 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Progressive Visual-Logic-Aligned Framework for Ride-Hailing Adjudication
Mar 18, 2026The efficient adjudication of responsibility disputes is pivotal for maintaining marketplace fairness. However, the exponential surge in ride-hailing volume renders manual review intractable, while conventional automated methods lack the reasoning transparency required for quasi-judicial decisions. Although Multimodal LLMs offer a promising paradigm, they fundamentally struggle to bridge the gap between general visual semantics and rigorous evidentiary protocols, often leading to perceptual hallucinations and logical looseness. To address these systemic misalignments, we introduce RideJudge, a Progressive Visual-Logic-Aligned Framework. Instead of relying on generic pre-training, we bridge the semantic gap via SynTraj, a synthesis engine that grounds abstract liability concepts into concrete trajectory patterns. To resolve the conflict between massive regulation volume and limited context windows, we propose an Adaptive Context Optimization strategy that distills expert knowledge, coupled with a Chain-of-Adjudication mechanism to enforce active evidentiary inquiry. Furthermore, addressing the inadequacy of sparse binary feedback for complex liability assessment, we implement a novel Ordinal-Sensitive Reinforcement Learning mechanism that calibrates decision boundaries against hierarchical severity. Extensive experiments show that our RideJudge-8B achieves 88.41\% accuracy, surpassing 32B-scale baselines and establishing a new standard for interpretable adjudication.
Multi-Object Advertisement Creative Generation
Mar 14, 2026Lifestyle images are photographs that capture environments and objects in everyday settings. In furniture product marketing, advertisers often create lifestyle images containing products to resonate with potential buyers, allowing buyers to visualize how the products fit into their daily lives. While recent advances in Generative Artificial Intelligence (GenAI) have given rise to realistic image content creation, their application in e-commerce advertising is challenging because high-quality ads must authentically representing the products in realistic scearios. Therefore, manual intervention is usually required for individual generations, making it difficult to scale to larger product catalogs. To understand the challenges faced by advertisers using GenAI to create lifestyle images at scale, we conducted evaluations on ad images generated using state-of-the-art image generation models and identified the major challenges. Based on our findings, we present CreativeAds, a multi-product ad creation system that supports scalable automated generation with customized parameter adjustment for individual generation. To ensure automated high-quality ad generation, CreativeAds innovates a pipeline that consists of three modules to address challenges in product pairing, layout generation, and background generation separately. Furthermore, CreativeAds contains an intuitive user interface to allow users to oversee generation at scale, and it also supports detailed controls on individual generation for user customized adjustments. We performed a user study on CreativeAds and extensive evaluations of the generated images, demonstrating CreativeAds's ability to create large number of high-quality images at scale for advertisers without requiring expertise in GenAI tools.
COutfitGAN: Learning to Synthesize Compatible Outfits Supervised by Silhouette Masks and Fashion Styles
Feb 12, 2025



How to recommend outfits has gained considerable attention in both academia and industry in recent years. Many studies have been carried out regarding fashion compatibility learning, to determine whether the fashion items in an outfit are compatible or not. These methods mainly focus on evaluating the compatibility of existing outfits and rarely consider applying such knowledge to 'design' new fashion items. We propose the new task of generating complementary and compatible fashion items based on an arbitrary number of given fashion items. In particular, given some fashion items that can make up an outfit, the aim of this paper is to synthesize photo-realistic images of other, complementary, fashion items that are compatible with the given ones. To achieve this, we propose an outfit generation framework, referred to as COutfitGAN, which includes a pyramid style extractor, an outfit generator, a UNet-based real/fake discriminator, and a collocation discriminator. To train and evaluate this framework, we collected a large-scale fashion outfit dataset with over 200K outfits and 800K fashion items from the Internet. Extensive experiments show that COutfitGAN outperforms other baselines in terms of similarity, authenticity, and compatibility measurements.
GAQAT: gradient-adaptive quantization-aware training for domain generalization
Dec 07, 2024



Research on loss surface geometry, such as Sharpness-Aware Minimization (SAM), shows that flatter minima improve generalization. Recent studies further reveal that flatter minima can also reduce the domain generalization (DG) gap. However, existing flatness-based DG techniques predominantly operate within a full-precision training process, which is impractical for deployment on resource-constrained edge devices that typically rely on lower bit-width representations (e.g., 4 bits, 3 bits). Consequently, low-precision quantization-aware training is critical for optimizing these techniques in real-world applications. In this paper, we observe a significant degradation in performance when applying state-of-the-art DG-SAM methods to quantized models, suggesting that current approaches fail to preserve generalizability during the low-precision training process. To address this limitation, we propose a novel Gradient-Adaptive Quantization-Aware Training (GAQAT) framework for DG. Our approach begins by identifying the scale-gradient conflict problem in low-precision quantization, where the task loss and smoothness loss induce conflicting gradients for the scaling factors of quantizers, with certain layers exhibiting opposing gradient directions. This conflict renders the optimization of quantized weights highly unstable. To mitigate this, we further introduce a mechanism to quantify gradient inconsistencies and selectively freeze the gradients of scaling factors, thereby stabilizing the training process and enhancing out-of-domain generalization. Extensive experiments validate the effectiveness of the proposed GAQAT framework. On PACS, our 3-bit and 4-bit models outperform direct DG-QAT integration by up to 4.5%. On DomainNet, the 4-bit model achieves near-lossless performance compared to full precision, with improvements of 1.39% (4-bit) and 1.06% (3-bit) over the SOTA QAT baseline.
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
Dec 02, 2024



The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to enhance the robustness further. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix. This matrix effectively partitions datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive representation and precise alignment capabilities of vision-language models for robust prompt learning. We validate NLPrompt through extensive experiments across various noise settings, demonstrating significant performance improvements.
Exploring the Interplay Between Video Generation and World Models in Autonomous Driving: A Survey
Nov 05, 2024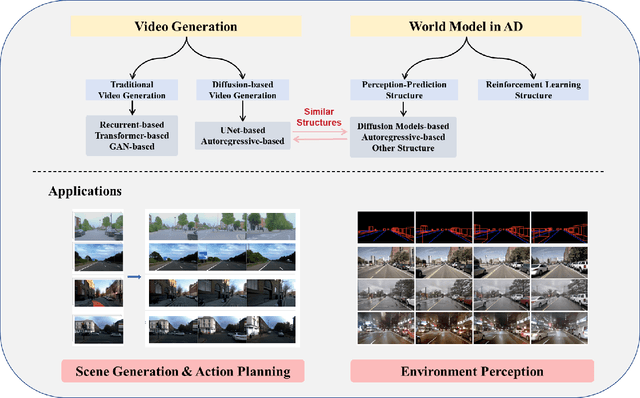
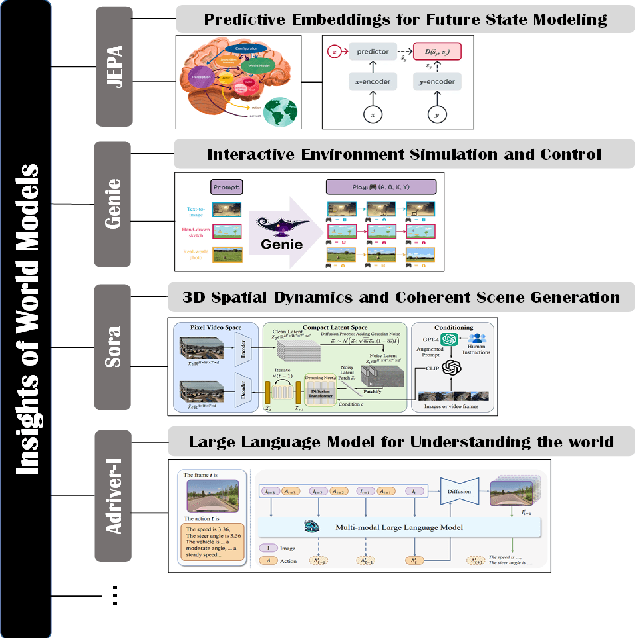
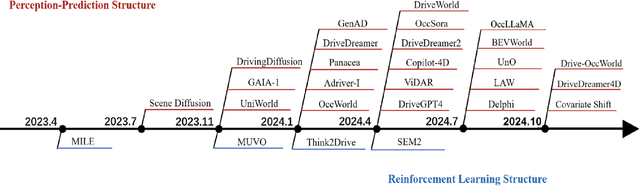
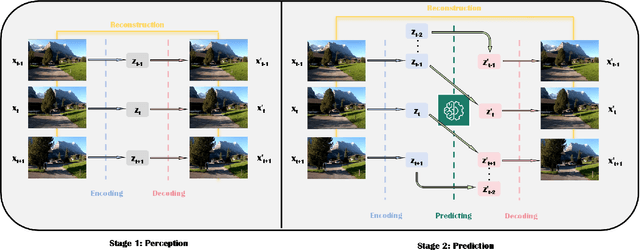
World models and video generation are pivotal technologies in the domain of autonomous driving, each playing a critical role in enhancing the robustness and reliability of autonomous systems. World models, which simulate the dynamics of real-world environments, and video generation models, which produce realistic video sequences, are increasingly being integrated to improve situational awareness and decision-making capabilities in autonomous vehicles. This paper investigates the relationship between these two technologies, focusing on how their structural parallels, particularly in diffusion-based models, contribute to more accurate and coherent simulations of driving scenarios. We examine leading works such as JEPA, Genie, and Sora, which exemplify different approaches to world model design, thereby highlighting the lack of a universally accepted definition of world models. These diverse interpretations underscore the field's evolving understanding of how world models can be optimized for various autonomous driving tasks. Furthermore, this paper discusses the key evaluation metrics employed in this domain, such as Chamfer distance for 3D scene reconstruction and Fr\'echet Inception Distance (FID) for assessing the quality of generated video content. By analyzing the interplay between video generation and world models, this survey identifies critical challenges and future research directions, emphasizing the potential of these technologies to jointly advance the performance of autonomous driving systems. The findings presented in this paper aim to provide a comprehensive understanding of how the integration of video generation and world models can drive innovation in the development of safer and more reliable autonomous vehicles.
Symmetrical Joint Learning Support-query Prototypes for Few-shot Segmentation
Jul 27, 2024



We propose Sym-Net, a novel framework for Few-Shot Segmentation (FSS) that addresses the critical issue of intra-class variation by jointly learning both query and support prototypes in a symmetrical manner. Unlike previous methods that generate query prototypes solely by matching query features to support prototypes, which is a form of bias learning towards the few-shot support samples, Sym-Net leverages a balanced symmetrical learning approach for both query and support prototypes, ensuring that the learning process does not favor one set (support or query) over the other. One of main modules of Sym-Net is the visual-text alignment-based prototype aggregation module, which is not just query-guided prototype refinement, it is a jointly learning from both support and query samples, which makes the model beneficial for handling intra-class discrepancies and allows it to generalize better to new, unseen classes. Specifically, a parameter-free prior mask generation module is designed to accurately localize both local and global regions of the query object by using sliding windows of different sizes and a self-activation kernel to suppress incorrect background matches. Additionally, to address the information loss caused by spatial pooling during prototype learning, a top-down hyper-correlation module is integrated to capture multi-scale spatial relationships between support and query images. This approach is further jointly optimized by implementing a co-optimized hard triplet mining strategy. Experimental results show that the proposed Sym-Net outperforms state-of-the-art models, which demonstrates that jointly learning support-query prototypes in a symmetrical manner for FSS offers a promising direction to enhance segmentation performance with limited annotated data.
Investigating the Impact of Quantization on Adversarial Robustness
Apr 08, 2024Quantization is a promising technique for reducing the bit-width of deep models to improve their runtime performance and storage efficiency, and thus becomes a fundamental step for deployment. In real-world scenarios, quantized models are often faced with adversarial attacks which cause the model to make incorrect inferences by introducing slight perturbations. However, recent studies have paid less attention to the impact of quantization on the model robustness. More surprisingly, existing studies on this topic even present inconsistent conclusions, which prompted our in-depth investigation. In this paper, we conduct a first-time analysis of the impact of the quantization pipeline components that can incorporate robust optimization under the settings of Post-Training Quantization and Quantization-Aware Training. Through our detailed analysis, we discovered that this inconsistency arises from the use of different pipelines in different studies, specifically regarding whether robust optimization is performed and at which quantization stage it occurs. Our research findings contribute insights into deploying more secure and robust quantized networks, assisting practitioners in reference for scenarios with high-security requirements and limited resources.
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
Preconditioned Federated Learning
Sep 20, 2023Federated Learning (FL) is a distributed machine learning approach that enables model training in communication efficient and privacy-preserving manner. The standard optimization method in FL is Federated Averaging (FedAvg), which performs multiple local SGD steps between communication rounds. FedAvg has been considered to lack algorithm adaptivity compared to modern first-order adaptive optimizations. In this paper, we propose new communication-efficient FL algortithms based on two adaptive frameworks: local adaptivity (PreFed) and server-side adaptivity (PreFedOp). Proposed methods adopt adaptivity by using a novel covariance matrix preconditioner. Theoretically, we provide convergence guarantees for our algorithms. The empirical experiments show our methods achieve state-of-the-art performances on both i.i.d. and non-i.i.d. settings.