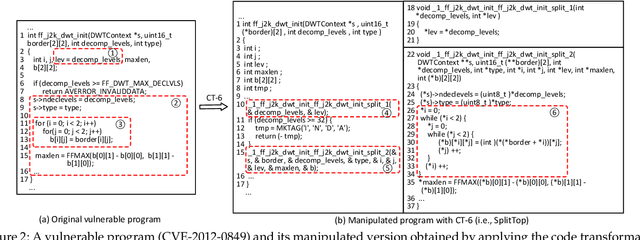
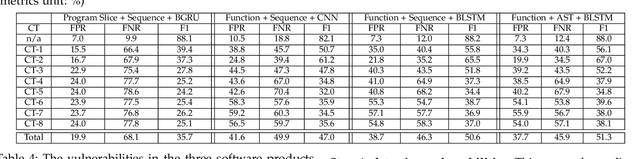
Automatically detecting software vulnerabilities in source code is an important problem that has attracted much attention. In particular, deep learning-based vulnerability detectors, or DL-based detectors, are attractive because they do not need human experts to define features or patterns of vulnerabilities. However, such detectors' robustness is unclear. In this paper, we initiate the study in this aspect by demonstrating that DL-based detectors are not robust against simple code transformations, dubbed attacks in this paper, as these transformations may be leveraged for malicious purposes. As a first step towards making DL-based detectors robust against such attacks, we propose an innovative framework, dubbed ZigZag, which is centered at (i) decoupling feature learning and classifier learning and (ii) using a ZigZag-style strategy to iteratively refine them until they converge to robust features and robust classifiers. Experimental results show that the ZigZag framework can substantially improve the robustness of DL-based detectors.
SoK: Arms Race in Adversarial Malware Detection
Jun 15, 2020
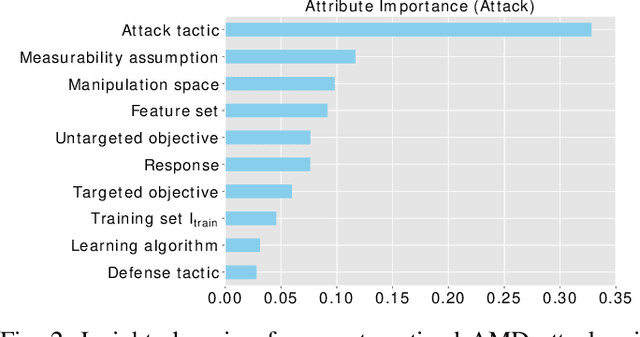
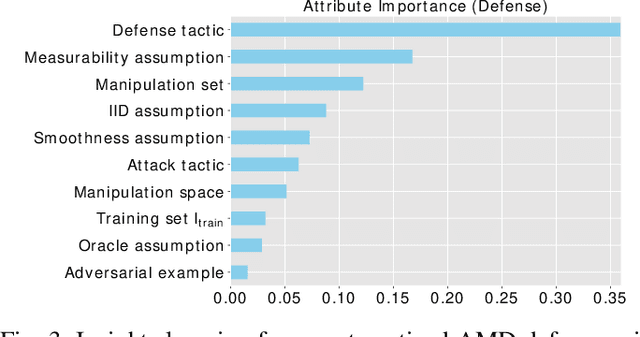
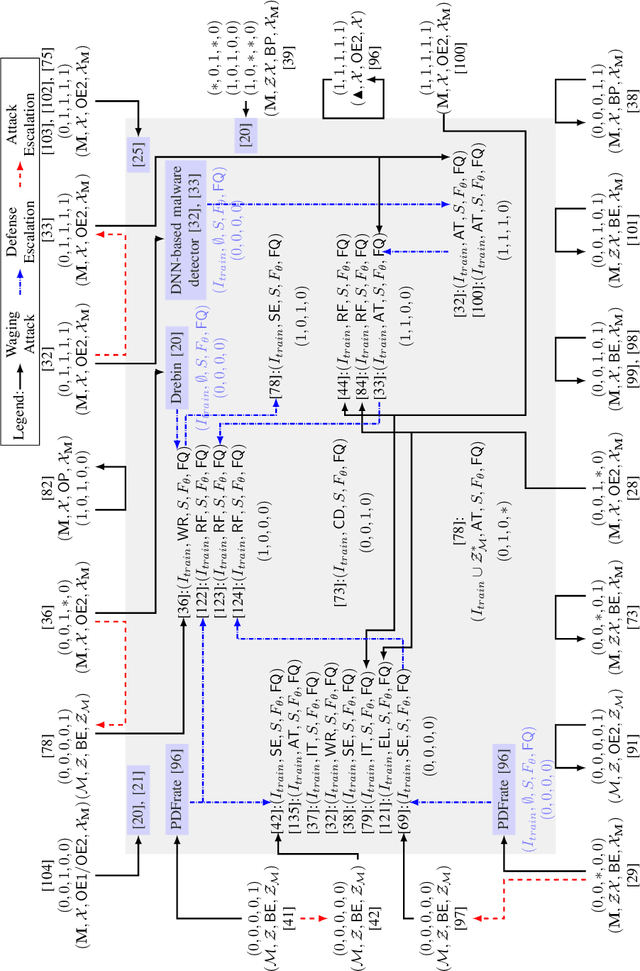
Malicious software (malware) is a major cyber threat that shall be tackled with Machine Learning (ML) techniques because millions of new malware examples are injected into cyberspace on a daily basis. However, ML is known to be vulnerable to attacks known as adversarial examples. In this SoK paper, we systematize the field of Adversarial Malware Detection (AMD) through the lens of a unified framework of assumptions, attacks, defenses and security properties. This not only guides us to map attacks and defenses into some partial order structures, but also allows us to clearly describe the attack-defense arms race in the AMD context. In addition to manually drawing insights, we also propose using ML to draw insights from the systematized representation of the literature. Examples of the insights are: knowing the defender's feature set is critical to the attacker's success; attack tactic (as a core part of the threat model) largely determines what security property of a malware detector can be broke; there is currently no silver bullet defense against evasion attacks or poisoning attacks; defense tactic largely determines what security properties can be achieved by a malware detector; knowing attacker's manipulation set is critical to defender's success; ML is an effective method for insights learning in SoK studies. These insights shed light on future research directions.
Enhancing Deep Neural Networks Against Adversarial Malware Examples
Apr 15, 2020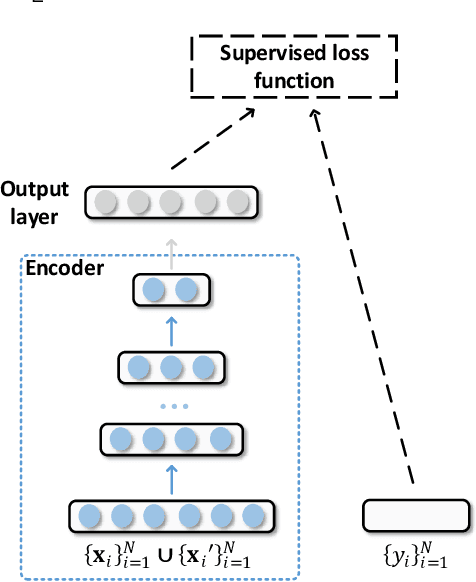
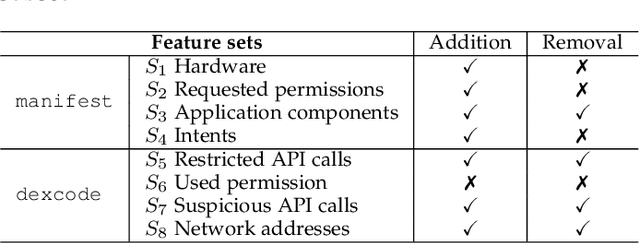
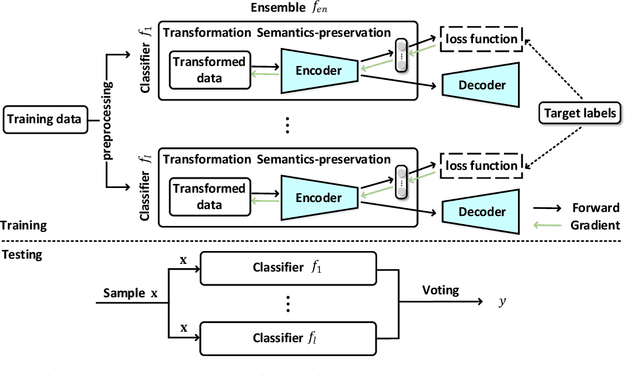
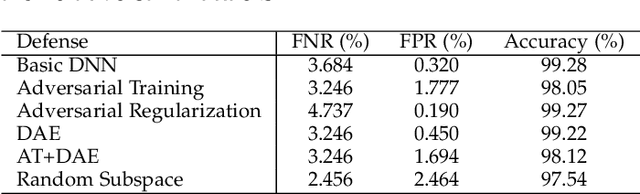
Machine learning based malware detection is known to be vulnerable to adversarial evasion attacks. The state-of-the-art is that there are no effective countermeasures against these attacks. Inspired by the AICS'2019 Challenge organized by the MIT Lincoln Lab, we systematize a number of principles for enhancing the robustness of neural networks against adversarial malware evasion attacks. Some of these principles have been scattered in the literature, but others are proposed in this paper for the first time. Under the guidance of these principles, we propose a framework for defending against adversarial malware evasion attacks. We validated the framework using the Drebin dataset of Android malware. We applied the defense framework to the AICS'2019 Challenge and won, without knowing how the organizers generated the adversarial examples. However, we see a ~22\% difference between the accuracy in the experiment with the Drebin dataset (for binary classification) and the accuracy in the experiment with respect to the AICS'2019 Challenge (for multiclass classification). We attribute this gap to a fundamental barrier that without knowing the attacker's manipulation set, the defender cannot do effective Adversarial Training.
$μ$VulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection
Jan 08, 2020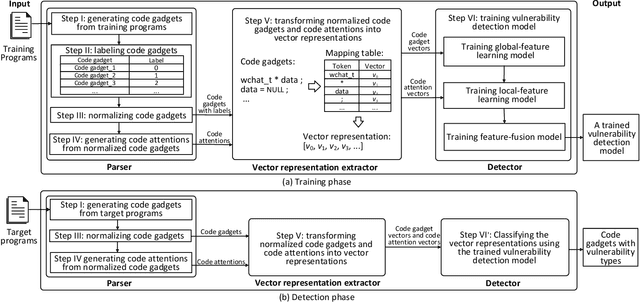
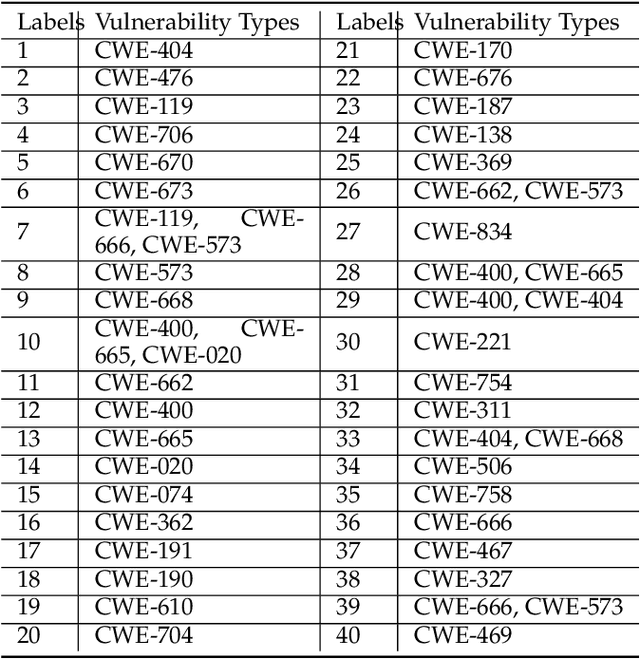
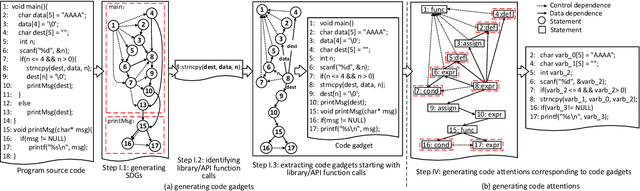
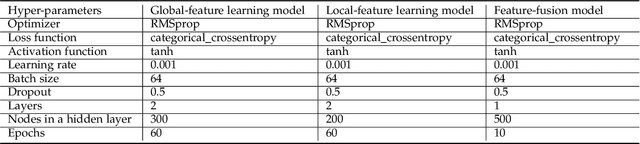
Fine-grained software vulnerability detection is an important and challenging problem. Ideally, a detection system (or detector) not only should be able to detect whether or not a program contains vulnerabilities, but also should be able to pinpoint the type of a vulnerability in question. Existing vulnerability detection methods based on deep learning can detect the presence of vulnerabilities (i.e., addressing the binary classification or detection problem), but cannot pinpoint types of vulnerabilities (i.e., incapable of addressing multiclass classification). In this paper, we propose the first deep learning-based system for multiclass vulnerability detection, dubbed $\mu$VulDeePecker. The key insight underlying $\mu$VulDeePecker is the concept of code attention, which can capture information that can help pinpoint types of vulnerabilities, even when the samples are small. For this purpose, we create a dataset from scratch and use it to evaluate the effectiveness of $\mu$VulDeePecker. Experimental results show that $\mu$VulDeePecker is effective for multiclass vulnerability detection and that accommodating control-dependence (other than data-dependence) can lead to higher detection capabilities.
Election with Bribed Voter Uncertainty: Hardness and Approximation Algorithm
Nov 07, 2018
Bribery in election (or computational social choice in general) is an important problem that has received a considerable amount of attention. In the classic bribery problem, the briber (or attacker) bribes some voters in attempting to make the briber's designated candidate win an election. In this paper, we introduce a novel variant of the bribery problem, "Election with Bribed Voter Uncertainty" or BVU for short, accommodating the uncertainty that the vote of a bribed voter may or may not be counted. This uncertainty occurs either because a bribed voter may not cast its vote in fear of being caught, or because a bribed voter is indeed caught and therefore its vote is discarded. As a first step towards ultimately understanding and addressing this important problem, we show that it does not admit any multiplicative $O(1)$-approximation algorithm modulo standard complexity assumptions. We further show that there is an approximation algorithm that returns a solution with an additive-$\epsilon$ error in FPT time for any fixed $\epsilon$.
Statistical Estimation of Malware Detection Metrics in the Absence of Ground Truth
Sep 24, 2018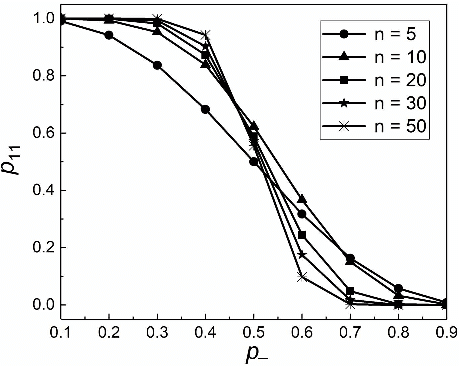
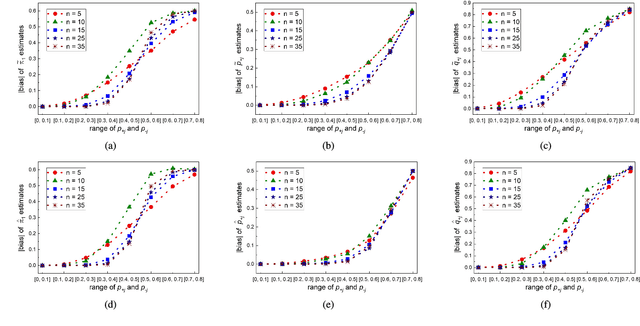
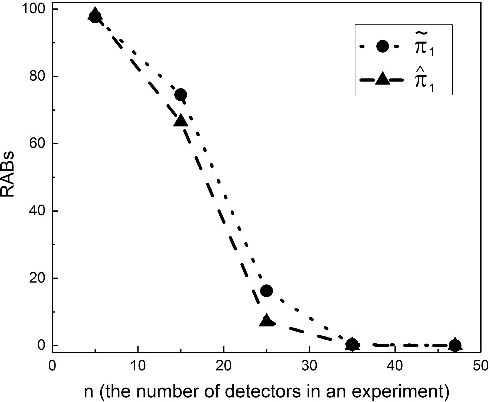
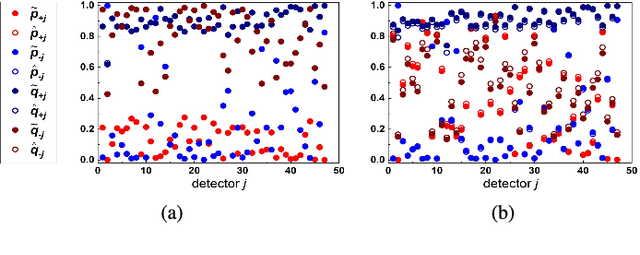
The accurate measurement of security metrics is a critical research problem because an improper or inaccurate measurement process can ruin the usefulness of the metrics, no matter how well they are defined. This is a highly challenging problem particularly when the ground truth is unknown or noisy. In contrast to the well perceived importance of defining security metrics, the measurement of security metrics has been little understood in the literature. In this paper, we measure five malware detection metrics in the {\em absence} of ground truth, which is a realistic setting that imposes many technical challenges. The ultimate goal is to develop principled, automated methods for measuring these metrics at the maximum accuracy possible. The problem naturally calls for investigations into statistical estimators by casting the measurement problem as a {\em statistical estimation} problem. We propose statistical estimators for these five malware detection metrics. By investigating the statistical properties of these estimators, we are able to characterize when the estimators are accurate, and what adjustments can be made to improve them under what circumstances. We use synthetic data with known ground truth to validate these statistical estimators. Then, we employ these estimators to measure five metrics with respect to a large dataset collected from VirusTotal. We believe our study touches upon a vital problem that has not been paid due attention and will inspire many future investigations.