 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPMamba: Selective State Space Models for MIMO Channel Prediction in High-Mobility Environments
Dec 18, 2025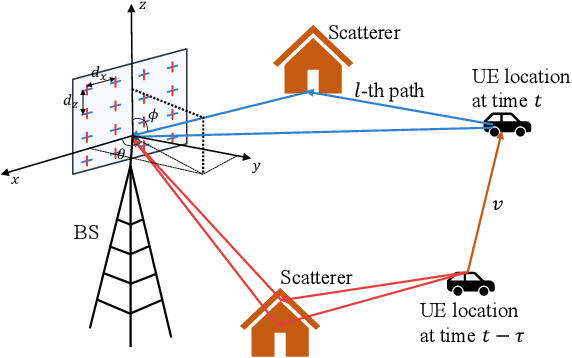
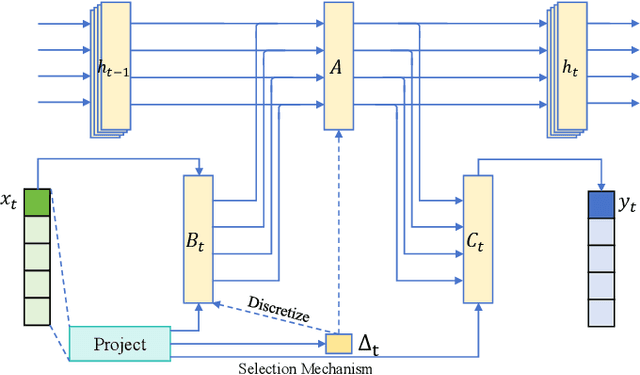
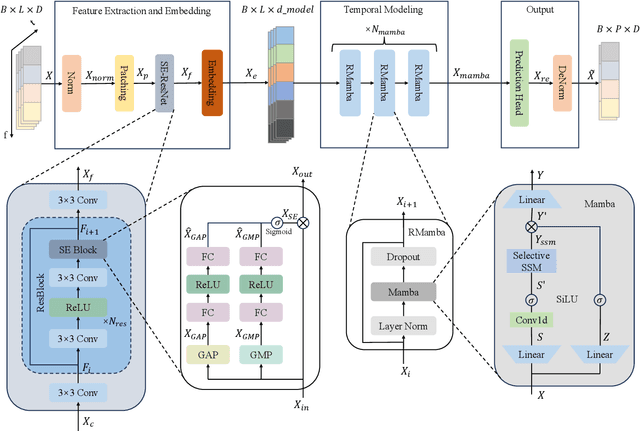
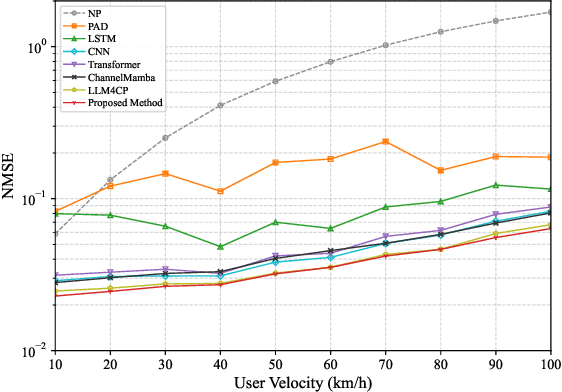
Channel prediction is a key technology for improving the performance of various functions such as precoding, adaptive modulation, and resource allocation in MIMO-OFDM systems. Especially in high-mobility scenarios with fast time-varying channels, it is crucial for resisting channel aging and ensuring communication quality. However, existing methods suffer from high complexity and the inability to accurately model the temporal variations of channels. To address this issue, this paper proposes CPMamba -- an efficient channel prediction framework based on the selective state space model. The proposed CPMamba architecture extracts features from historical channel state information (CSI) using a specifically designed feature extraction and embedding network and employs stacked residual Mamba modules for temporal modeling. By leveraging an input-dependent selective mechanism to dynamically adjust state transitions, it can effectively capture the long-range dependencies between the CSIs while maintaining a linear computational complexity. Simulation results under the 3GPP standard channel model demonstrate that CPMamba achieves state-of-the-art prediction accuracy across all scenarios, along with superior generalization and robustness. Compared to existing baseline models, CPMamba reduces the number of parameters by approximately 50 percent while achieving comparable or better performance, thereby significantly lowering the barrier for practical deployment.
Ensemble Survival Analysis for Preclinical Cognitive Decline Prediction in Alzheimer's Disease Using Longitudinal Biomarkers
Mar 20, 2025Predicting the risk of clinical progression from cognitively normal (CN) status to mild cognitive impairment (MCI) or Alzheimer's disease (AD) is critical for early intervention in Alzheimer's disease (AD). Traditional survival models often fail to capture complex longitudinal biomarker patterns associated with disease progression. We propose an ensemble survival analysis framework integrating multiple survival models to improve early prediction of clinical progression in initially cognitively normal individuals. We analyzed longitudinal biomarker data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, including 721 participants, limiting analysis to up to three visits (baseline, 6-month follow-up, 12-month follow-up). Of these, 142 (19.7%) experienced clinical progression to MCI or AD. Our approach combined penalized Cox regression (LASSO, Elastic Net) with advanced survival models (Random Survival Forest, DeepSurv, XGBoost). Model predictions were aggregated using ensemble averaging and Bayesian Model Averaging (BMA). Predictive performance was assessed using Harrell's concordance index (C-index) and time-dependent area under the curve (AUC). The ensemble model achieved a peak C-index of 0.907 and an integrated time-dependent AUC of 0.904, outperforming baseline-only models (C-index 0.608). One follow-up visit after baseline significantly improved prediction accuracy (48.1% C-index, 48.2% AUC gains), while adding a second follow-up provided only marginal gains (2.1% C-index, 2.7% AUC). Our ensemble survival framework effectively integrates diverse survival models and aggregation techniques to enhance early prediction of preclinical AD progression. These findings highlight the importance of leveraging longitudinal biomarker data, particularly one follow-up visit, for accurate risk stratification and personalized intervention strategies.
Universal Incremental Learning: Mitigating Confusion from Inter- and Intra-task Distribution Randomness
Mar 10, 2025Incremental learning (IL) aims to overcome catastrophic forgetting of previous tasks while learning new ones. Existing IL methods make strong assumptions that the incoming task type will either only increases new classes or domains (i.e. Class IL, Domain IL), or increase by a static scale in a class- and domain-agnostic manner (i.e. Versatile IL (VIL)), which greatly limit their applicability in the unpredictable and dynamic wild. In this work, we investigate $\textbf{Universal Incremental Learning (UIL)}$, where a model neither knows which new classes or domains will increase along sequential tasks, nor the scale of the increments within each task. This uncertainty prevents the model from confidently learning knowledge from all task distributions and symmetrically focusing on the diverse knowledge within each task distribution. Consequently, UIL presents a more general and realistic IL scenario, making the model face confusion arising from inter-task and intra-task distribution randomness. To $\textbf{Mi}$tigate both $\textbf{Co}$nfusion, we propose a simple yet effective framework for UIL, named $\textbf{MiCo}$. At the inter-task distribution level, we employ a multi-objective learning scheme to enforce accurate and deterministic predictions, and its effectiveness is further enhanced by a direction recalibration module that reduces conflicting gradients. Moreover, at the intra-task distribution level, we introduce a magnitude recalibration module to alleviate asymmetrical optimization towards imbalanced class distribution. Extensive experiments on three benchmarks demonstrate the effectiveness of our method, outperforming existing state-of-the-art methods in both the UIL scenario and the VIL scenario. Our code will be available at $\href{https://github.com/rolsheng/UIL}{here}$.
VLST: Virtual Lung Screening Trial for Lung Cancer Detection Using Virtual Imaging Trial
Apr 17, 2024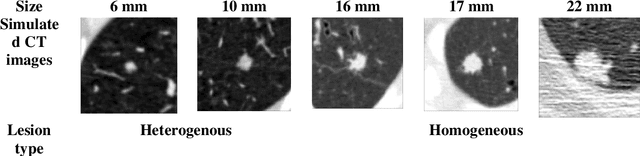

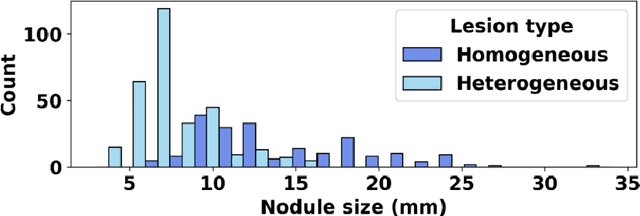
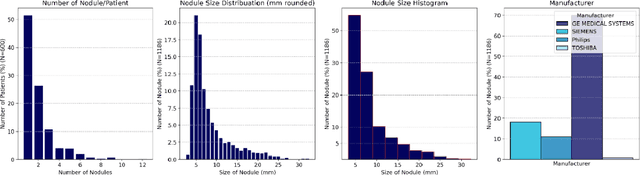
Importance: The efficacy of lung cancer screening can be significantly impacted by the imaging modality used. This Virtual Lung Screening Trial (VLST) addresses the critical need for precision in lung cancer diagnostics and the potential for reducing unnecessary radiation exposure in clinical settings. Objectives: To establish a virtual imaging trial (VIT) platform that accurately simulates real-world lung screening trials (LSTs) to assess the diagnostic accuracy of CT and CXR modalities. Design, Setting, and Participants: Utilizing computational models and machine learning algorithms, we created a diverse virtual patient population. The cohort, designed to mirror real-world demographics, was assessed using virtual imaging techniques that reflect historical imaging technologies. Main Outcomes and Measures: The primary outcome was the difference in the Area Under the Curve (AUC) for CT and CXR modalities across lesion types and sizes. Results: The study analyzed 298 CT and 313 CXR simulated images from 313 virtual patients, with a lesion-level AUC of 0.81 (95% CI: 0.78-0.84) for CT and 0.55 (95% CI: 0.53-0.56) for CXR. At the patient level, CT demonstrated an AUC of 0.85 (95% CI: 0.80-0.89), compared to 0.53 (95% CI: 0.47-0.60) for CXR. Subgroup analyses indicated CT's superior performance in detecting homogeneous lesions (AUC of 0.97 for lesion-level) and heterogeneous lesions (AUC of 0.71 for lesion-level) as well as in identifying larger nodules (AUC of 0.98 for nodules > 8 mm). Conclusion and Relevance: The VIT platform validated the superior diagnostic accuracy of CT over CXR, especially for smaller nodules, underscoring its potential to replicate real clinical imaging trials. These findings advocate for the integration of virtual trials in the evaluation and improvement of imaging-based diagnostic tools.
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
On Designing Multi-UAV aided Wireless Powered Dynamic Communication via Hierarchical Deep Reinforcement Learning
Dec 13, 2023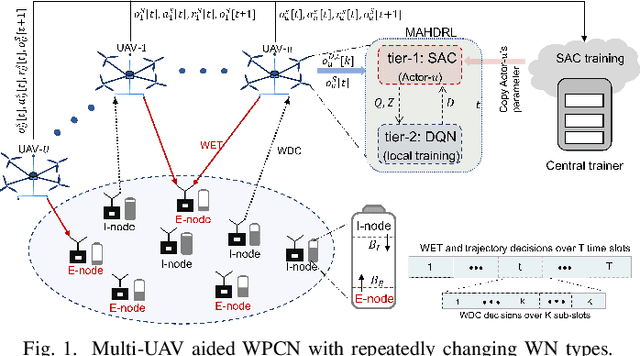
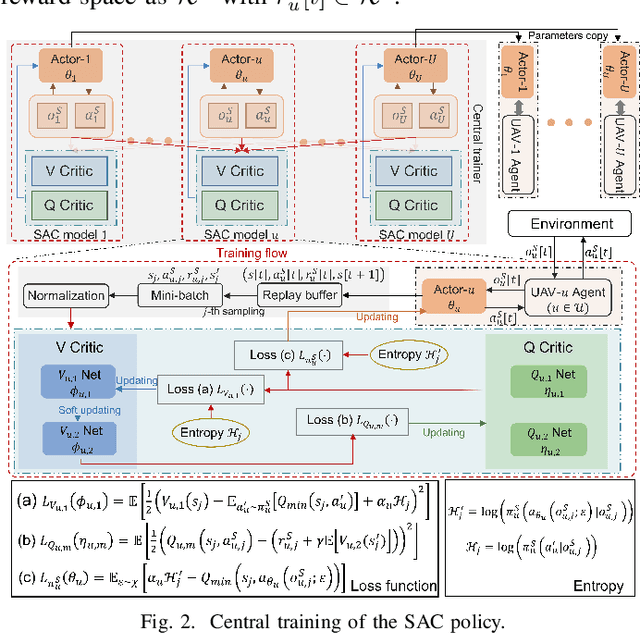
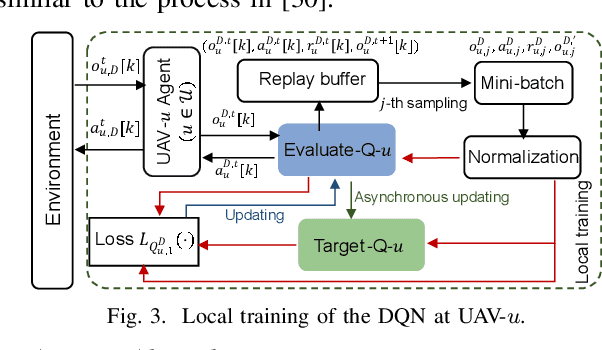
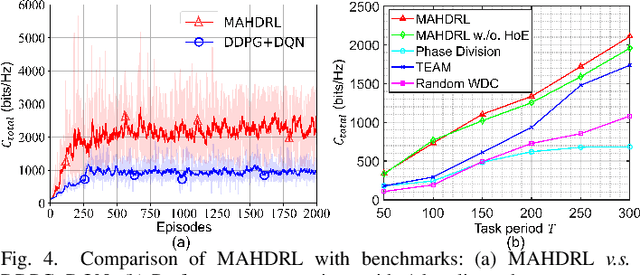
This paper proposes a novel design on the wireless powered communication network (WPCN) in dynamic environments under the assistance of multiple unmanned aerial vehicles (UAVs). Unlike the existing studies, where the low-power wireless nodes (WNs) often conform to the coherent harvest-then-transmit protocol, under our newly proposed double-threshold based WN type updating rule, each WN can dynamically and repeatedly update its WN type as an E-node for non-linear energy harvesting over time slots or an I-node for transmitting data over sub-slots. To maximize the total transmission data size of all the WNs over T slots, each of the UAVs individually determines its trajectory and binary wireless energy transmission (WET) decisions over times slots and its binary wireless data collection (WDC) decisions over sub-slots, under the constraints of each UAV's limited on-board energy and each WN's node type updating rule. However, due to the UAVs' tightly-coupled trajectories with their WET and WDC decisions, as well as each WN's time-varying battery energy, this problem is difficult to solve optimally. We then propose a new multi-agent based hierarchical deep reinforcement learning (MAHDRL) framework with two tiers to solve the problem efficiently, where the soft actor critic (SAC) policy is designed in tier-1 to determine each UAV's continuous trajectory and binary WET decision over time slots, and the deep-Q learning (DQN) policy is designed in tier-2 to determine each UAV's binary WDC decisions over sub-slots under the given UAV trajectory from tier-1. Both of the SAC policy and the DQN policy are executed distributively at each UAV. Finally, extensive simulation results are provided to validate the outweighed performance of the proposed MAHDRL approach over various state-of-the-art benchmarks.