 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
ReMix: Towards Image-to-Image Translation with Limited Data
Mar 31, 2021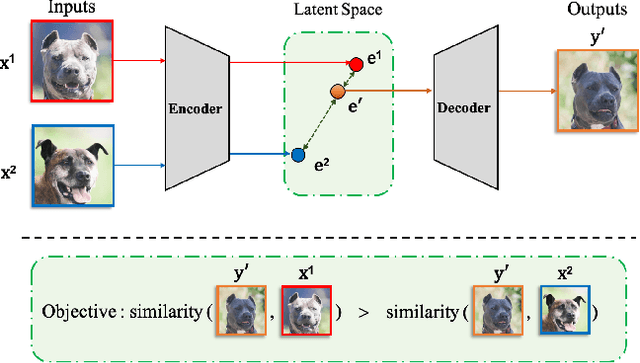
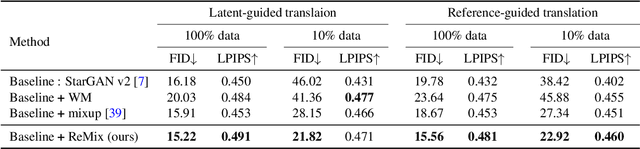
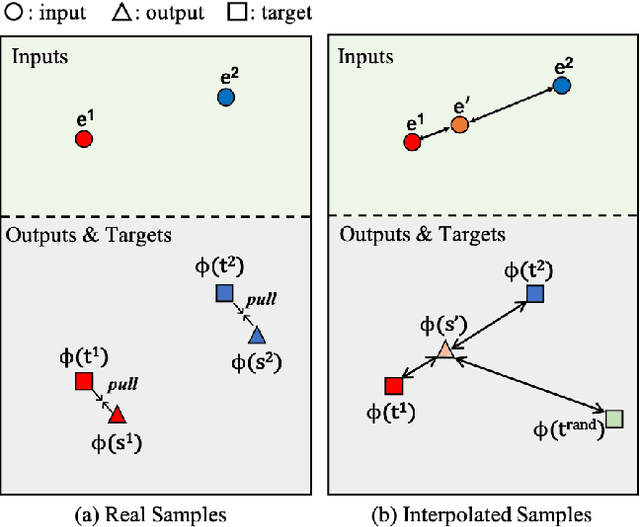
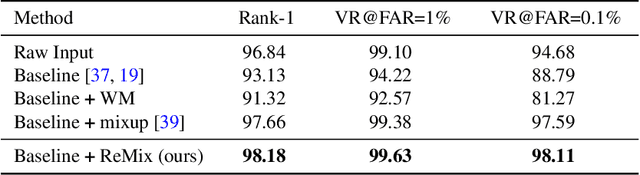
Image-to-image (I2I) translation methods based on generative adversarial networks (GANs) typically suffer from overfitting when limited training data is available. In this work, we propose a data augmentation method (ReMix) to tackle this issue. We interpolate training samples at the feature level and propose a novel content loss based on the perceptual relations among samples. The generator learns to translate the in-between samples rather than memorizing the training set, and thereby forces the discriminator to generalize. The proposed approach effectively reduces the ambiguity of generation and renders content-preserving results. The ReMix method can be easily incorporated into existing GAN models with minor modifications. Experimental results on numerous tasks demonstrate that GAN models equipped with the ReMix method achieve significant improvements.
$P^2$ Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Oct 26, 2020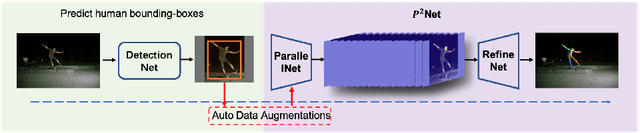

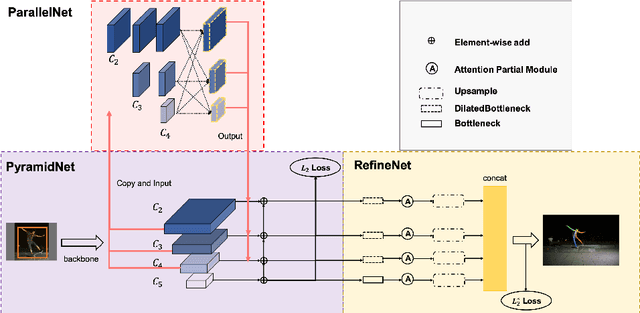
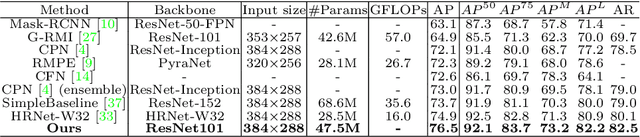
We propose an augmented Parallel-Pyramid Net ($P^2~Net$) with feature refinement by dilated bottleneck and attention module. During data preprocessing, we proposed a differentiable auto data augmentation ($DA^2$) method. We formulate the problem of searching data augmentaion policy in a differentiable form, so that the optimal policy setting can be easily updated by back propagation during training. $DA^2$ improves the training efficiency. A parallel-pyramid structure is followed to compensate the information loss introduced by the network. We innovate two fusion structures, i.e. Parallel Fusion and Progressive Fusion, to process pyramid features from backbone network. Both fusion structures leverage the advantages of spatial information affluence at high resolution and semantic comprehension at low resolution effectively. We propose a refinement stage for the pyramid features to further boost the accuracy of our network. By introducing dilated bottleneck and attention module, we increase the receptive field for the features with limited complexity and tune the importance to different feature channels. To further refine the feature maps after completion of feature extraction stage, an Attention Module ($AM$) is defined to extract weighted features from different scale feature maps generated by the parallel-pyramid structure. Compared with the traditional up-sampling refining, $AM$ can better capture the relationship between channels. Experiments corroborate the effectiveness of our proposed method. Notably, our method achieves the best performance on the challenging MSCOCO and MPII datasets.
Augmented Parallel-Pyramid Net for Attention Guided Pose-Estimation
Mar 17, 2020The target of human pose estimation is to determine body part or joint locations of each person from an image. This is a challenging problems with wide applications. To address this issue, this paper proposes an augmented parallel-pyramid net with attention partial module and differentiable auto-data augmentation. Technically, a parallel pyramid structure is proposed to compensate the loss of information. We take the design of parallel structure for reverse compensation. Meanwhile, the overall computational complexity does not increase. We further define an Attention Partial Module (APM) operator to extract weighted features from different scale feature maps generated by the parallel pyramid structure. Compared with refining through upsampling operator, APM can better capture the relationship between channels. At last, we proposed a differentiable auto data augmentation method to further improve estimation accuracy. We define a new pose search space where the sequences of data augmentations are formulated as a trainable and operational CNN component. Experiments corroborate the effectiveness of our proposed method. Notably, our method achieves the top-1 accuracy on the challenging COCO keypoint benchmark and the state-of-the-art results on the MPII datasets.