 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegSegNet: A Public Deep Learning System for Lower Extremity CT Tissue Segmentation and Quantification
May 29, 2026Lower extremity computed tomography (CT) contains clinically relevant information for body composition analysis, sarcopenia assessment, and musculoskeletal disease monitoring, but extracting these measurements at scale requires accurate tissue segmentation and an automated quantification workflow. Existing public segmentation tools are not designed for comprehensive lower extremity CT analysis, particularly for clinically important inter/intramuscular adipose tissue, and most public methods only provide mask prediction rather than an end-to-end quantification system. To address this problem, we present LegSegNet, a deep learning system for lower extremity CT tissue segmentation and body composition quantification. Given an input CT scan, LegSegNet segments bone, skeletal muscle, subcutaneous adipose tissue, and inter/intramuscular adipose tissue. It then computes quantitative tissue measurements for downstream analysis. We developed the segmentation model using 1,302 manually annotated CT slices and evaluated it on 900 held-out test slices, with all annotations reviewed by radiologists. We benchmark LegSegNet against a broad set of 2D segmentation methods, including CNN-based models, transformer-based models, and finetuned foundation models, and further evaluate its generalization on an external public CT dataset. LegSegNet achieves the best overall segmentation performance, with an average Dice score of 89.31 on the held-out test set. To our knowledge, LegSegNet is the first publicly available end-to-end system for lower extremity CT tissue segmentation and quantification, providing a practical evaluation tool for future computer vision research in medical image analysis. The code and model weights are available at: https://github.com/mazurowski-lab/LegSegNet
Agentic Automation of BT-RADS Scoring: End-to-End Multi-Agent System for Standardized Brain Tumor Follow-up Assessment
Mar 23, 2026The Brain Tumor Reporting and Data System (BT-RADS) standardizes post-treatment MRI response assessment in patients with diffuse gliomas but requires complex integration of imaging trends, medication effects, and radiation timing. This study evaluates an end-to-end multi-agent large language model (LLM) and convolutional neural network (CNN) system for automated BT-RADS classification. A multi-agent LLM system combined with automated CNN-based tumor segmentation was retrospectively evaluated on 509 consecutive post-treatment glioma MRI examinations from a single high-volume center. An extractor agent identified clinical variables (steroid status, bevacizumab status, radiation date) from unstructured clinical notes, while a scorer agent applied BT-RADS decision logic integrating extracted variables with volumetric measurements. Expert reference standard classifications were established by an independent board-certified neuroradiologist. Of 509 examinations, 492 met inclusion criteria. The system achieved 374/492 (76.0%; 95% CI, 72.1%-79.6%) accuracy versus 283/492 (57.5%; 95% CI, 53.1%-61.8%) for initial clinical assessments (+18.5 percentage points; P<.001). Context-dependent categories showed high sensitivity (BT-1b 100%, BT-1a 92.7%, BT-3a 87.5%), while threshold-dependent categories showed moderate sensitivity (BT-3c 74.8%, BT-2 69.2%, BT-4 69.3%, BT-3b 57.1%). For BT-4, positive predictive value was 92.9%. The multi-agent LLM system achieved higher BT-RADS classification agreement with expert reference standard compared to initial clinical scoring, with high accuracy for context-dependent scores and high positive predictive value for BT-4 detection.
Diagnostic Impact of Cine Clips for Thyroid Nodule Assessment on Ultrasound
Feb 01, 2026Background: Thyroid ultrasound is commonly performed using a combination of static images and cine clips (video recordings). However, the exact utility and impact of cine images remains unknown. This study aimed to evaluate the impact of cine imaging on accuracy and consistency of thyroid nodule assessment, using the American College of Radiology Thyroid Reporting and Data System (ACR TI-RADS). Methods: 50 benign and 50 malignant thyroid nodules with cytopathology results were included. A reader study with 4 specialty-trained radiologists was then conducted over 3 rounds, assessing only static images in the first two rounds and both static and cine images in the third round. TI-RADS scores and the consequent management recommendations were then evaluated by comparing them to the malignancy status of the nodules. Results: Mean sensitivity for malignancy detection was 0.65 for static images and 0.67 with both static and cine images (p>0.5). Specificity was 0.20 for static images and 0.22 with both static and cine images (p>0.5). Management recommendations were similar with and without cine images. Intrareader agreement on feature assignments remained consistent across all rounds, though TI-RADS point totals were slightly higher with cine images. Conclusion: The inclusion of cine imaging for thyroid nodule assessment on ultrasound did not significantly change diagnostic performance. Current practice guidelines, which do not mandate cine imaging, are sufficient for accurate diagnosis.
Effectiveness of Automatically Curated Dataset in Thyroid Nodules Classification Algorithms Using Deep Learning
Feb 01, 2026The diagnosis of thyroid nodule cancers commonly utilizes ultrasound images. Several studies showed that deep learning algorithms designed to classify benign and malignant thyroid nodules could match radiologists' performance. However, data availability for training deep learning models is often limited due to the significant effort required to curate such datasets. The previous study proposed a method to curate thyroid nodule datasets automatically. It was tested to have a 63% yield rate and 83% accuracy. However, the usefulness of the generated data for training deep learning models remains unknown. In this study, we conducted experiments to determine whether using a automatically-curated dataset improves deep learning algorithms' performance. We trained deep learning models on the manually annotated and automatically-curated datasets. We also trained with a smaller subset of the automatically-curated dataset that has higher accuracy to explore the optimum usage of such dataset. As a result, the deep learning model trained on the manually selected dataset has an AUC of 0.643 (95% confidence interval [CI]: 0.62, 0.66). It is significantly lower than the AUC of the 6automatically-curated dataset trained deep learning model, 0.694 (95% confidence interval [CI]: 0.67, 0.73, P < .001). The AUC of the accurate subset trained deep learning model is 0.689 (95% confidence interval [CI]: 0.66, 0.72, P > .43), which is insignificantly worse than the AUC of the full automatically-curated dataset. In conclusion, we showed that using a automatically-curated dataset can substantially increase the performance of deep learning algorithms, and it is suggested to use all the data rather than only using the accurate subset.
Automated glenoid bone loss measurement and segmentation in CT scans for pre-operative planning in shoulder instability
Nov 18, 2025Reliable measurement of glenoid bone loss is essential for operative planning in shoulder instability, but current manual and semi-automated methods are time-consuming and often subject to interreader variability. We developed and validated a fully automated deep learning pipeline for measuring glenoid bone loss on three-dimensional computed tomography (CT) scans using a linear-based, en-face view, best-circle method. Shoulder CT images of 91 patients (average age, 40 years; range, 14-89 years; 65 men) were retrospectively collected along with manual labels including glenoid segmentation, landmarks, and bone loss measurements. The multi-stage algorithm has three main stages: (1) segmentation, where we developed a U-Net to automatically segment the glenoid and humerus; (2) anatomical landmark detection, where a second network predicts glenoid rim points; and (3) geometric fitting, where we applied principal component analysis (PCA), projection, and circle fitting to compute the percentage of bone loss. The automated measurements showed strong agreement with consensus readings and exceeded surgeon-to-surgeon consistency (intraclass correlation coefficient (ICC) 0.84 vs 0.78), including in low- and high-bone-loss subgroups (ICC 0.71 vs 0.63 and 0.83 vs 0.21, respectively; P < 0.001). For classifying patients into low, medium, and high bone-loss categories, the pipeline achieved a recall of 0.714 for low and 0.857 for high severity, with no low cases misclassified as high or vice versa. These results suggest that our method is a time-efficient and clinically reliable tool for preoperative planning in shoulder instability and for screening patients with substantial glenoid bone loss. Code and dataset are available at https://github.com/Edenliu1/Auto-Glenoid-Measurement-DL-Pipeline.
Transplant-Ready? Evaluating AI Lung Segmentation Models in Candidates with Severe Lung Disease
Sep 18, 2025
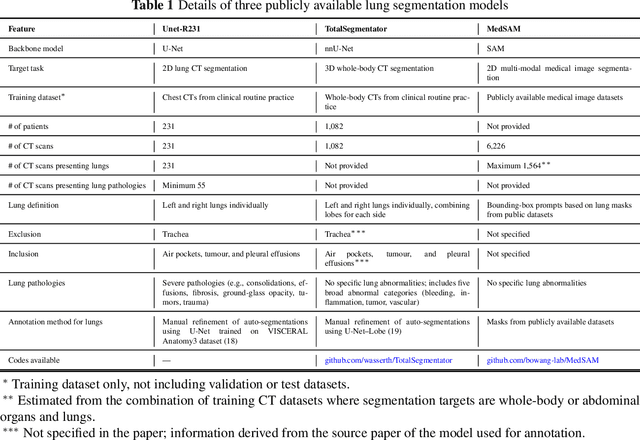
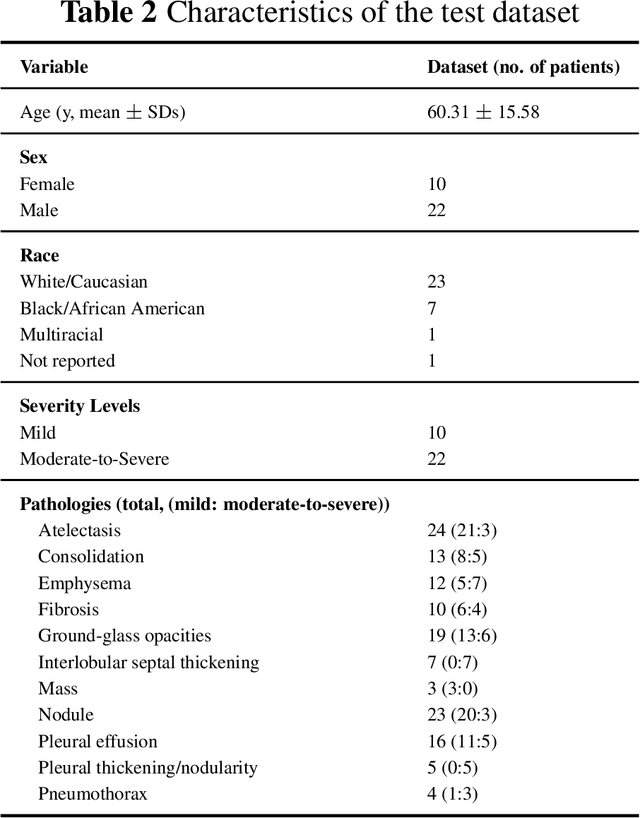
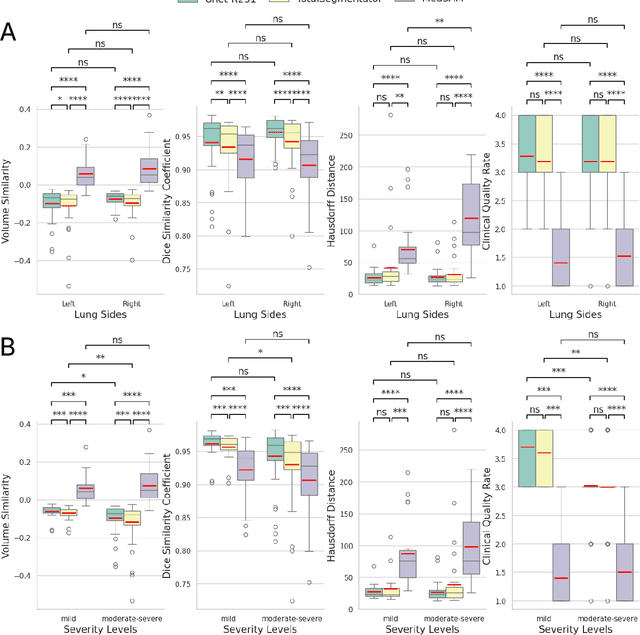
This study evaluates publicly available deep-learning based lung segmentation models in transplant-eligible patients to determine their performance across disease severity levels, pathology categories, and lung sides, and to identify limitations impacting their use in preoperative planning in lung transplantation. This retrospective study included 32 patients who underwent chest CT scans at Duke University Health System between 2017 and 2019 (total of 3,645 2D axial slices). Patients with standard axial CT scans were selected based on the presence of two or more lung pathologies of varying severity. Lung segmentation was performed using three previously developed deep learning models: Unet-R231, TotalSegmentator, MedSAM. Performance was assessed using quantitative metrics (volumetric similarity, Dice similarity coefficient, Hausdorff distance) and a qualitative measure (four-point clinical acceptability scale). Unet-R231 consistently outperformed TotalSegmentator and MedSAM in general, for different severity levels, and pathology categories (p<0.05). All models showed significant performance declines from mild to moderate-to-severe cases, particularly in volumetric similarity (p<0.05), without significant differences among lung sides or pathology types. Unet-R231 provided the most accurate automated lung segmentation among evaluated models with TotalSegmentator being a close second, though their performance declined significantly in moderate-to-severe cases, emphasizing the need for specialized model fine-tuning in severe pathology contexts.
BreastSegNet: Multi-label Segmentation of Breast MRI
Jul 18, 2025Breast MRI provides high-resolution imaging critical for breast cancer screening and preoperative staging. However, existing segmentation methods for breast MRI remain limited in scope, often focusing on only a few anatomical structures, such as fibroglandular tissue or tumors, and do not cover the full range of tissues seen in scans. This narrows their utility for quantitative analysis. In this study, we present BreastSegNet, a multi-label segmentation algorithm for breast MRI that covers nine anatomical labels: fibroglandular tissue (FGT), vessel, muscle, bone, lesion, lymph node, heart, liver, and implant. We manually annotated a large set of 1123 MRI slices capturing these structures with detailed review and correction from an expert radiologist. Additionally, we benchmark nine segmentation models, including U-Net, SwinUNet, UNet++, SAM, MedSAM, and nnU-Net with multiple ResNet-based encoders. Among them, nnU-Net ResEncM achieves the highest average Dice scores of 0.694 across all labels. It performs especially well on heart, liver, muscle, FGT, and bone, with Dice scores exceeding 0.73, and approaching 0.90 for heart and liver. All model code and weights are publicly available, and we plan to release the data at a later date.
Improving Surgical Risk Prediction Through Integrating Automated Body Composition Analysis: a Retrospective Trial on Colectomy Surgery
Jun 16, 2025Objective: To evaluate whether preoperative body composition metrics automatically extracted from CT scans can predict postoperative outcomes after colectomy, either alone or combined with clinical variables or existing risk predictors. Main outcomes and measures: The primary outcome was the predictive performance for 1-year all-cause mortality following colectomy. A Cox proportional hazards model with 1-year follow-up was used, and performance was evaluated using the concordance index (C-index) and Integrated Brier Score (IBS). Secondary outcomes included postoperative complications, unplanned readmission, blood transfusion, and severe infection, assessed using AUC and Brier Score from logistic regression. Odds ratios (OR) described associations between individual CT-derived body composition metrics and outcomes. Over 300 features were extracted from preoperative CTs across multiple vertebral levels, including skeletal muscle area, density, fat areas, and inter-tissue metrics. NSQIP scores were available for all surgeries after 2012.
MRI-CORE: A Foundation Model for Magnetic Resonance Imaging
Jun 13, 2025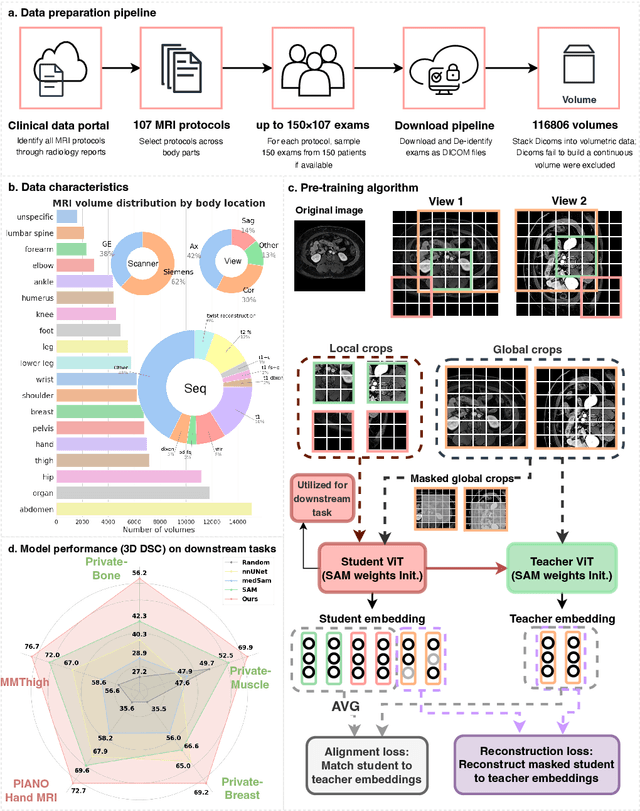
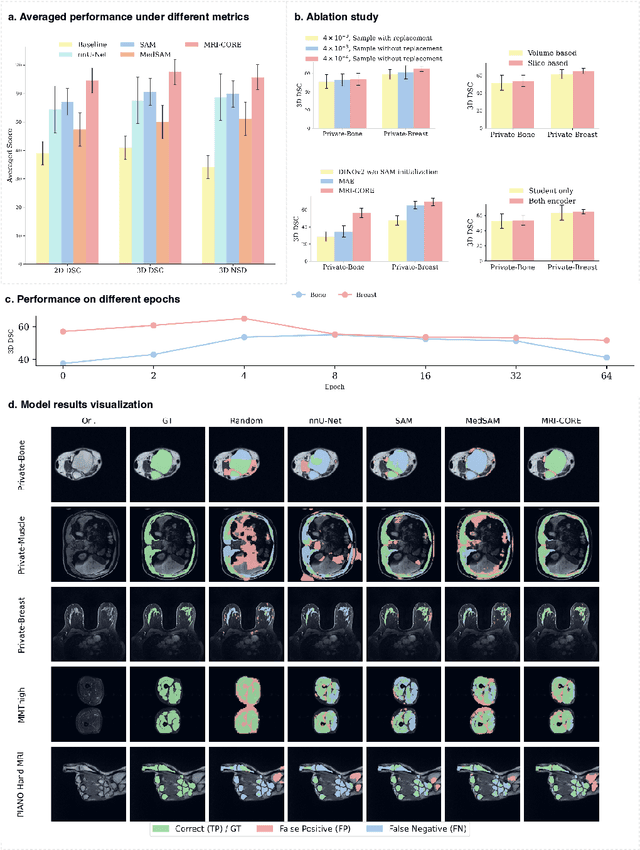
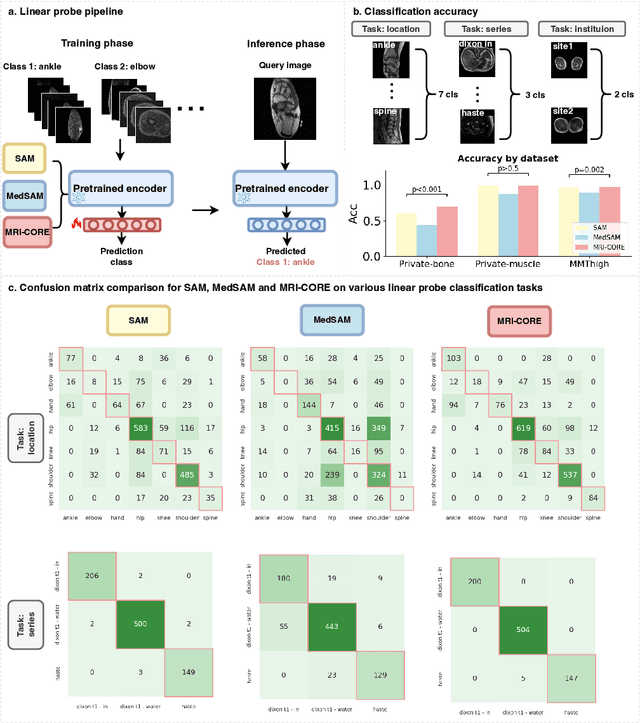
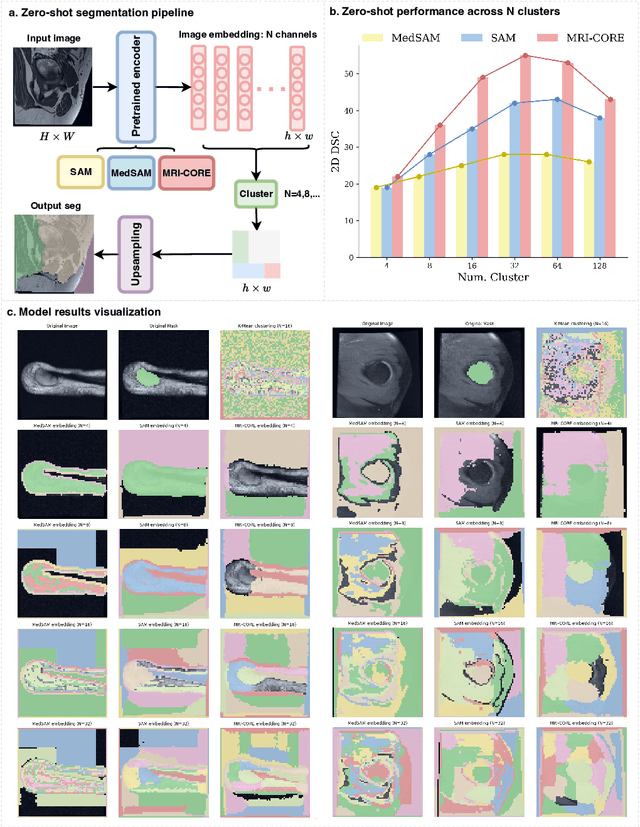
The widespread use of Magnetic Resonance Imaging (MRI) and the rise of deep learning have enabled the development of powerful predictive models for a wide range of diagnostic tasks in MRI, such as image classification or object segmentation. However, training models for specific new tasks often requires large amounts of labeled data, which is difficult to obtain due to high annotation costs and data privacy concerns. To circumvent this issue, we introduce MRI-CORE (MRI COmprehensive Representation Encoder), a vision foundation model pre-trained using more than 6 million slices from over 110,000 MRI volumes across 18 main body locations. Experiments on five diverse object segmentation tasks in MRI demonstrate that MRI-CORE can significantly improve segmentation performance in realistic scenarios with limited labeled data availability, achieving an average gain of 6.97% 3D Dice Coefficient using only 10 annotated slices per task. We further demonstrate new model capabilities in MRI such as classification of image properties including body location, sequence type and institution, and zero-shot segmentation. These results highlight the value of MRI-CORE as a generalist vision foundation model for MRI, potentially lowering the data annotation resource barriers for many applications.
GuidedMorph: Two-Stage Deformable Registration for Breast MRI
May 19, 2025
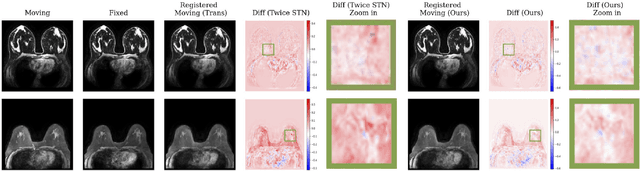
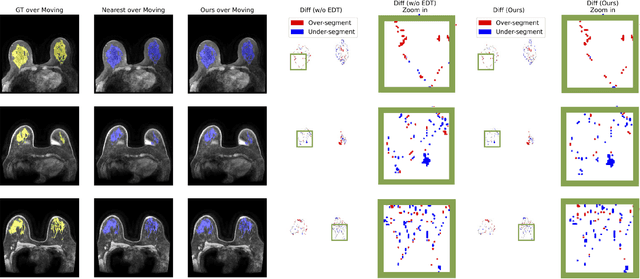
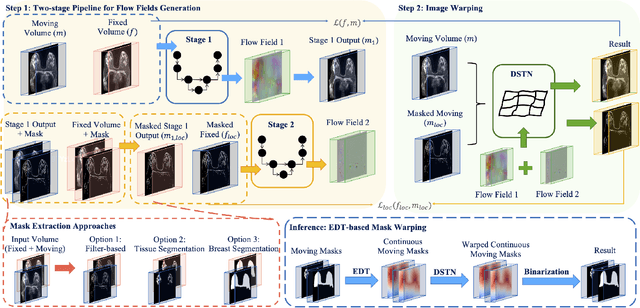
Accurately registering breast MR images from different time points enables the alignment of anatomical structures and tracking of tumor progression, supporting more effective breast cancer detection, diagnosis, and treatment planning. However, the complexity of dense tissue and its highly non-rigid nature pose challenges for conventional registration methods, which primarily focus on aligning general structures while overlooking intricate internal details. To address this, we propose \textbf{GuidedMorph}, a novel two-stage registration framework designed to better align dense tissue. In addition to a single-scale network for global structure alignment, we introduce a framework that utilizes dense tissue information to track breast movement. The learned transformation fields are fused by introducing the Dual Spatial Transformer Network (DSTN), improving overall alignment accuracy. A novel warping method based on the Euclidean distance transform (EDT) is also proposed to accurately warp the registered dense tissue and breast masks, preserving fine structural details during deformation. The framework supports paradigms that require external segmentation models and with image data only. It also operates effectively with the VoxelMorph and TransMorph backbones, offering a versatile solution for breast registration. We validate our method on ISPY2 and internal dataset, demonstrating superior performance in dense tissue, overall breast alignment, and breast structural similarity index measure (SSIM), with notable improvements by over 13.01% in dense tissue Dice, 3.13% in breast Dice, and 1.21% in breast SSIM compared to the best learning-based baseline.