 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Interplay Between Video Generation and World Models in Autonomous Driving: A Survey
Nov 05, 2024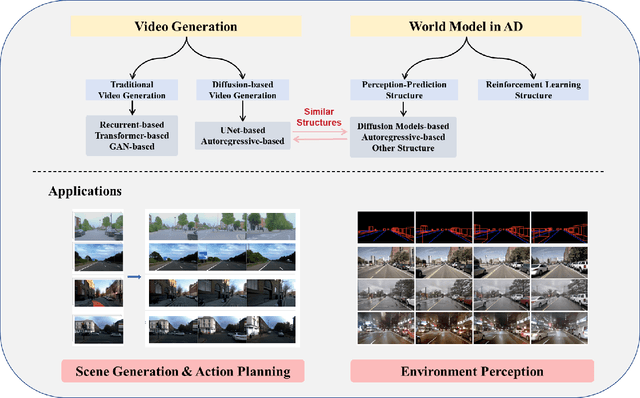
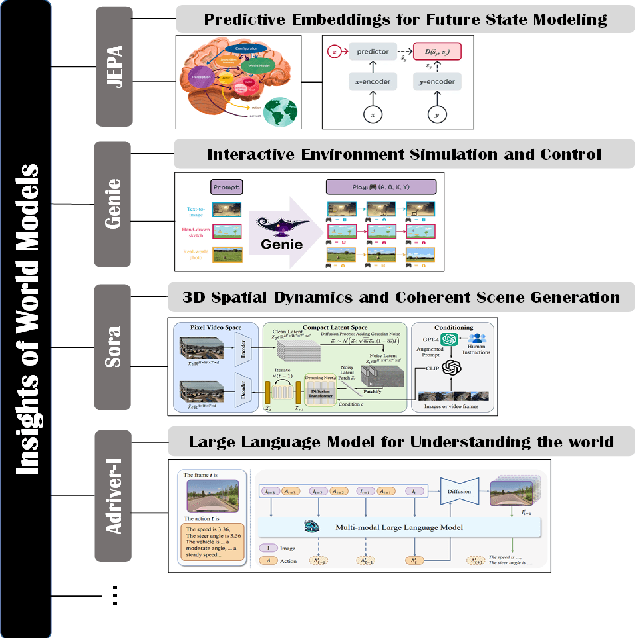
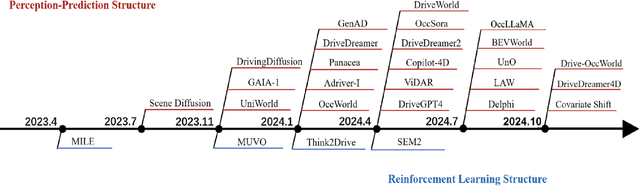
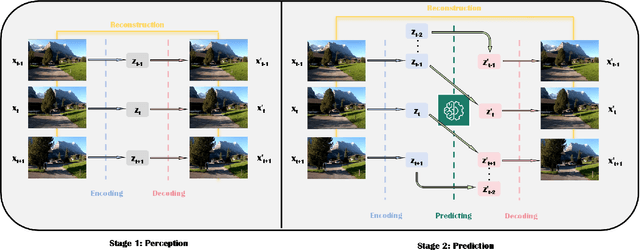
World models and video generation are pivotal technologies in the domain of autonomous driving, each playing a critical role in enhancing the robustness and reliability of autonomous systems. World models, which simulate the dynamics of real-world environments, and video generation models, which produce realistic video sequences, are increasingly being integrated to improve situational awareness and decision-making capabilities in autonomous vehicles. This paper investigates the relationship between these two technologies, focusing on how their structural parallels, particularly in diffusion-based models, contribute to more accurate and coherent simulations of driving scenarios. We examine leading works such as JEPA, Genie, and Sora, which exemplify different approaches to world model design, thereby highlighting the lack of a universally accepted definition of world models. These diverse interpretations underscore the field's evolving understanding of how world models can be optimized for various autonomous driving tasks. Furthermore, this paper discusses the key evaluation metrics employed in this domain, such as Chamfer distance for 3D scene reconstruction and Fr\'echet Inception Distance (FID) for assessing the quality of generated video content. By analyzing the interplay between video generation and world models, this survey identifies critical challenges and future research directions, emphasizing the potential of these technologies to jointly advance the performance of autonomous driving systems. The findings presented in this paper aim to provide a comprehensive understanding of how the integration of video generation and world models can drive innovation in the development of safer and more reliable autonomous vehicles.
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS