 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractice with Graph-based ANN Algorithms on Sparse Data: Chi-square Two-tower model, HNSW, Sign Cauchy Projections
Jun 13, 2023

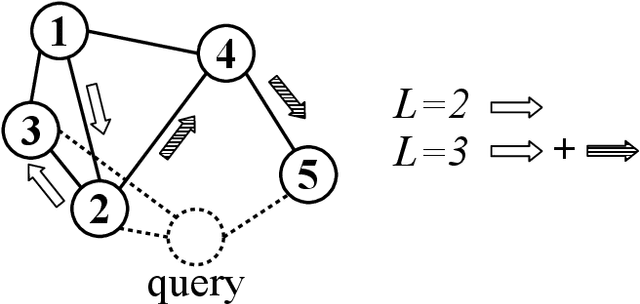

Sparse data are common. The traditional ``handcrafted'' features are often sparse. Embedding vectors from trained models can also be very sparse, for example, embeddings trained via the ``ReLu'' activation function. In this paper, we report our exploration of efficient search in sparse data with graph-based ANN algorithms (e.g., HNSW, or SONG which is the GPU version of HNSW), which are popular in industrial practice, e.g., search and ads (advertising). We experiment with the proprietary ads targeting application, as well as benchmark public datasets. For ads targeting, we train embeddings with the standard ``cosine two-tower'' model and we also develop the ``chi-square two-tower'' model. Both models produce (highly) sparse embeddings when they are integrated with the ``ReLu'' activation function. In EBR (embedding-based retrieval) applications, after we the embeddings are trained, the next crucial task is the approximate near neighbor (ANN) search for serving. While there are many ANN algorithms we can choose from, in this study, we focus on the graph-based ANN algorithm (e.g., HNSW-type). Sparse embeddings should help improve the efficiency of EBR. One benefit is the reduced memory cost for the embeddings. The other obvious benefit is the reduced computational time for evaluating similarities, because, for graph-based ANN algorithms such as HNSW, computing similarities is often the dominating cost. In addition to the effort on leveraging data sparsity for storage and computation, we also integrate ``sign cauchy random projections'' (SignCRP) to hash vectors to bits, to further reduce the memory cost and speed up the ANN search. In NIPS'13, SignCRP was proposed to hash the chi-square similarity, which is a well-adopted nonlinear kernel in NLP and computer vision. Therefore, the chi-square two-tower model, SignCRP, and HNSW are now tightly integrated.
LAWS: Look Around and Warm-Start Natural Gradient Descent for Quantum Neural Networks
May 05, 2022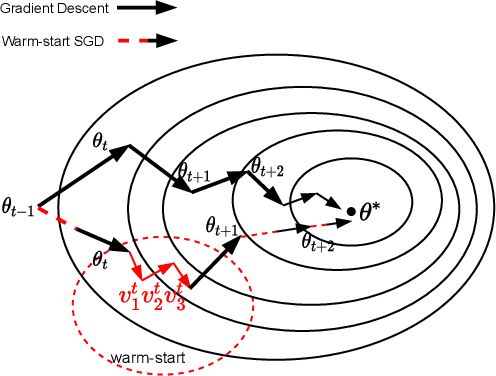
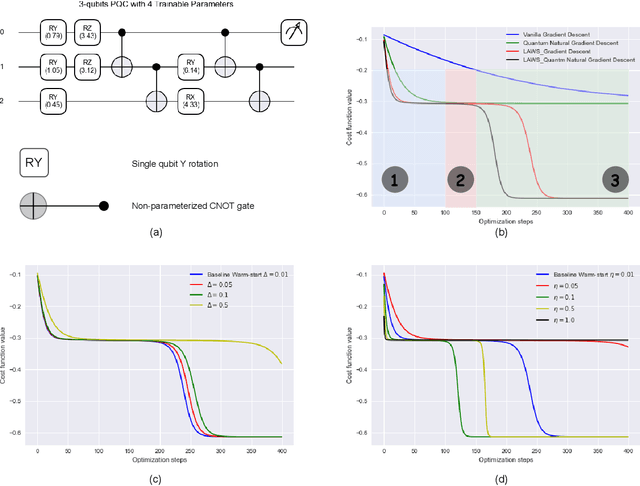

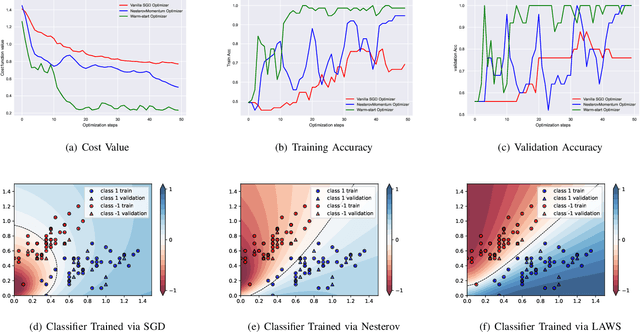
Variational quantum algorithms (VQAs) have recently received significant attention from the research community due to their promising performance in Noisy Intermediate-Scale Quantum computers (NISQ). However, VQAs run on parameterized quantum circuits (PQC) with randomly initialized parameters are characterized by barren plateaus (BP) where the gradient vanishes exponentially in the number of qubits. In this paper, we first review quantum natural gradient (QNG), which is one of the most popular algorithms used in VQA, from the classical first-order optimization point of view. Then, we proposed a \underline{L}ook \underline{A}round \underline{W}arm-\underline{S}tart QNG (LAWS) algorithm to mitigate the widespread existing BP issues. LAWS is a combinatorial optimization strategy taking advantage of model parameter initialization and fast convergence of QNG. LAWS repeatedly reinitializes parameter search space for the next iteration parameter update. The reinitialized parameter search space is carefully chosen by sampling the gradient close to the current optimal. Moreover, we present a unified framework (WS-SGD) for integrating parameter initialization techniques into the optimizer. We provide the convergence proof of the proposed framework for both convex and non-convex objective functions based on Polyak-Lojasiewicz (PL) condition. Our experiment results show that the proposed algorithm could mitigate the BP and have better generalization ability in quantum classification problems.
QuantumFed: A Federated Learning Framework for Collaborative Quantum Training
Jun 18, 2021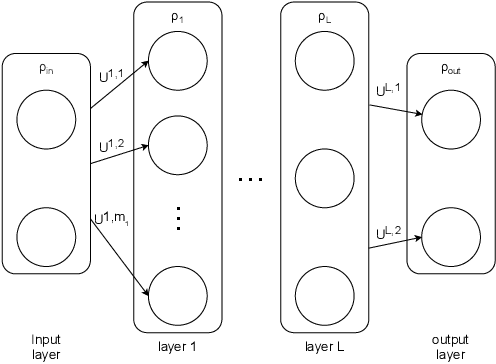


With the fast development of quantum computing and deep learning, quantum neural networks have attracted great attention recently. By leveraging the power of quantum computing, deep neural networks can potentially overcome computational power limitations in classic machine learning. However, when multiple quantum machines wish to train a global model using the local data on each machine, it may be very difficult to copy the data into one machine and train the model. Therefore, a collaborative quantum neural network framework is necessary. In this article, we borrow the core idea of federated learning to propose QuantumFed, a quantum federated learning framework to have multiple quantum nodes with local quantum data train a mode together. Our experiments show the feasibility and robustness of our framework.
Object-Based Image Coding: A Learning-Driven Revisit
Mar 18, 2020



The Object-Based Image Coding (OBIC) that was extensively studied about two decades ago, promised a vast application perspective for both ultra-low bitrate communication and high-level semantical content understanding, but it had rarely been used due to the inefficient compact representation of object with arbitrary shape. A fundamental issue behind is how to efficiently process the arbitrary-shaped objects at a fine granularity (e.g., feature element or pixel wise). To attack this, we have proposed to apply the element-wise masking and compression by devising an object segmentation network for image layer decomposition, and parallel convolution-based neural image compression networks to process masked foreground objects and background scene separately. All components are optimized in an end-to-end learning framework to intelligently weigh their (e.g., object and background) contributions for visually pleasant reconstruction. We have conducted comprehensive experiments to evaluate the performance on PASCAL VOC dataset at a very low bitrate scenario (e.g., $\lesssim$0.1 bits per pixel - bpp) which have demonstrated noticeable subjective quality improvement compared with JPEG2K, HEVC-based BPG and another learned image compression method. All relevant materials are made publicly accessible at https://njuvision.github.io/Neural-Object-Coding/.