 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centric Topic Modeling with Goal-Prompted Contrastive Learning and Optimal Transport
Apr 14, 2026Existing topic modeling methods, from LDA to recent neural and LLM-based approaches, which focus mainly on statistical coherence, often produce redundant or off-target topics that miss the user's underlying intent. We introduce Human-centric Topic Modeling, \emph{Human-TM}), a novel task formulation that integrates a human-provided goal directly into the topic modeling process to produce interpretable, diverse and goal-oriented topics. To tackle this challenge, we propose the \textbf{G}oal-prompted \textbf{C}ontrastive \textbf{T}opic \textbf{M}odel with \textbf{O}ptimal \textbf{T}ransport (GCTM-OT), which first uses LLM-based prompting to extract goal candidates from documents, then incorporates these into semantic-aware contrastive learning via optimal transport for topic discovery. Experimental results on three public subreddit datasets show that GCTM-OT outperforms state-of-the-art baselines in topic coherence and diversity while significantly improving alignment with human-provided goals, paving the way for more human-centric topic discovery systems.
Freezing chaos without synaptic plasticity
Mar 11, 2025Chaos is ubiquitous in high-dimensional neural dynamics. A strong chaotic fluctuation may be harmful to information processing. A traditional way to mitigate this issue is to introduce Hebbian plasticity, which can stabilize the dynamics. Here, we introduce another distinct way without synaptic plasticity. An Onsager reaction term due to the feedback of the neuron itself is added to the vanilla recurrent dynamics, making the driving force a gradient form. The original unstable fixed points supporting the chaotic fluctuation can then be approached by further decreasing the kinetic energy of the dynamics. We show that this freezing effect also holds in more biologically realistic networks, such as those composed of excitatory and inhibitory neurons. The gradient dynamics are also useful for computational tasks such as recalling or predicting external time-dependent stimuli.
PEP-GS: Perceptually-Enhanced Precise Structured 3D Gaussians for View-Adaptive Rendering
Nov 08, 2024
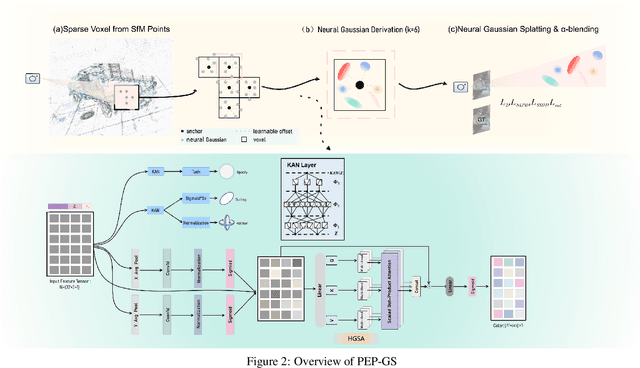
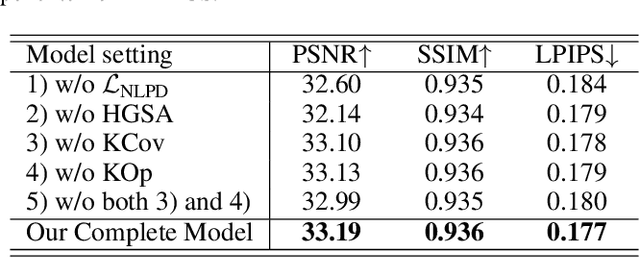
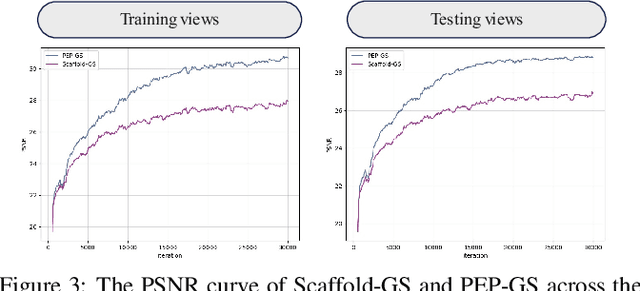
Recent advances in structured 3D Gaussians for view-adaptive rendering, particularly through methods like Scaffold-GS, have demonstrated promising results in neural scene representation. However, existing approaches still face challenges in perceptual consistency and precise view-dependent effects. We present PEP-GS, a novel framework that enhances structured 3D Gaussians through three key innovations: (1) a Local-Enhanced Multi-head Self-Attention (LEMSA) mechanism that replaces spherical harmonics for more accurate view-dependent color decoding, and (2) Kolmogorov-Arnold Networks (KAN) that optimize Gaussian opacity and covariance functions for enhanced interpretability and splatting precision. (3) a Neural Laplacian Pyramid Decomposition (NLPD) that improves perceptual similarity across views. Our comprehensive evaluation across multiple datasets indicates that, compared to the current state-of-the-art methods, these improvements are particularly evident in challenging scenarios such as view-dependent effects, specular reflections, fine-scale details and false geometry generation.
How high dimensional neural dynamics are confined in phase space
Oct 25, 2024High dimensional dynamics play a vital role in brain function, ecological systems, and neuro-inspired machine learning. Where and how these dynamics are confined in the phase space remains challenging to solve. Here, we provide an analytic argument that the confinement region is an M-shape when the neural dynamics show a diversity, with two sharp boundaries and a flat low-density region in between. Despite increasing synaptic strengths in a neural circuit, the shape remains qualitatively the same, while the left boundary is continuously pushed away. However, in deep chaotic regions, an arch-shaped confinement gradually emerges. Our theory is supported by numerical simulations on finite-sized networks. This analytic theory opens up a geometric route towards addressing fundamental questions about high dimensional non-equilibrium dynamics.
Spin glass model of in-context learning
Aug 05, 2024Large language models show a surprising in-context learning ability -- being able to use a prompt to form a prediction for a query, yet without additional training, in stark contrast to old-fashioned supervised learning. Providing a mechanistic interpretation and linking the empirical phenomenon to physics are thus challenging and remain unsolved. We study a simple yet expressive transformer with linear attention, and map this structure to a spin glass model with real-valued spins, where the couplings and fields explain the intrinsic disorder in data. The spin glass model explains how the weight parameters interact with each other during pre-training, and most importantly why an unseen function can be predicted by providing only a prompt yet without training. Our theory reveals that for single instance learning, increasing the task diversity leads to the emergence of the in-context learning, by allowing the Boltzmann distribution to converge to a unique correct solution of weight parameters. Therefore the pre-trained transformer displays a prediction power in a novel prompt setting. The proposed spin glass model thus establishes a foundation to understand the empirical success of large language models.
Nonequilbrium physics of generative diffusion models
May 20, 2024
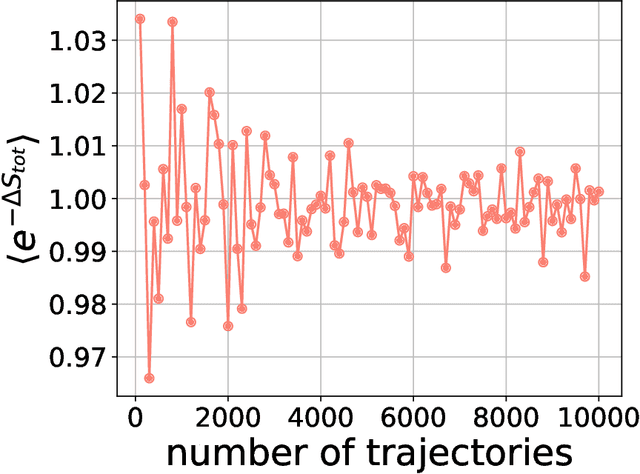
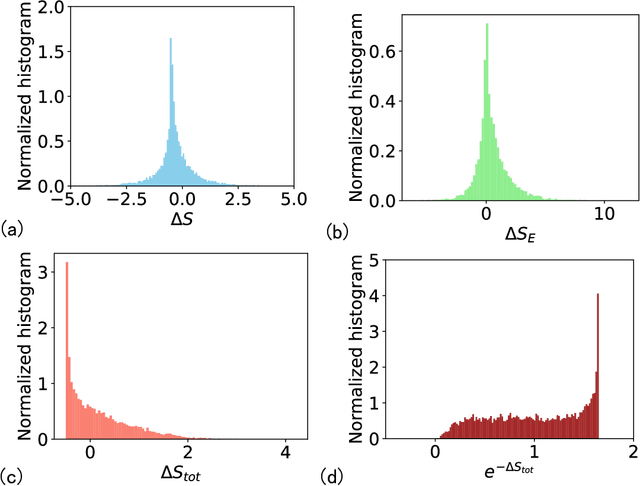
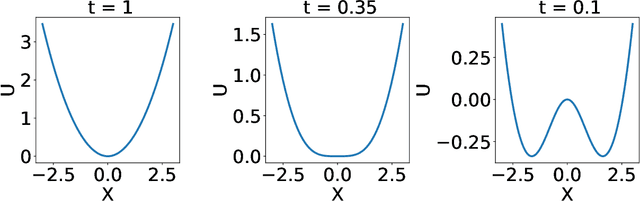
Generative diffusion models apply the concept of Langevin dynamics in physics to machine leaning, attracting a lot of interest from industrial application, but a complete picture about inherent mechanisms is still lacking. In this paper, we provide a transparent physics analysis of the diffusion models, deriving the fluctuation theorem, entropy production, Franz-Parisi potential to understand the intrinsic phase transitions discovered recently. Our analysis is rooted in non-equlibrium physics and concepts from equilibrium physics, i.e., treating both forward and backward dynamics as a Langevin dynamics, and treating the reverse diffusion generative process as a statistical inference, where the time-dependent state variables serve as quenched disorder studied in spin glass theory. This unified principle is expected to guide machine learning practitioners to design better algorithms and theoretical physicists to link the machine learning to non-equilibrium thermodynamics.
Fermi-Bose Machine
Apr 21, 2024



Distinct from human cognitive processing, deep neural networks trained by backpropagation can be easily fooled by adversarial examples. To design a semantically meaningful representation learning, we discard backpropagation, and instead, propose a local contrastive learning, where the representation for the inputs bearing the same label shrink (akin to boson) in hidden layers, while those of different labels repel (akin to fermion). This layer-wise learning is local in nature, being biological plausible. A statistical mechanics analysis shows that the target fermion-pair-distance is a key parameter. Moreover, the application of this local contrastive learning to MNIST benchmark dataset demonstrates that the adversarial vulnerability of standard perceptron can be greatly mitigated by tuning the target distance, i.e., controlling the geometric separation of prototype manifolds.
Enhanced Short Text Modeling: Leveraging Large Language Models for Topic Refinement
Mar 26, 2024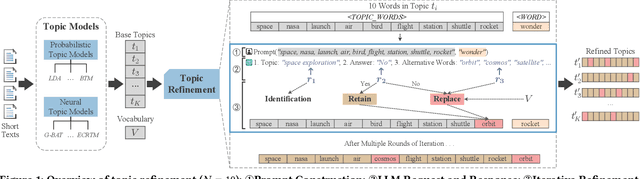



Crafting effective topic models for brief texts, like tweets and news headlines, is essential for capturing the swift shifts in social dynamics. Traditional topic models, however, often fall short in accurately representing the semantic intricacies of short texts due to their brevity and lack of contextual data. In our study, we harness the advanced capabilities of Large Language Models (LLMs) to introduce a novel approach termed "Topic Refinement". This approach does not directly involve itself in the initial modeling of topics but focuses on improving topics after they have been mined. By employing prompt engineering, we direct LLMs to eliminate off-topic words within a given topic, ensuring that only contextually relevant words are preserved or substituted with ones that fit better semantically. This method emulates human-like scrutiny and improvement of topics, thereby elevating the semantic quality of the topics generated by various models. Our comprehensive evaluation across three unique datasets has shown that our topic refinement approach significantly enhances the semantic coherence of topics.
An optimization-based equilibrium measure describes non-equilibrium steady state dynamics: application to edge of chaos
Jan 18, 2024



Understanding neural dynamics is a central topic in machine learning, non-linear physics and neuroscience. However, the dynamics is non-linear, stochastic and particularly non-gradient, i.e., the driving force can not be written as gradient of a potential. These features make analytic studies very challenging. The common tool is to use path integral approach or dynamical mean-field theory, but the drawback is one has to solve the integro-differential or dynamical mean-field equations, which is computationally expensive and has no closed form solutions in general. From the aspect of associated Fokker-Planck equation, the steady state solution is generally unknown. Here, we treat searching for the steady state as an optimization problem, and construct an approximate potential closely related to the speed of the dynamics, and find that searching for the ground state of this potential is equivalent to running a stochastic gradient dynamics. The resultant stationary state follows exactly the canonical Boltzmann measure. Within this framework, the quenched disorder intrinsic in the neural networks can be averaged out by applying the replica method. Our theory reproduces the well-known result of edge-of-chaos, and further the order parameters characterizing the continuous transition are derived, and different scaling behavior with respect to inverse temperature in both sides of the transition is also revealed. Our method opens the door to analytically study the steady state landscape of the deterministic or stochastic high dimensional dynamics.
Spiking mode-based neural networks
Oct 23, 2023



Spiking neural networks play an important role in brain-like neuromorphic computations and in studying working mechanisms of neural circuits. One drawback of training a large scale spiking neural network is that an expensive cost of updating all weights is required. Furthermore, after training, all information related to the computational task is hidden into the weight matrix, prohibiting us from a transparent understanding of circuit mechanisms. Therefore, in this work, we address these challenges by proposing a spiking mode-based training protocol. The first advantage is that the weight is interpreted by input and output modes and their associated scores characterizing importance of each decomposition term. The number of modes is thus adjustable, allowing more degrees of freedom for modeling the experimental data. This reduces a sizable training cost because of significantly reduced space complexity for learning. The second advantage is that one can project the high dimensional neural activity in the ambient space onto the mode space which is typically of a low dimension, e.g., a few modes are sufficient to capture the shape of the underlying neural manifolds. We analyze our framework in two computational tasks -- digit classification and selective sensory integration tasks. Our work thus derives a mode-based learning rule for spiking neural networks.