 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Federated Learning in Unreliable Wireless Networks: A Client Selection Approach
Feb 26, 2025Federated learning (FL) has emerged as a promising distributed learning paradigm for training deep neural networks (DNNs) at the wireless edge, but its performance can be severely hindered by unreliable wireless transmission and inherent data heterogeneity among clients. Existing solutions primarily address these challenges by incorporating wireless resource optimization strategies, often focusing on uplink resource allocation across clients under the assumption of homogeneous client-server network standards. However, these approaches overlooked the fact that mobile clients may connect to the server via diverse network standards (e.g., 4G, 5G, Wi-Fi) with customized configurations, limiting the flexibility of server-side modifications and restricting applicability in real-world commercial networks. This paper presents a novel theoretical analysis about how transmission failures in unreliable networks distort the effective label distributions of local samples, causing deviations from the global data distribution and introducing convergence bias in FL. Our analysis reveals that a carefully designed client selection strategy can mitigate biases induced by network unreliability and data heterogeneity. Motivated by this insight, we propose FedCote, a client selection approach that optimizes client selection probabilities without relying on wireless resource scheduling. Experimental results demonstrate the robustness of FedCote in DNN-based classification tasks under unreliable networks with frequent transmission failures.
Symmetrical Joint Learning Support-query Prototypes for Few-shot Segmentation
Jul 27, 2024



We propose Sym-Net, a novel framework for Few-Shot Segmentation (FSS) that addresses the critical issue of intra-class variation by jointly learning both query and support prototypes in a symmetrical manner. Unlike previous methods that generate query prototypes solely by matching query features to support prototypes, which is a form of bias learning towards the few-shot support samples, Sym-Net leverages a balanced symmetrical learning approach for both query and support prototypes, ensuring that the learning process does not favor one set (support or query) over the other. One of main modules of Sym-Net is the visual-text alignment-based prototype aggregation module, which is not just query-guided prototype refinement, it is a jointly learning from both support and query samples, which makes the model beneficial for handling intra-class discrepancies and allows it to generalize better to new, unseen classes. Specifically, a parameter-free prior mask generation module is designed to accurately localize both local and global regions of the query object by using sliding windows of different sizes and a self-activation kernel to suppress incorrect background matches. Additionally, to address the information loss caused by spatial pooling during prototype learning, a top-down hyper-correlation module is integrated to capture multi-scale spatial relationships between support and query images. This approach is further jointly optimized by implementing a co-optimized hard triplet mining strategy. Experimental results show that the proposed Sym-Net outperforms state-of-the-art models, which demonstrates that jointly learning support-query prototypes in a symmetrical manner for FSS offers a promising direction to enhance segmentation performance with limited annotated data.
Fluid Antenna for Mobile Edge Computing
Mar 18, 2024



In the evolving environment of mobile edge computing (MEC), optimizing system performance to meet the growing demand for low-latency computing services is a top priority. Integrating fluidic antenna (FA) technology into MEC networks provides a new approach to address this challenge. This letter proposes an FA-enabled MEC scheme that aims to minimize the total system delay by leveraging the mobility of FA to enhance channel conditions and improve computational offloading efficiency. By establishing an optimization problem focusing on the joint optimization of computation offloading and antenna positioning, we introduce an alternating iterative algorithm based on the interior point method and particle swarm optimization (IPPSO). Numerical results demonstrate the advantages of our proposed scheme compared to traditional fixed antenna positions, showing significant improvements in transmission rates and reductions in delays. The proposed IPPSO algorithm exhibits robust convergence properties, further validating the effectiveness of our method.
PAD: Towards Principled Adversarial Malware Detection Against Evasion Attacks
Feb 22, 2023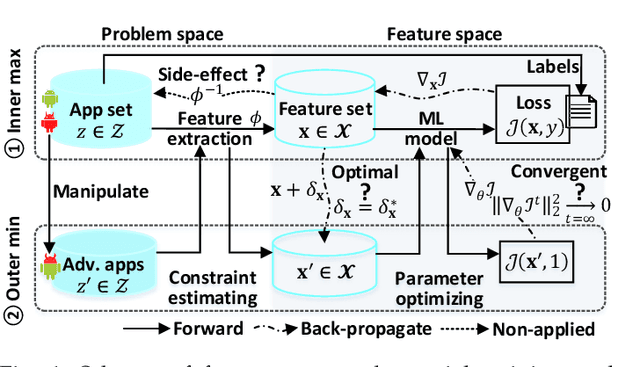
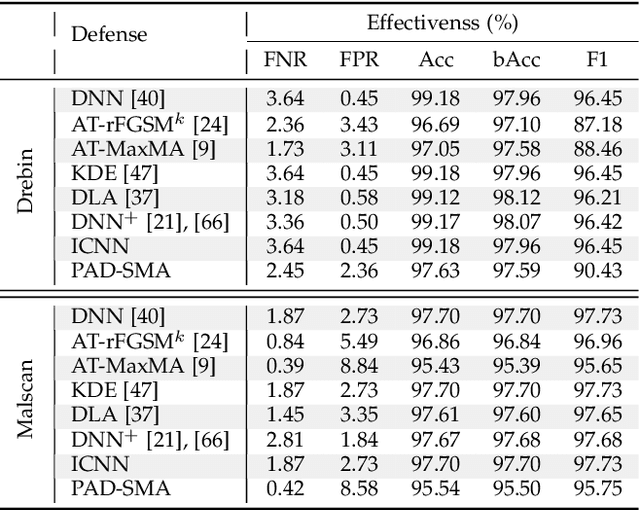
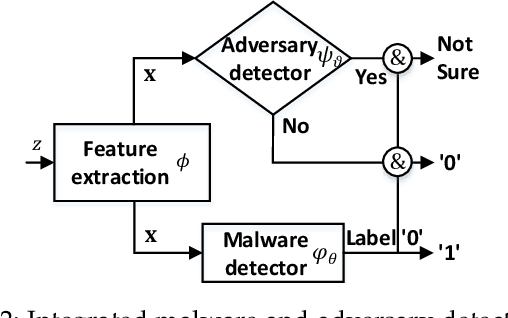
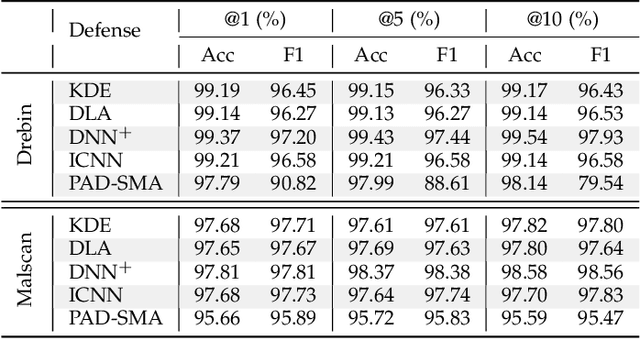
Machine Learning (ML) techniques facilitate automating malicious software (malware for short) detection, but suffer from evasion attacks. Many researchers counter such attacks in heuristic manners short of both theoretical guarantees and defense effectiveness. We hence propose a new adversarial training framework, termed Principled Adversarial Malware Detection (PAD), which encourages convergence guarantees for robust optimization methods. PAD lays on a learnable convex measurement that quantifies distribution-wise discrete perturbations and protects the malware detector from adversaries, by which for smooth detectors, adversarial training can be performed heuristically with theoretical treatments. To promote defense effectiveness, we propose a new mixture of attacks to instantiate PAD for enhancing the deep neural network-based measurement and malware detector. Experimental results on two Android malware datasets demonstrate: (i) the proposed method significantly outperforms the state-of-the-art defenses; (ii) it can harden the ML-based malware detection against 27 evasion attacks with detection accuracies greater than 83.45%, while suffering an accuracy decrease smaller than 2.16% in the absence of attacks; (iii) it matches or outperforms many anti-malware scanners in VirusTotal service against realistic adversarial malware.
Dite-HRNet: Dynamic Lightweight High-Resolution Network for Human Pose Estimation
Apr 22, 2022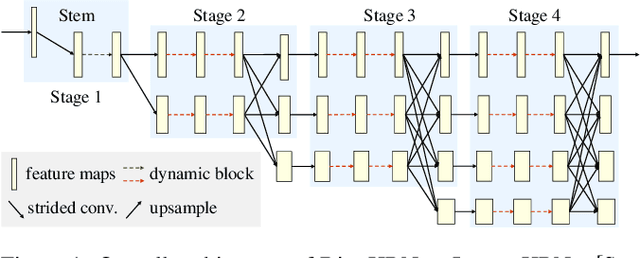
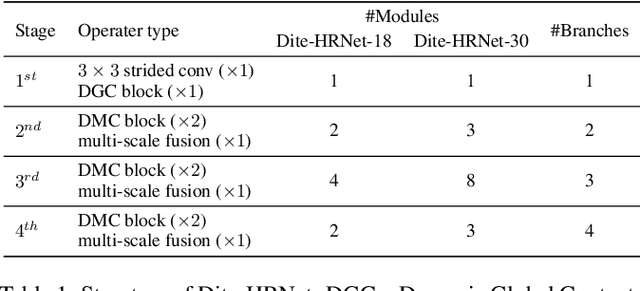
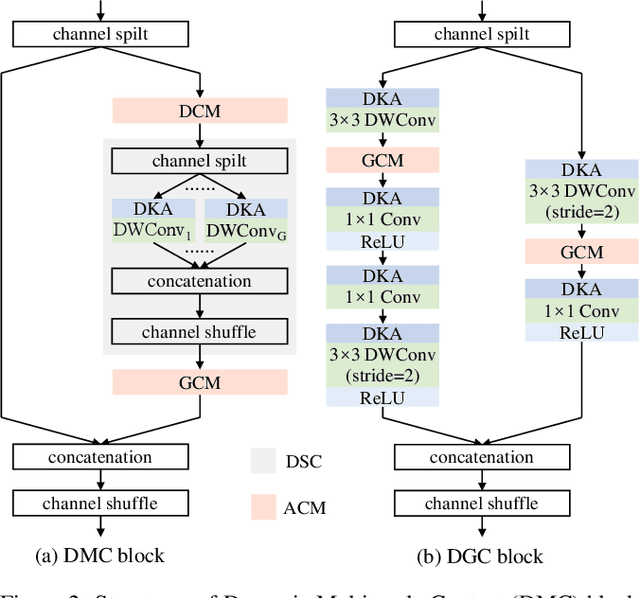
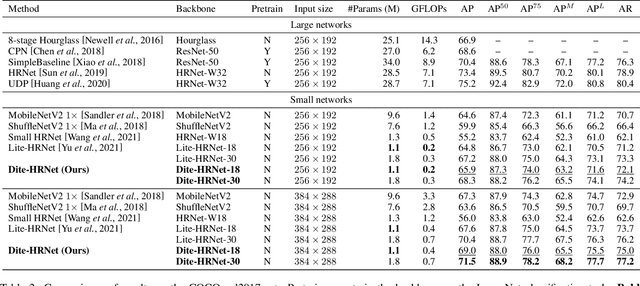
A high-resolution network exhibits remarkable capability in extracting multi-scale features for human pose estimation, but fails to capture long-range interactions between joints and has high computational complexity. To address these problems, we present a Dynamic lightweight High-Resolution Network (Dite-HRNet), which can efficiently extract multi-scale contextual information and model long-range spatial dependency for human pose estimation. Specifically, we propose two methods, dynamic split convolution and adaptive context modeling, and embed them into two novel lightweight blocks, which are named dynamic multi-scale context block and dynamic global context block. These two blocks, as the basic component units of our Dite-HRNet, are specially designed for the high-resolution networks to make full use of the parallel multi-resolution architecture. Experimental results show that the proposed network achieves superior performance on both COCO and MPII human pose estimation datasets, surpassing the state-of-the-art lightweight networks. Code is available at: \url{https://github.com/ZiyiZhang27/Dite-HRNet}.
Classification and Recognition of Encrypted EEG Data Neural Network
Jun 15, 2020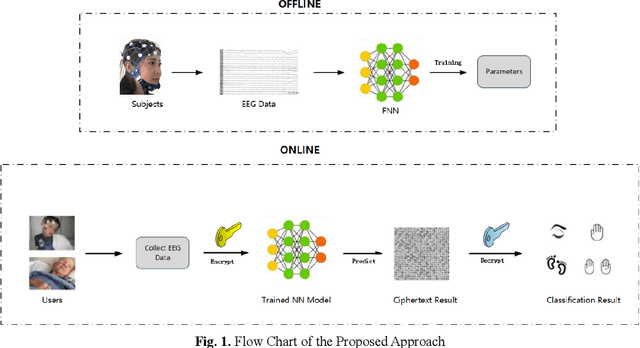

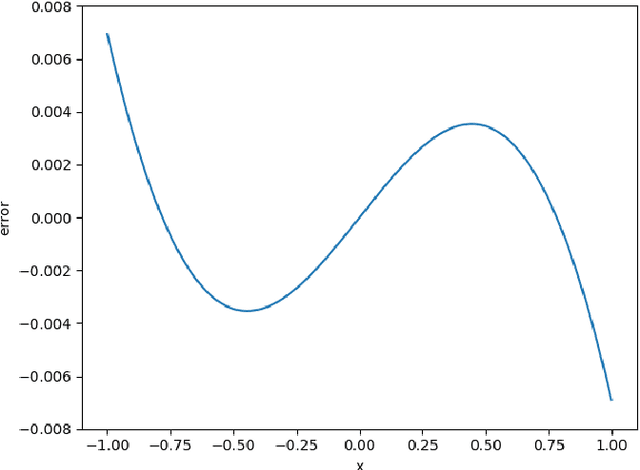
With the rapid development of Machine Learning technology applied in electroencephalography (EEG) signals, Brain-Computer Interface (BCI) has emerged as a novel and convenient human-computer interaction for smart home, intelligent medical and other Internet of Things (IoT) scenarios. However, security issues such as sensitive information disclosure and unauthorized operations have not received sufficient concerns. There are still some defects with the existing solutions to encrypted EEG data such as low accuracy, high time complexity or slow processing speed. For this reason, a classification and recognition method of encrypted EEG data based on neural network is proposed, which adopts Paillier encryption algorithm to encrypt EEG data and meanwhile resolves the problem of floating point operations. In addition, it improves traditional feed-forward neural network (FNN) by using the approximate function instead of activation function and realizes multi-classification of encrypted EEG data. Extensive experiments are conducted to explore the effect of several metrics (such as the hidden neuron size and the learning rate updated by improved simulated annealing algorithm) on the recognition results. Followed by security and time cost analysis, the proposed model and approach are validated and evaluated on public EEG datasets provided by PhysioNet, BCI Competition IV and EPILEPSIAE. The experimental results show that our proposal has the satisfactory accuracy, efficiency and feasibility compared with other solutions.
Deep Semantic Multimodal Hashing Network for Scalable Multimedia Retrieval
Jan 09, 2019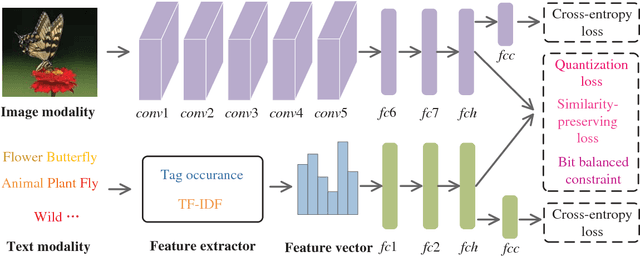
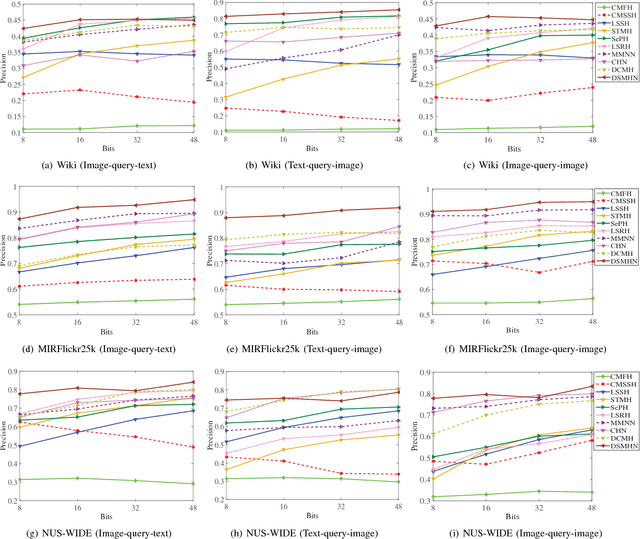
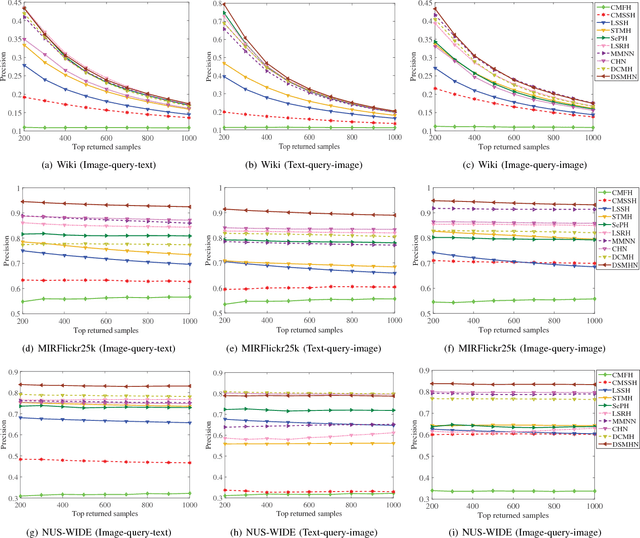
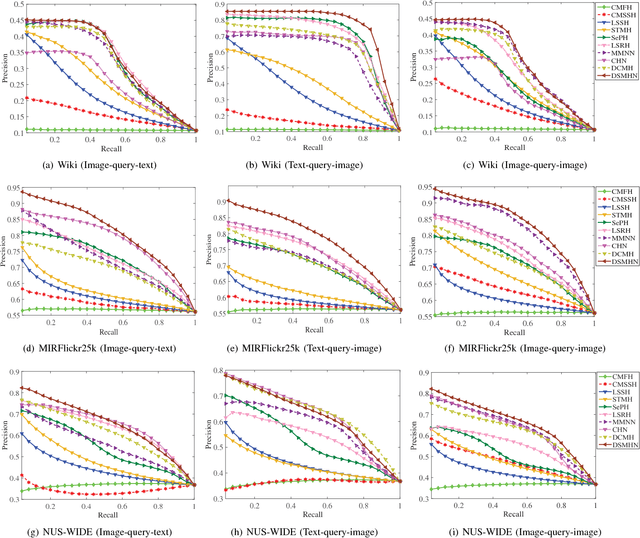
Hashing has been widely applied to multimodal retrieval on large-scale multimedia data due to its efficiency in computation and storage. Particularly, deep hashing has received unprecedented research attention in recent years, owing to its perfect retrieval performance. However, most of existing deep hashing methods learn binary hash codes by preserving the similarity relationship while without exploiting the semantic labels, which result in suboptimal binary codes. In this work, we propose a novel Deep Semantic Multimodal Hashing Network (DSMHN) for scalable multimodal retrieval. In DSMHN, two sets of modality-specific hash functions are jointly learned by explicitly preserving both the inter-modality similarities and the intra-modality semantic labels. Specifically, with the assumption that the learned hash codes should be optimal for task-specific classification, two stream networks are jointly trained to learn the hash functions by embedding the semantic labels on the resultant hash codes. Different from previous deep hashing methods, which are tied to some particular forms of loss functions, our deep hashing framework can be flexibly integrated with different types of loss functions. In addition, the bit balance property is investigated to generate binary codes with each bit having $50\%$ probability to be $1$ or $-1$. Moreover, a unified deep multimodal hashing framework is proposed to learn compact and high-quality hash codes by exploiting the feature representation learning, inter-modality similarity preserving learning, semantic label preserving learning and hash functions learning with bit balanced constraint simultaneously. We conduct extensive experiments for both unimodal and cross-modal retrieval tasks on three widely-used multimodal retrieval datasets. The experimental result demonstrates that DSMHN significantly outperforms state-of-the-art methods.