 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLST: Virtual Lung Screening Trial for Lung Cancer Detection Using Virtual Imaging Trial
Apr 17, 2024Importance: The efficacy of lung cancer screening can be significantly impacted by the imaging modality used. This Virtual Lung Screening Trial (VLST) addresses the critical need for precision in lung cancer diagnostics and the potential for reducing unnecessary radiation exposure in clinical settings. Objectives: To establish a virtual imaging trial (VIT) platform that accurately simulates real-world lung screening trials (LSTs) to assess the diagnostic accuracy of CT and CXR modalities. Design, Setting, and Participants: Utilizing computational models and machine learning algorithms, we created a diverse virtual patient population. The cohort, designed to mirror real-world demographics, was assessed using virtual imaging techniques that reflect historical imaging technologies. Main Outcomes and Measures: The primary outcome was the difference in the Area Under the Curve (AUC) for CT and CXR modalities across lesion types and sizes. Results: The study analyzed 298 CT and 313 CXR simulated images from 313 virtual patients, with a lesion-level AUC of 0.81 (95% CI: 0.78-0.84) for CT and 0.55 (95% CI: 0.53-0.56) for CXR. At the patient level, CT demonstrated an AUC of 0.85 (95% CI: 0.80-0.89), compared to 0.53 (95% CI: 0.47-0.60) for CXR. Subgroup analyses indicated CT's superior performance in detecting homogeneous lesions (AUC of 0.97 for lesion-level) and heterogeneous lesions (AUC of 0.71 for lesion-level) as well as in identifying larger nodules (AUC of 0.98 for nodules > 8 mm). Conclusion and Relevance: The VIT platform validated the superior diagnostic accuracy of CT over CXR, especially for smaller nodules, underscoring its potential to replicate real clinical imaging trials. These findings advocate for the integration of virtual trials in the evaluation and improvement of imaging-based diagnostic tools.
Data diversity and virtual imaging in AI-based diagnosis: A case study based on COVID-19
Aug 17, 2023Many studies have investigated deep-learning-based artificial intelligence (AI) models for medical imaging diagnosis of the novel coronavirus (COVID-19), with many reports of near-perfect performance. However, variability in performance and underlying data biases raise concerns about clinical generalizability. This retrospective study involved the development and evaluation of artificial intelligence (AI) models for COVID-19 diagnosis using both diverse clinical and virtually generated medical images. In addition, we conducted a virtual imaging trial to assess how AI performance is affected by several patient- and physics-based factors, including the extent of disease, radiation dose, and imaging modality of computed tomography (CT) and chest radiography (CXR). AI performance was strongly influenced by dataset characteristics including quantity, diversity, and prevalence, leading to poor generalization with up to 20% drop in receiver operating characteristic area under the curve. Model performance on virtual CT and CXR images was comparable to overall results on clinical data. Imaging dose proved to have negligible influence on the results, but the extent of the disease had a marked affect. CT results were consistently superior to those from CXR. Overall, the study highlighted the significant impact of dataset characteristics and disease extent on COVID assessment, and the relevance and potential role of virtual imaging trial techniques on developing effective evaluation of AI algorithms and facilitating translation into diagnostic practice.
Virtual vs. Reality: External Validation of COVID-19 Classifiers using XCAT Phantoms for Chest Computed Tomography
Mar 07, 2022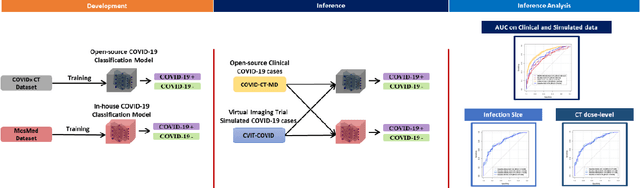

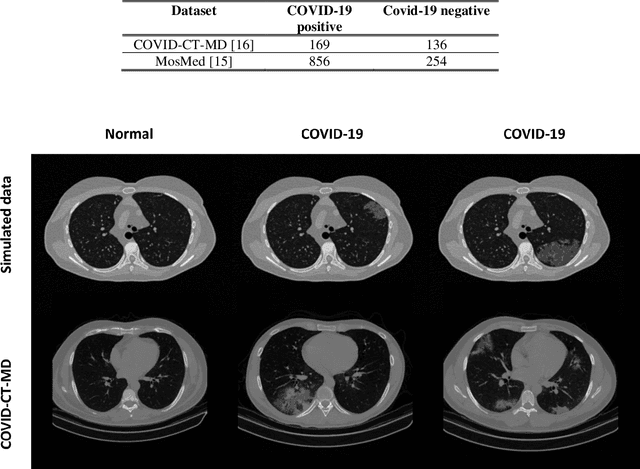
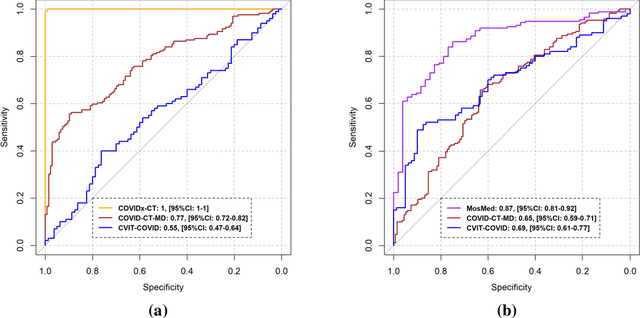
Research studies of artificial intelligence models in medical imaging have been hampered by poor generalization. This problem has been especially concerning over the last year with numerous applications of deep learning for COVID-19 diagnosis. Virtual imaging trials (VITs) could provide a solution for objective evaluation of these models. In this work utilizing the VITs, we created the CVIT-COVID dataset including 180 virtually imaged computed tomography (CT) images from simulated COVID-19 and normal phantom models under different COVID-19 morphology and imaging properties. We evaluated the performance of an open-source, deep-learning model from the University of Waterloo trained with multi-institutional data and an in-house model trained with the open clinical dataset called MosMed. We further validated the model's performance against open clinical data of 305 CT images to understand virtual vs. real clinical data performance. The open-source model was published with nearly perfect performance on the original Waterloo dataset but showed a consistent performance drop in external testing on another clinical dataset (AUC=0.77) and our simulated CVIT-COVID dataset (AUC=0.55). The in-house model achieved an AUC of 0.87 while testing on the internal test set (MosMed test set). However, performance dropped to an AUC of 0.65 and 0.69 when evaluated on clinical and our simulated CVIT-COVID dataset. The VIT framework offered control over imaging conditions, allowing us to show there was no change in performance as CT exposure was changed from 28.5 to 57 mAs. The VIT framework also provided voxel-level ground truth, revealing that performance of in-house model was much higher at AUC=0.87 for diffuse COVID-19 infection size >2.65% lung volume versus AUC=0.52 for focal disease with <2.65% volume. The virtual imaging framework enabled these uniquely rigorous analyses of model performance.
Multi-Scale Convolutional Neural Network for Automated AMD Classification using Retinal OCT Images
Oct 06, 2021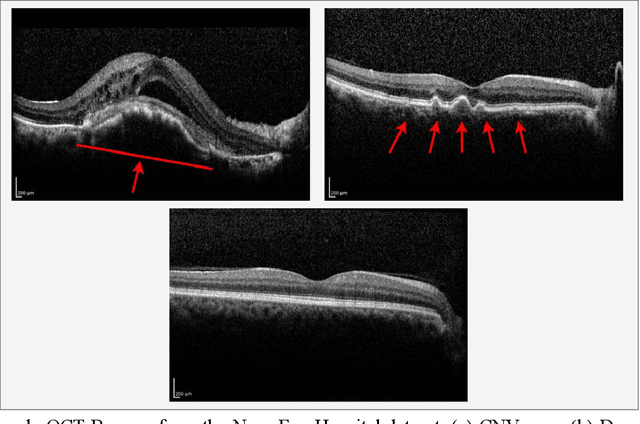

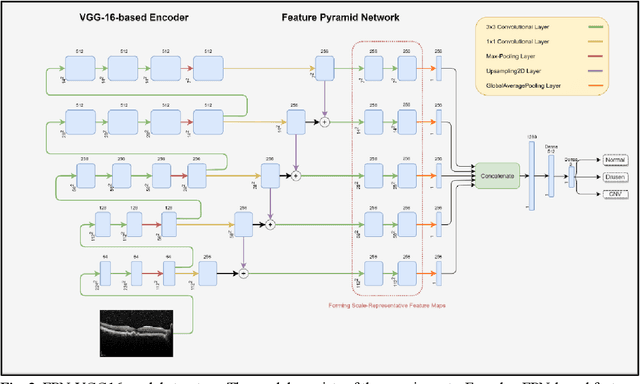
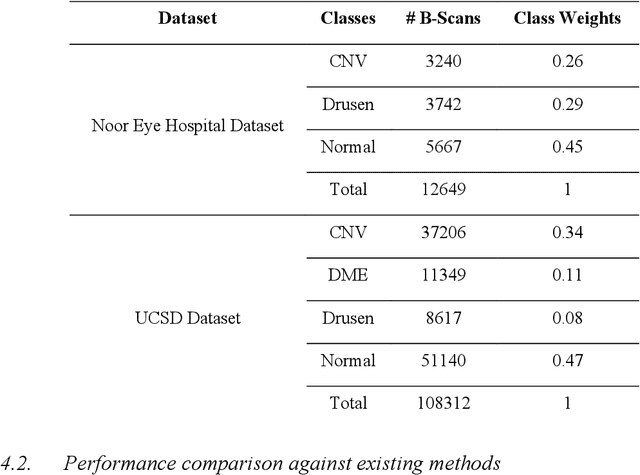
Age-related macular degeneration (AMD) is the most common cause of blindness in developed countries, especially in people over 60 years of age. The workload of specialists and the healthcare system in this field has increased in recent years mainly dues to three reasons: 1) increased use of retinal optical coherence tomography (OCT) imaging technique, 2) prevalence of population aging worldwide, and 3) chronic nature of AMD. Recent developments in deep learning have provided a unique opportunity for the development of fully automated diagnosis frameworks. Considering the presence of AMD-related retinal pathologies in varying sizes in OCT images, our objective was to propose a multi-scale convolutional neural network (CNN) capable of distinguishing pathologies using receptive fields with various sizes. The multi-scale CNN was designed based on the feature pyramid network (FPN) structure and was used to diagnose normal and two common clinical characteristics of dry and wet AMD, namely drusen and choroidal neovascularization (CNV). The proposed method was evaluated on a national dataset gathered at Noor Eye Hospital (NEH), consisting of 12649 retinal OCT images from 441 patients, and a UCSD public dataset, consisting of 108312 OCT images. The results show that the multi-scale FPN-based structure was able to improve the base model's overall accuracy by 0.4% to 3.3% for different backbone models. In addition, gradual learning improved the performance in two phases from 87.2%+-2.5% to 93.4%+-1.4% by pre-training the base model on ImageNet weights in the first phase and fine-tuning the resulting model on a dataset of OCT images in the second phase. The promising quantitative and qualitative results of the proposed architecture prove the suitability of the proposed method to be used as a screening tool in healthcare centers assisting ophthalmologists in making better diagnostic decisions.