 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreconditioned Federated Learning
Sep 20, 2023Federated Learning (FL) is a distributed machine learning approach that enables model training in communication efficient and privacy-preserving manner. The standard optimization method in FL is Federated Averaging (FedAvg), which performs multiple local SGD steps between communication rounds. FedAvg has been considered to lack algorithm adaptivity compared to modern first-order adaptive optimizations. In this paper, we propose new communication-efficient FL algortithms based on two adaptive frameworks: local adaptivity (PreFed) and server-side adaptivity (PreFedOp). Proposed methods adopt adaptivity by using a novel covariance matrix preconditioner. Theoretically, we provide convergence guarantees for our algorithms. The empirical experiments show our methods achieve state-of-the-art performances on both i.i.d. and non-i.i.d. settings.
MORE: Measurement and Correlation Based Variational Quantum Circuit for Multi-classification
Jul 21, 2023Quantum computing has shown considerable promise for compute-intensive tasks in recent years. For instance, classification tasks based on quantum neural networks (QNN) have garnered significant interest from researchers and have been evaluated in various scenarios. However, the majority of quantum classifiers are currently limited to binary classification tasks due to either constrained quantum computing resources or the need for intensive classical post-processing. In this paper, we propose an efficient quantum multi-classifier called MORE, which stands for measurement and correlation based variational quantum multi-classifier. MORE adopts the same variational ansatz as binary classifiers while performing multi-classification by fully utilizing the quantum information of a single readout qubit. To extract the complete information from the readout qubit, we select three observables that form the basis of a two-dimensional Hilbert space. We then use the quantum state tomography technique to reconstruct the readout state from the measurement results. Afterward, we explore the correlation between classes to determine the quantum labels for classes using the variational quantum clustering approach. Next, quantum label-based supervised learning is performed to identify the mapping between the input data and their corresponding quantum labels. Finally, the predicted label is determined by its closest quantum label when using the classifier. We implement this approach using the Qiskit Python library and evaluate it through extensive experiments on both noise-free and noisy quantum systems. Our evaluation results demonstrate that MORE, despite using a simple ansatz and limited quantum resources, achieves advanced performance.
Scalable Quantum Neural Networks for Classification
Aug 04, 2022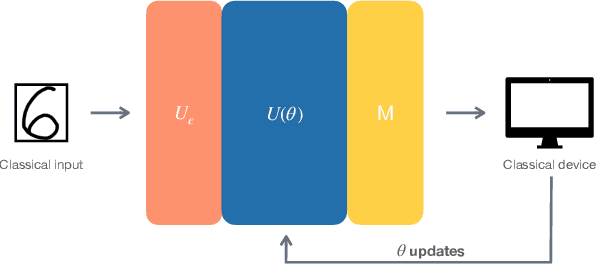
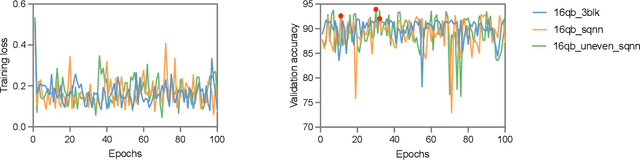
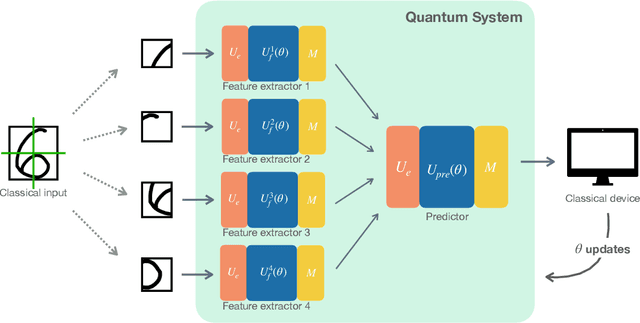

Many recent machine learning tasks resort to quantum computing to improve classification accuracy and training efficiency by taking advantage of quantum mechanics, known as quantum machine learning (QML). The variational quantum circuit (VQC) is frequently utilized to build a quantum neural network (QNN), which is a counterpart to the conventional neural network. Due to hardware limitations, however, current quantum devices only allow one to use few qubits to represent data and perform simple quantum computations. The limited quantum resource on a single quantum device degrades the data usage and limits the scale of the quantum circuits, preventing quantum advantage to some extent. To alleviate this constraint, we propose an approach to implementing a scalable quantum neural network (SQNN) by utilizing the quantum resource of multiple small-size quantum devices cooperatively. In an SQNN system, several quantum devices are used as quantum feature extractors, extracting local features from an input instance in parallel, and a quantum device works as a quantum predictor, performing prediction over the local features collected through classical communication channels. The quantum feature extractors in the SQNN system are independent of each other, so one can flexibly use quantum devices of varying sizes, with larger quantum devices extracting more local features. Especially, the SQNN can be performed on a single quantum device in a modular fashion. Our work is exploratory and carried out on a quantum system simulator using the TensorFlow Quantum library. The evaluation conducts a binary classification on the MNIST dataset. It shows that the SQNN model achieves a comparable classification accuracy to a regular QNN model of the same scale. Furthermore, it demonstrates that the SQNN model with more quantum resources can significantly improve classification accuracy.
LAWS: Look Around and Warm-Start Natural Gradient Descent for Quantum Neural Networks
May 05, 2022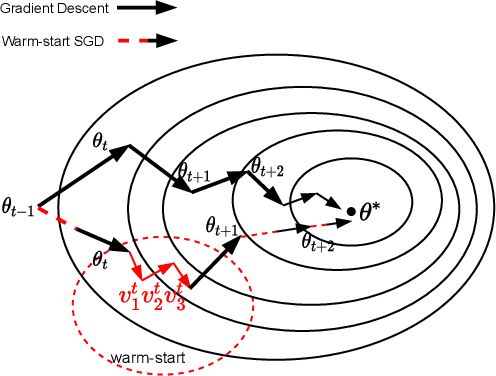
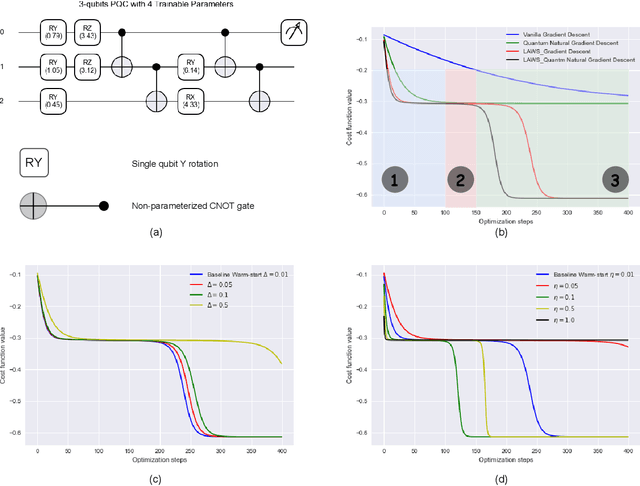

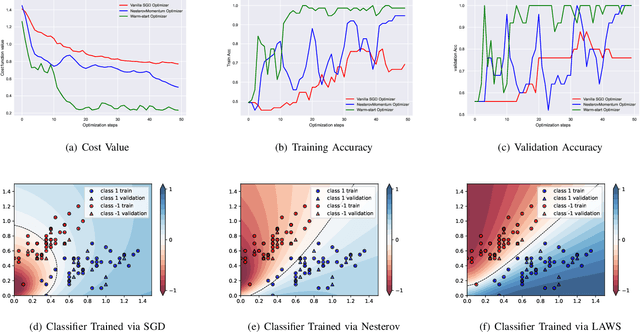
Variational quantum algorithms (VQAs) have recently received significant attention from the research community due to their promising performance in Noisy Intermediate-Scale Quantum computers (NISQ). However, VQAs run on parameterized quantum circuits (PQC) with randomly initialized parameters are characterized by barren plateaus (BP) where the gradient vanishes exponentially in the number of qubits. In this paper, we first review quantum natural gradient (QNG), which is one of the most popular algorithms used in VQA, from the classical first-order optimization point of view. Then, we proposed a \underline{L}ook \underline{A}round \underline{W}arm-\underline{S}tart QNG (LAWS) algorithm to mitigate the widespread existing BP issues. LAWS is a combinatorial optimization strategy taking advantage of model parameter initialization and fast convergence of QNG. LAWS repeatedly reinitializes parameter search space for the next iteration parameter update. The reinitialized parameter search space is carefully chosen by sampling the gradient close to the current optimal. Moreover, we present a unified framework (WS-SGD) for integrating parameter initialization techniques into the optimizer. We provide the convergence proof of the proposed framework for both convex and non-convex objective functions based on Polyak-Lojasiewicz (PL) condition. Our experiment results show that the proposed algorithm could mitigate the BP and have better generalization ability in quantum classification problems.
SAFE: Similarity-Aware Multi-Modal Fake News Detection
Feb 19, 2020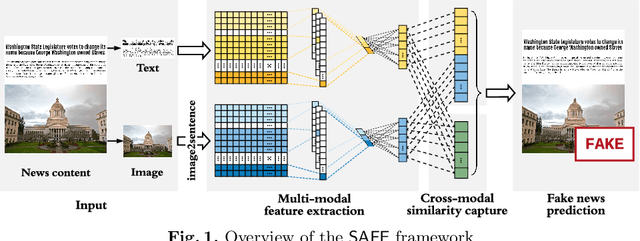
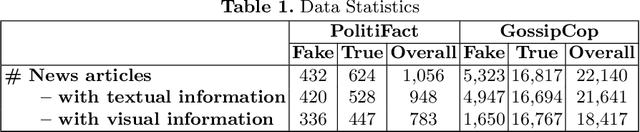

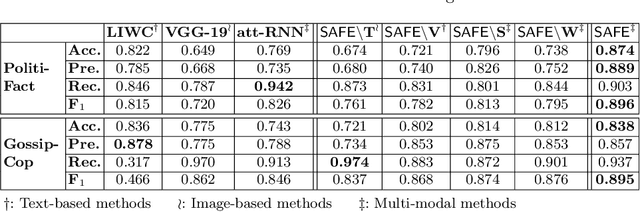
Effective detection of fake news has recently attracted significant attention. Current studies have made significant contributions to predicting fake news with less focus on exploiting the relationship (similarity) between the textual and visual information in news articles. Attaching importance to such similarity helps identify fake news stories that, for example, attempt to use irrelevant images to attract readers' attention. In this work, we propose a $\mathsf{S}$imilarity-$\mathsf{A}$ware $\mathsf{F}$ak$\mathsf{E}$ news detection method ($\mathsf{SAFE}$) which investigates multi-modal (textual and visual) information of news articles. First, neural networks are adopted to separately extract textual and visual features for news representation. We further investigate the relationship between the extracted features across modalities. Such representations of news textual and visual information along with their relationship are jointly learned and used to predict fake news. The proposed method facilitates recognizing the falsity of news articles based on their text, images, or their "mismatches." We conduct extensive experiments on large-scale real-world data, which demonstrate the effectiveness of the proposed method.