 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta predictive learning model of natural languages
Sep 08, 2023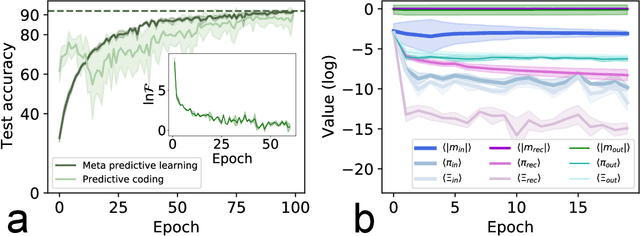
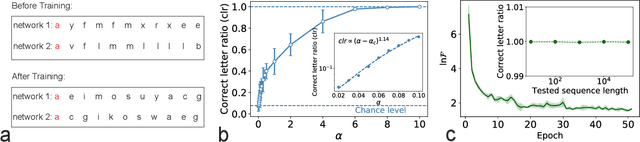
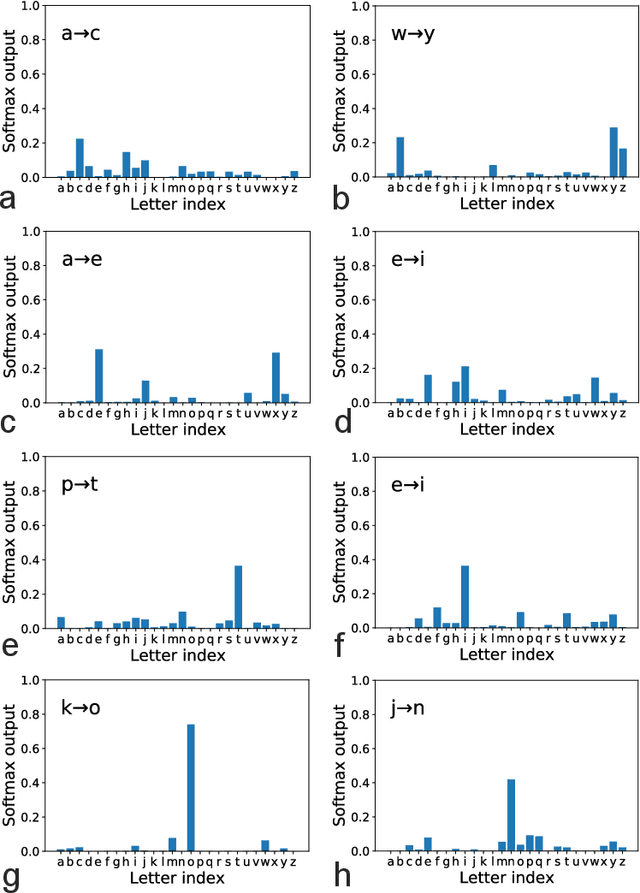
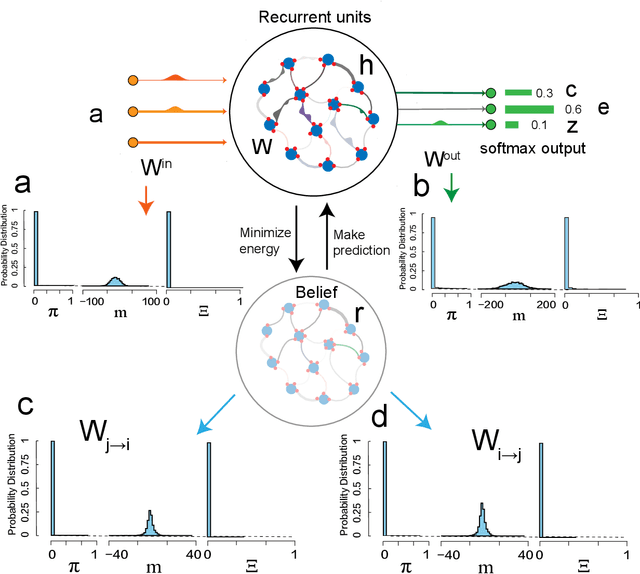
Large language models based on self-attention mechanisms have achieved astonishing performances not only in natural language itself, but also in a variety of tasks of different nature. However, regarding processing language, our human brain may not operate using the same principle. Then, a debate is established on the connection between brain computation and artificial self-supervision adopted in large language models. One of most influential hypothesis in brain computation is the predictive coding framework, which proposes to minimize the prediction error by local learning. However, the role of predictive coding and the associated credit assignment in language processing remains unknown. Here, we propose a mean-field learning model within the predictive coding framework, assuming that the synaptic weight of each connection follows a spike and slab distribution, and only the distribution is trained. This meta predictive learning is successfully validated on classifying handwritten digits where pixels are input to the network in sequence, and on the toy and real language corpus. Our model reveals that most of the connections become deterministic after learning, while the output connections have a higher level of variability. The performance of the resulting network ensemble changes continuously with data load, further improving with more training data, in analogy with the emergent behavior of large language models. Therefore, our model provides a starting point to investigate the physics and biology correspondences of the language processing and the unexpected general intelligence.
Statistical mechanics of continual learning: variational principle and mean-field potential
Dec 07, 2022An obstacle to artificial general intelligence is set by the continual learning of multiple tasks of different nature. Recently, various heuristic tricks, both from machine learning and from neuroscience angles, were proposed, but they lack a unified theory ground. Here, we focus on the continual learning in single-layered and multi-layered neural networks of binary weights. A variational Bayesian learning setting is thus proposed, where the neural network is trained in a field-space, rather than the gradient-ill-defined discrete-weight space, and furthermore, the weight uncertainty is naturally incorporated, and modulates the synaptic resources among tasks. From a physics perspective, we translate the variational continual learning into the Franz-Parisi thermodynamic potential framework, where the previous task knowledge acts as a prior and a reference as well. Therefore, the learning performance can be analytically studied with mean-field order parameters, whose predictions coincide with the numerical experiments using stochastic gradient descent methods. Our proposed principled frameworks also connect to elastic weight consolidation, and neuroscience inspired metaplasticity, providing a theory-grounded method for the real-world multi-task learning with deep networks.
Emergence of hierarchical modes from deep learning
Aug 21, 2022


Large-scale deep neural networks consume expensive training costs, but the training results in less-interpretable weight matrices constructing the networks. Here, we propose a mode decomposition learning that can interpret the weight matrices as a hierarchy of latent modes. These modes are akin to patterns in physics studies of memory networks. The mode decomposition learning not only saves a significant large amount of training costs, but also explains the network performance with the leading modes. The mode learning scheme shows a progressively compact latent space across the network hierarchy, and the least number of modes increases only logarithmically with the network width. Our mode decomposition learning is also studied in an analytic on-line learning setting, which reveals multi-stage of learning dynamics. Therefore, the proposed mode decomposition learning points to a cheap and interpretable route towards the magical deep learning.
Ensemble perspective for understanding temporal credit assignment
Feb 07, 2021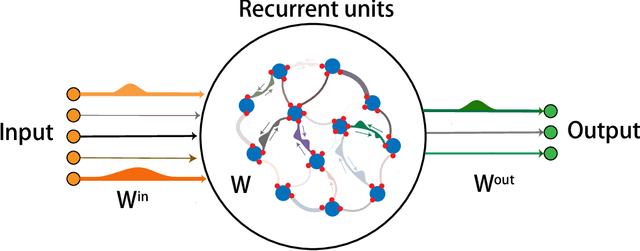
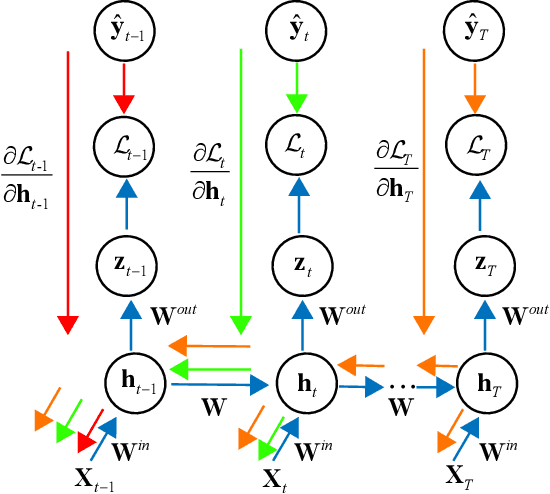
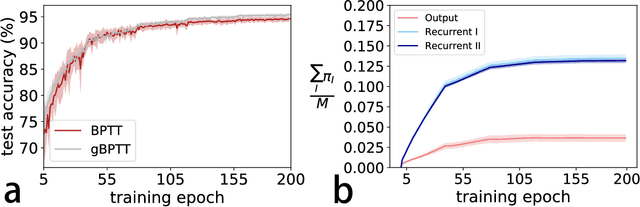
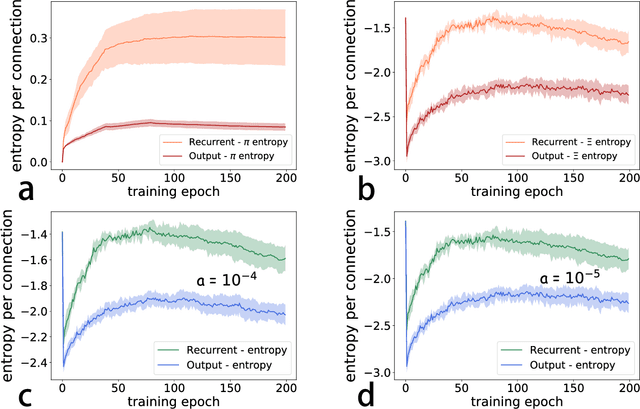
Recurrent neural networks are widely used for modeling spatio-temporal sequences in both nature language processing and neural population dynamics. However, understanding the temporal credit assignment is hard. Here, we propose that each individual connection in the recurrent computation is modeled by a spike and slab distribution, rather than a precise weight value. We then derive the mean-field algorithm to train the network at the ensemble level. The method is then applied to classify handwritten digits when pixels are read in sequence, and to the multisensory integration task that is a fundamental cognitive function of animals. Our model reveals important connections that determine the overall performance of the network. The model also shows how spatio-temporal information is processed through the hyperparameters of the distribution, and moreover reveals distinct types of emergent neural selectivity. It is thus promising to study the temporal credit assignment in recurrent neural networks from the ensemble perspective.
Learning credit assignment
Jan 10, 2020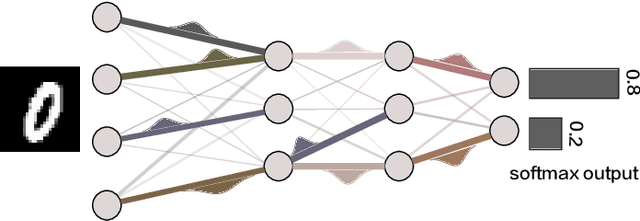
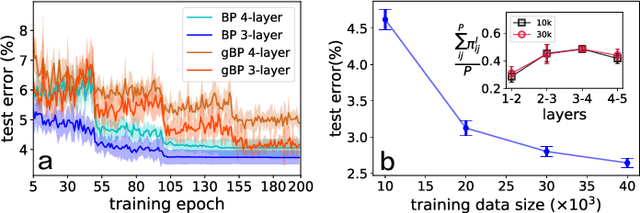
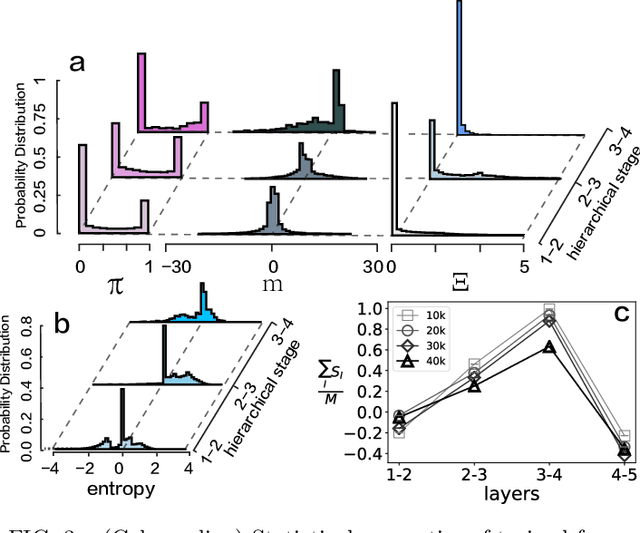
Deep learning has achieved impressive prediction accuracies in a variety of scientific and industrial domains. However, the nested non-linear feature of deep learning makes the learning highly non-transparent, i.e., it is still unknown how the learning coordinates a huge number of parameters to achieve a decision making. To explain this hierarchical credit assignment, we propose a mean-field learning model by assuming that an ensemble of sub-networks, rather than a single network, are trained for a classification task. Surprisingly, our model reveals that apart from some deterministic synaptic weights connecting two neurons at neighboring layers, there exist a large number of connections that can be absent, and other connections can allow for a broad distribution of their weight values. Therefore, synaptic connections can be classified into three categories: very important ones, unimportant ones, and those of variability that may partially encode nuisance factors. Therefore, our model learns the credit assignment leading to the decision, and predicts an ensemble of sub-networks that can accomplish the same task, thereby providing insights toward understanding the macroscopic behavior of deep learning through the lens of distinct roles of synaptic weights.