 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREAK: Frequency-modulated High-fidelity and Real-time Audio-driven Talking Portrait Synthesis
Mar 06, 2025Achieving high-fidelity lip-speech synchronization in audio-driven talking portrait synthesis remains challenging. While multi-stage pipelines or diffusion models yield high-quality results, they suffer from high computational costs. Some approaches perform well on specific individuals with low resources, yet still exhibit mismatched lip movements. The aforementioned methods are modeled in the pixel domain. We observed that there are noticeable discrepancies in the frequency domain between the synthesized talking videos and natural videos. Currently, no research on talking portrait synthesis has considered this aspect. To address this, we propose a FREquency-modulated, high-fidelity, and real-time Audio-driven talKing portrait synthesis framework, named FREAK, which models talking portraits from the frequency domain perspective, enhancing the fidelity and naturalness of the synthesized portraits. FREAK introduces two novel frequency-based modules: 1) the Visual Encoding Frequency Modulator (VEFM) to couple multi-scale visual features in the frequency domain, better preserving visual frequency information and reducing the gap in the frequency spectrum between synthesized and natural frames. and 2) the Audio Visual Frequency Modulator (AVFM) to help the model learn the talking pattern in the frequency domain and improve audio-visual synchronization. Additionally, we optimize the model in both pixel domain and frequency domain jointly. Furthermore, FREAK supports seamless switching between one-shot and video dubbing settings, offering enhanced flexibility. Due to its superior performance, it can simultaneously support high-resolution video results and real-time inference. Extensive experiments demonstrate that our method synthesizes high-fidelity talking portraits with detailed facial textures and precise lip synchronization in real-time, outperforming state-of-the-art methods.
Exploring the Interplay Between Video Generation and World Models in Autonomous Driving: A Survey
Nov 05, 2024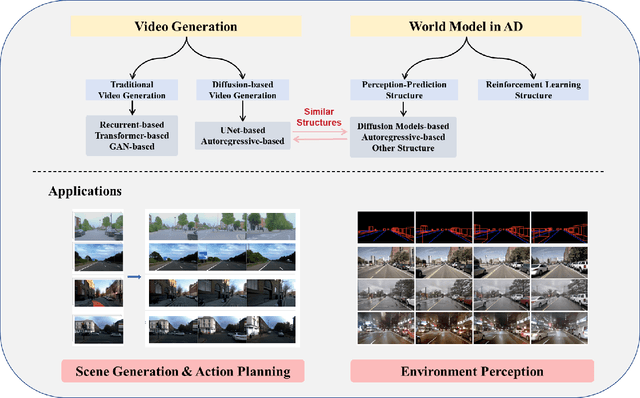
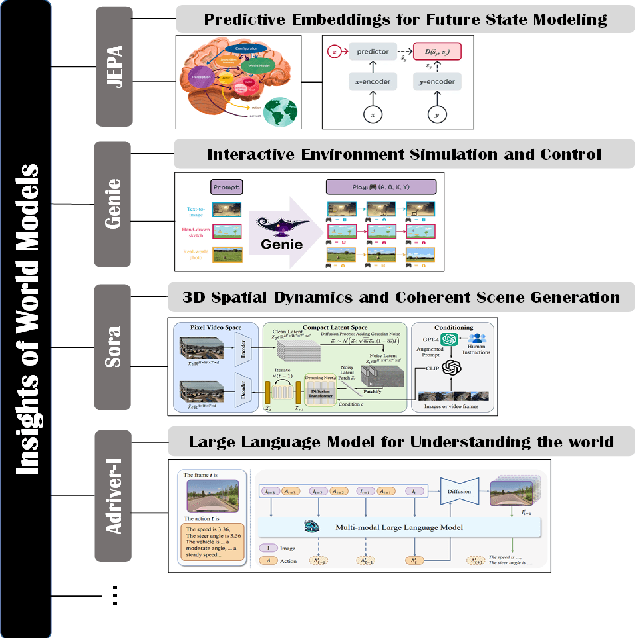
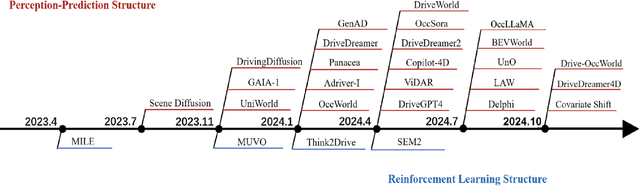
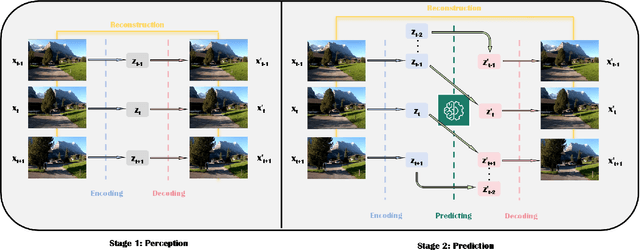
World models and video generation are pivotal technologies in the domain of autonomous driving, each playing a critical role in enhancing the robustness and reliability of autonomous systems. World models, which simulate the dynamics of real-world environments, and video generation models, which produce realistic video sequences, are increasingly being integrated to improve situational awareness and decision-making capabilities in autonomous vehicles. This paper investigates the relationship between these two technologies, focusing on how their structural parallels, particularly in diffusion-based models, contribute to more accurate and coherent simulations of driving scenarios. We examine leading works such as JEPA, Genie, and Sora, which exemplify different approaches to world model design, thereby highlighting the lack of a universally accepted definition of world models. These diverse interpretations underscore the field's evolving understanding of how world models can be optimized for various autonomous driving tasks. Furthermore, this paper discusses the key evaluation metrics employed in this domain, such as Chamfer distance for 3D scene reconstruction and Fr\'echet Inception Distance (FID) for assessing the quality of generated video content. By analyzing the interplay between video generation and world models, this survey identifies critical challenges and future research directions, emphasizing the potential of these technologies to jointly advance the performance of autonomous driving systems. The findings presented in this paper aim to provide a comprehensive understanding of how the integration of video generation and world models can drive innovation in the development of safer and more reliable autonomous vehicles.