 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Longitudinal Context in Clinician-Verified Interactive Lesion Tracking
May 22, 2026Tracking tumor lesions across serial CT scans is essential for oncological response assessment. Existing automated methods face a fundamental trade-off: end-to-end trackers achieve high automation but offer no opportunity to correct silent tracking failures, while decoupled registration-segmentation pipelines permit user verification yet discard the lesion's prior appearance, limiting accuracy in ambiguous cases. In this work, we propose a Verified Tracking paradigm: a clinician verifies a registration-proposed prompt, which the model leverages alongside the baseline lesion appearance to resolve segmentation ambiguities. We present a unified framework combining early spatial prompt fusion with latent temporal difference weighting for longitudinally-informed segmentation. To address data scarcity, we leverage large-scale synthetic pretraining, proving essential for exploiting longitudinal context, improving performance by up to 4.5 Dice points over training from scratch. Our approach secured first place in the MICCAI autoPET IV challenge. We further curate and release PanTrack, a new longitudinal pancreatic cancer benchmark, to assess out-of-distribution generalization. Experiments show that our model outperforms prior work in both fully automatic and the proposed verified tracking setting offering a clinically safe middle ground between automation and control. Code, model and dataset will be released at https://github.com/MIC-DKFZ/LongiSeg
The autoPET3 Challenge -- Automated Lesion Segmentation in Whole-Body PET/CT - Multitracer Multicenter Generalization
May 07, 2026We report the design and results of the third autoPET challenge (MICCAI 2024), which benchmarked automated lesion segmentation in whole-body PET/CT under a compositional generalization setting. Training data comprised 1,014 [18F]-FDG PET/CT studies from the University Hospital Tübingen and 597 [18F]/[68Ga]-PSMA PET/CT studies from the LMU University Hospital Munich, constituting the largest publicly available annotated PSMA PET/CT dataset to date. The held-out test set of 200 studies covered four tracer-center combinations, two of which represented unseen compositional pairings. A complementary data-centric award category isolated the contribution of data handling strategies by restricting participants to a fixed baseline model. Seventeen teams submitted 27 algorithms, predominantly nnU-Net-based 3D networks with PET/CT channel concatenation. The top-ranked algorithm achieved a mean DSC of 0.66, FNV of 3.18 mL, and FPV of 2.78 mL across all four test conditions, improving DSC by 8% and reducing the false-negative volume by 5 mL relative to the provided baseline. Ranking was stable across bootstrap resampling and alternative ranking schemes for the top tier. Beyond the benchmark, we provide an in-depth analysis of segmentation performance at the patient and lesion level. Three main conclusions can be drawn: (1) in-domain multitracer PET/CT segmentation is sufficient and probably approaching reader agreement; (2) compositional generalization to unseen tracer-center combinations remains an open problem mainly driven by systematic volume overestimation; (3) heterogeneity and case difficulty drive performance variation substantially more than the choice of algorithm among top-ranked teams.
CRONOS: Continuous Time Reconstruction for 4D Medical Longitudinal Series
Dec 18, 2025Forecasting how 3D medical scans evolve over time is important for disease progression, treatment planning, and developmental assessment. Yet existing models either rely on a single prior scan, fixed grid times, or target global labels, which limits voxel-level forecasting under irregular sampling. We present CRONOS, a unified framework for many-to-one prediction from multiple past scans that supports both discrete (grid-based) and continuous (real-valued) timestamps in one model, to the best of our knowledge the first to achieve continuous sequence-to-image forecasting for 3D medical data. CRONOS learns a spatio-temporal velocity field that transports context volumes toward a target volume at an arbitrary time, while operating directly in 3D voxel space. Across three public datasets spanning Cine-MRI, perfusion CT, and longitudinal MRI, CRONOS outperforms other baselines, while remaining computationally competitive. We will release code and evaluation protocols to enable reproducible, multi-dataset benchmarking of multi-context, continuous-time forecasting.
VoxTell: Free-Text Promptable Universal 3D Medical Image Segmentation
Nov 14, 2025We introduce VoxTell, a vision-language model for text-prompted volumetric medical image segmentation. It maps free-form descriptions, from single words to full clinical sentences, to 3D masks. Trained on 62K+ CT, MRI, and PET volumes spanning over 1K anatomical and pathological classes, VoxTell uses multi-stage vision-language fusion across decoder layers to align textual and visual features at multiple scales. It achieves state-of-the-art zero-shot performance across modalities on unseen datasets, excelling on familiar concepts while generalizing to related unseen classes. Extensive experiments further demonstrate strong cross-modality transfer, robustness to linguistic variations and clinical language, as well as accurate instance-specific segmentation from real-world text. Code is available at: https://www.github.com/MIC-DKFZ/VoxTell
MeisenMeister: A Simple Two Stage Pipeline for Breast Cancer Classification on MRI
Oct 31, 2025The ODELIA Breast MRI Challenge 2025 addresses a critical issue in breast cancer screening: improving early detection through more efficient and accurate interpretation of breast MRI scans. Even though methods for general-purpose whole-body lesion segmentation as well as multi-time-point analysis exist, breast cancer detection remains highly challenging, largely due to the limited availability of high-quality segmentation labels. Therefore, developing robust classification-based approaches is crucial for the future of early breast cancer detection, particularly in applications such as large-scale screening. In this write-up, we provide a comprehensive overview of our approach to the challenge. We begin by detailing the underlying concept and foundational assumptions that guided our work. We then describe the iterative development process, highlighting the key stages of experimentation, evaluation, and refinement that shaped the evolution of our solution. Finally, we present the reasoning and evidence that informed the design choices behind our final submission, with a focus on performance, robustness, and clinical relevance. We release our full implementation publicly at https://github.com/MIC-DKFZ/MeisenMeister
A Multi-Stage Fine-Tuning and Ensembling Strategy for Pancreatic Tumor Segmentation in Diagnostic and Therapeutic MRI
Aug 29, 2025Automated segmentation of Pancreatic Ductal Adenocarcinoma (PDAC) from MRI is critical for clinical workflows but is hindered by poor tumor-tissue contrast and a scarcity of annotated data. This paper details our submission to the PANTHER challenge, addressing both diagnostic T1-weighted (Task 1) and therapeutic T2-weighted (Task 2) segmentation. Our approach is built upon the nnU-Net framework and leverages a deep, multi-stage cascaded pre-training strategy, starting from a general anatomical foundation model and sequentially fine-tuning on CT pancreatic lesion datasets and the target MRI modalities. Through extensive five-fold cross-validation, we systematically evaluated data augmentation schemes and training schedules. Our analysis revealed a critical trade-off, where aggressive data augmentation produced the highest volumetric accuracy, while default augmentations yielded superior boundary precision (achieving a state-of-the-art MASD of 5.46 mm and HD95 of 17.33 mm for Task 1). For our final submission, we exploited this finding by constructing custom, heterogeneous ensembles of specialist models, essentially creating a mix of experts. This metric-aware ensembling strategy proved highly effective, achieving a top cross-validation Tumor Dice score of 0.661 for Task 1 and 0.523 for Task 2. Our work presents a robust methodology for developing specialized, high-performance models in the context of limited data and complex medical imaging tasks (Team MIC-DKFZ).
Towards Interactive Lesion Segmentation in Whole-Body PET/CT with Promptable Models
Aug 29, 2025Whole-body PET/CT is a cornerstone of oncological imaging, yet accurate lesion segmentation remains challenging due to tracer heterogeneity, physiological uptake, and multi-center variability. While fully automated methods have advanced substantially, clinical practice benefits from approaches that keep humans in the loop to efficiently refine predicted masks. The autoPET/CT IV challenge addresses this need by introducing interactive segmentation tasks based on simulated user prompts. In this work, we present our submission to Task 1. Building on the winning autoPET III nnU-Net pipeline, we extend the framework with promptable capabilities by encoding user-provided foreground and background clicks as additional input channels. We systematically investigate representations for spatial prompts and demonstrate that Euclidean Distance Transform (EDT) encodings consistently outperform Gaussian kernels. Furthermore, we propose online simulation of user interactions and a custom point sampling strategy to improve robustness under realistic prompting conditions. Our ensemble of EDT-based models, trained with and without external data, achieves the strongest cross-validation performance, reducing both false positives and false negatives compared to baseline models. These results highlight the potential of promptable models to enable efficient, user-guided segmentation workflows in multi-tracer, multi-center PET/CT. Code is publicly available at https://github.com/MIC-DKFZ/autoPET-interactive
Temporal Flow Matching for Learning Spatio-Temporal Trajectories in 4D Longitudinal Medical Imaging
Aug 29, 2025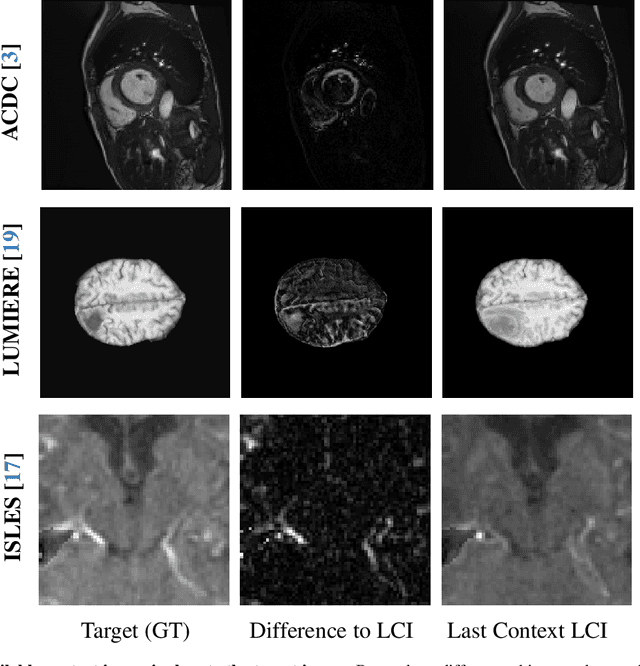

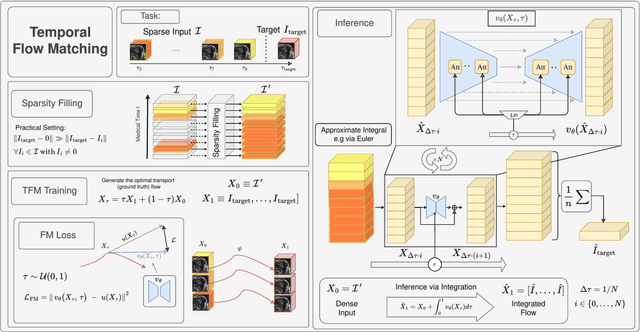
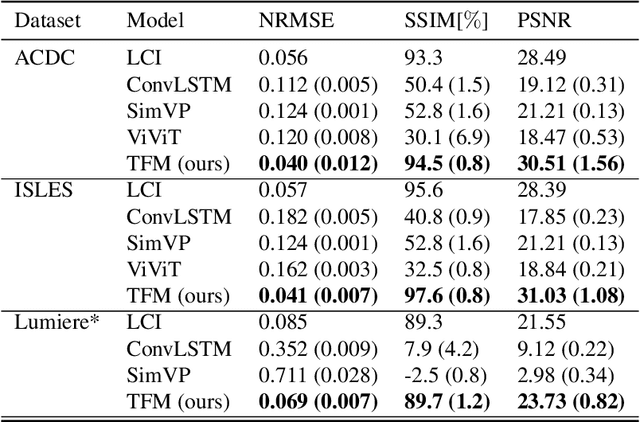
Understanding temporal dynamics in medical imaging is crucial for applications such as disease progression modeling, treatment planning and anatomical development tracking. However, most deep learning methods either consider only single temporal contexts, or focus on tasks like classification or regression, limiting their ability for fine-grained spatial predictions. While some approaches have been explored, they are often limited to single timepoints, specific diseases or have other technical restrictions. To address this fundamental gap, we introduce Temporal Flow Matching (TFM), a unified generative trajectory method that (i) aims to learn the underlying temporal distribution, (ii) by design can fall back to a nearest image predictor, i.e. predicting the last context image (LCI), as a special case, and (iii) supports $3D$ volumes, multiple prior scans, and irregular sampling. Extensive benchmarks on three public longitudinal datasets show that TFM consistently surpasses spatio-temporal methods from natural imaging, establishing a new state-of-the-art and robust baseline for $4D$ medical image prediction.
nnInteractive: Redefining 3D Promptable Segmentation
Mar 11, 2025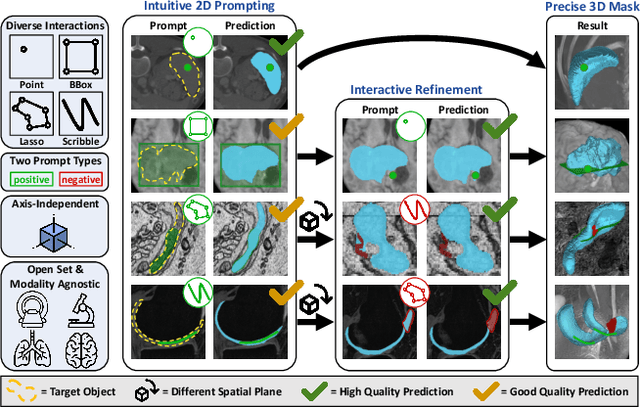
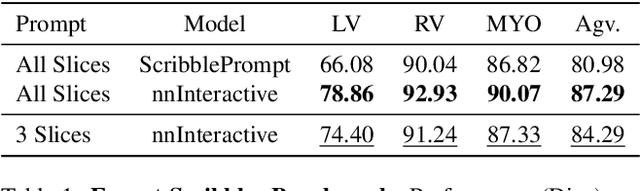
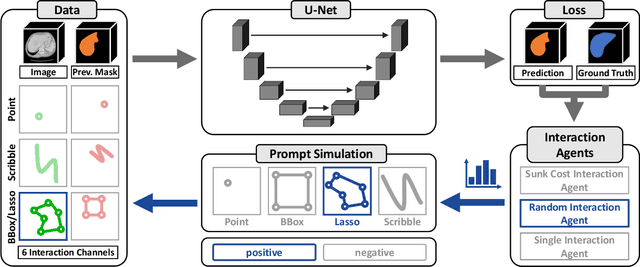
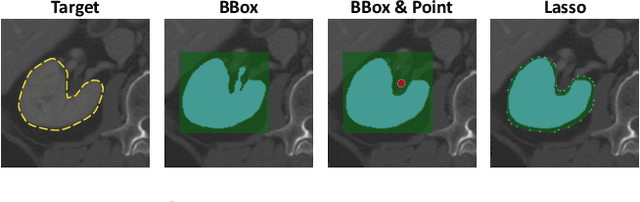
Accurate and efficient 3D segmentation is essential for both clinical and research applications. While foundation models like SAM have revolutionized interactive segmentation, their 2D design and domain shift limitations make them ill-suited for 3D medical images. Current adaptations address some of these challenges but remain limited, either lacking volumetric awareness, offering restricted interactivity, or supporting only a small set of structures and modalities. Usability also remains a challenge, as current tools are rarely integrated into established imaging platforms and often rely on cumbersome web-based interfaces with restricted functionality. We introduce nnInteractive, the first comprehensive 3D interactive open-set segmentation method. It supports diverse prompts-including points, scribbles, boxes, and a novel lasso prompt-while leveraging intuitive 2D interactions to generate full 3D segmentations. Trained on 120+ diverse volumetric 3D datasets (CT, MRI, PET, 3D Microscopy, etc.), nnInteractive sets a new state-of-the-art in accuracy, adaptability, and usability. Crucially, it is the first method integrated into widely used image viewers (e.g., Napari, MITK), ensuring broad accessibility for real-world clinical and research applications. Extensive benchmarking demonstrates that nnInteractive far surpasses existing methods, setting a new standard for AI-driven interactive 3D segmentation. nnInteractive is publicly available: https://github.com/MIC-DKFZ/napari-nninteractive (Napari plugin), https://www.mitk.org/MITK-nnInteractive (MITK integration), https://github.com/MIC-DKFZ/nnInteractive (Python backend).
LesionLocator: Zero-Shot Universal Tumor Segmentation and Tracking in 3D Whole-Body Imaging
Feb 28, 2025In this work, we present LesionLocator, a framework for zero-shot longitudinal lesion tracking and segmentation in 3D medical imaging, establishing the first end-to-end model capable of 4D tracking with dense spatial prompts. Our model leverages an extensive dataset of 23,262 annotated medical scans, as well as synthesized longitudinal data across diverse lesion types. The diversity and scale of our dataset significantly enhances model generalizability to real-world medical imaging challenges and addresses key limitations in longitudinal data availability. LesionLocator outperforms all existing promptable models in lesion segmentation by nearly 10 dice points, reaching human-level performance, and achieves state-of-the-art results in lesion tracking, with superior lesion retrieval and segmentation accuracy. LesionLocator not only sets a new benchmark in universal promptable lesion segmentation and automated longitudinal lesion tracking but also provides the first open-access solution of its kind, releasing our synthetic 4D dataset and model to the community, empowering future advancements in medical imaging. Code is available at: www.github.com/MIC-DKFZ/LesionLocator