 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Speech: Benchmarking, Evaluation, and Parsing of Spoken Code-Switching Beyond Standard UD Assumptions
Feb 06, 2026Spoken code-switching (CSW) challenges syntactic parsing in ways not observed in written text. Disfluencies, repetition, ellipsis, and discourse-driven structure routinely violate standard Universal Dependencies (UD) assumptions, causing parsers and large language models (LLMs) to fail despite strong performance on written data. These failures are compounded by rigid evaluation metrics that conflate genuine structural errors with acceptable variation. In this work, we present a systems-oriented approach to spoken CSW parsing. We introduce a linguistically grounded taxonomy of spoken CSW phenomena and SpokeBench, an expert-annotated gold benchmark designed to test spoken-language structure beyond standard UD assumptions. We further propose FLEX-UD, an ambiguity-aware evaluation metric, which reveals that existing parsing techniques perform poorly on spoken CSW by penalizing linguistically plausible analyses as errors. We then propose DECAP, a decoupled agentic parsing framework that isolates spoken-phenomena handling from core syntactic analysis. Experiments show that DECAP produces more robust and interpretable parses without retraining and achieves up to 52.6% improvements over existing parsing techniques. FLEX-UD evaluations further reveal qualitative improvements that are masked by standard metrics.
DisasterVQA: A Visual Question Answering Benchmark Dataset for Disaster Scenes
Jan 20, 2026Social media imagery provides a low-latency source of situational information during natural and human-induced disasters, enabling rapid damage assessment and response. While Visual Question Answering (VQA) has shown strong performance in general-purpose domains, its suitability for the complex and safety-critical reasoning required in disaster response remains unclear. We introduce DisasterVQA, a benchmark dataset designed for perception and reasoning in crisis contexts. DisasterVQA consists of 1,395 real-world images and 4,405 expert-curated question-answer pairs spanning diverse events such as floods, wildfires, and earthquakes. Grounded in humanitarian frameworks including FEMA ESF and OCHA MIRA, the dataset includes binary, multiple-choice, and open-ended questions covering situational awareness and operational decision-making tasks. We benchmark seven state-of-the-art vision-language models and find performance variability across question types, disaster categories, regions, and humanitarian tasks. Although models achieve high accuracy on binary questions, they struggle with fine-grained quantitative reasoning, object counting, and context-sensitive interpretation, particularly for underrepresented disaster scenarios. DisasterVQA provides a challenging and practical benchmark to guide the development of more robust and operationally meaningful vision-language models for disaster response. The dataset is publicly available at https://zenodo.org/records/18267770.
MATEX: Multi-scale Attention and Text-guided Explainability of Medical Vision-Language Models
Jan 16, 2026We introduce MATEX (Multi-scale Attention and Text-guided Explainability), a novel framework that advances interpretability in medical vision-language models by incorporating anatomically informed spatial reasoning. MATEX synergistically combines multi-layer attention rollout, text-guided spatial priors, and layer consistency analysis to produce precise, stable, and clinically meaningful gradient attribution maps. By addressing key limitations of prior methods, such as spatial imprecision, lack of anatomical grounding, and limited attention granularity, MATEX enables more faithful and interpretable model explanations. Evaluated on the MS-CXR dataset, MATEX outperforms the state-of-the-art M2IB approach in both spatial precision and alignment with expert-annotated findings. These results highlight MATEX's potential to enhance trust and transparency in radiological AI applications.
Predicting When to Trust Vision-Language Models for Spatial Reasoning
Jan 14, 2026Vision-Language Models (VLMs) demonstrate impressive capabilities across multimodal tasks, yet exhibit systematic spatial reasoning failures, achieving only 49% (CLIP) to 54% (BLIP-2) accuracy on basic directional relationships. For safe deployment in robotics and autonomous systems, we need to predict when to trust VLM spatial predictions rather than accepting all outputs. We propose a vision-based confidence estimation framework that validates VLM predictions through independent geometric verification using object detection. Unlike text-based approaches relying on self-assessment, our method fuses four signals via gradient boosting: geometric alignment between VLM claims and coordinates, spatial ambiguity from overlap, detection quality, and VLM internal uncertainty. We achieve 0.674 AUROC on BLIP-2 (34.0% improvement over text-based baselines) and 0.583 AUROC on CLIP (16.1% improvement), generalizing across generative and classification architectures. Our framework enables selective prediction: at 60% target accuracy, we achieve 61.9% coverage versus 27.6% baseline (2.2x improvement) on BLIP-2. Feature analysis reveals vision-based signals contribute 87.4% of model importance versus 12.7% from VLM confidence, validating that external geometric verification outperforms self-assessment. We demonstrate reliable scene graph construction where confidence-based pruning improves precision from 52.1% to 78.3% while retaining 68.2% of edges.
Multi-Modal Interpretability for Enhanced Localization in Vision-Language Models
Sep 17, 2025Recent advances in vision-language models have significantly expanded the frontiers of automated image analysis. However, applying these models in safety-critical contexts remains challenging due to the complex relationships between objects, subtle visual cues, and the heightened demand for transparency and reliability. This paper presents the Multi-Modal Explainable Learning (MMEL) framework, designed to enhance the interpretability of vision-language models while maintaining high performance. Building upon prior work in gradient-based explanations for transformer architectures (Grad-eclip), MMEL introduces a novel Hierarchical Semantic Relationship Module that enhances model interpretability through multi-scale feature processing, adaptive attention weighting, and cross-modal alignment. Our approach processes features at multiple semantic levels to capture relationships between image regions at different granularities, applying learnable layer-specific weights to balance contributions across the model's depth. This results in more comprehensive visual explanations that highlight both primary objects and their contextual relationships with improved precision. Through extensive experiments on standard datasets, we demonstrate that by incorporating semantic relationship information into gradient-based attribution maps, MMEL produces more focused and contextually aware visualizations that better reflect how vision-language models process complex scenes. The MMEL framework generalizes across various domains, offering valuable insights into model decisions for applications requiring high interpretability and reliability.
* 8 pages, 6 figures, 3 tables
Evaluating Compositional Approaches for Focus and Sentiment Analysis
Aug 11, 2025

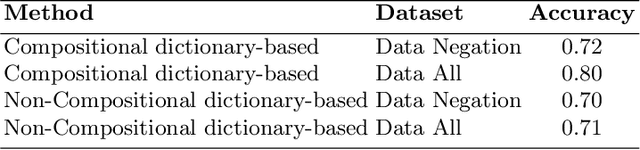

This paper summarizes the results of evaluating a compositional approach for Focus Analysis (FA) in Linguistics and Sentiment Analysis (SA) in Natural Language Processing (NLP). While quantitative evaluations of compositional and non-compositional approaches in SA exist in NLP, similar quantitative evaluations are very rare in FA in Linguistics that deal with linguistic expressions representing focus or emphasis such as "it was John who left". We fill this gap in research by arguing that compositional rules in SA also apply to FA because FA and SA are closely related meaning that SA is part of FA. Our compositional approach in SA exploits basic syntactic rules such as rules of modification, coordination, and negation represented in the formalism of Universal Dependencies (UDs) in English and applied to words representing sentiments from sentiment dictionaries. Some of the advantages of our compositional analysis method for SA in contrast to non-compositional analysis methods are interpretability and explainability. We test the accuracy of our compositional approach and compare it with a non-compositional approach VADER that uses simple heuristic rules to deal with negation, coordination and modification. In contrast to previous related work that evaluates compositionality in SA on long reviews, this study uses more appropriate datasets to evaluate compositionality. In addition, we generalize the results of compositional approaches in SA to compositional approaches in FA.
Parsing the Switch: LLM-Based UD Annotation for Complex Code-Switched and Low-Resource Languages
Jun 08, 2025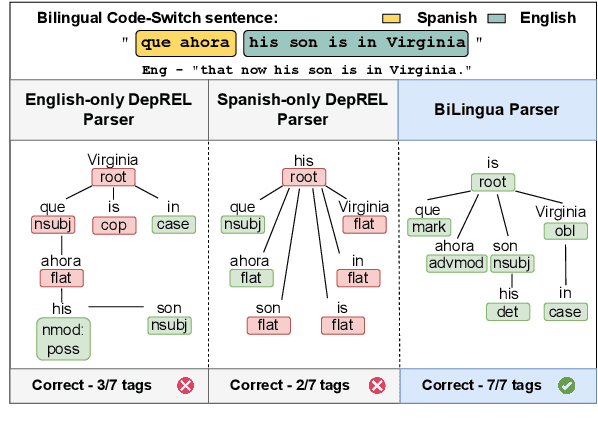
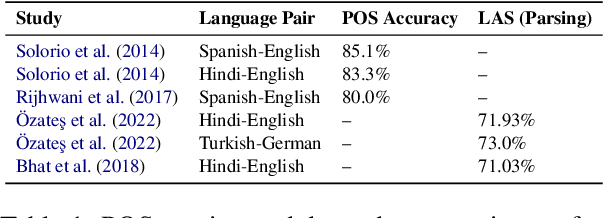
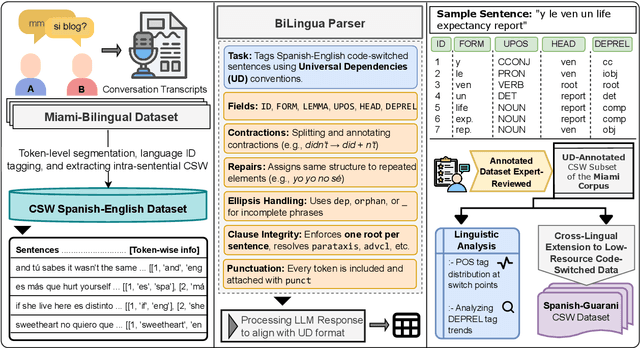
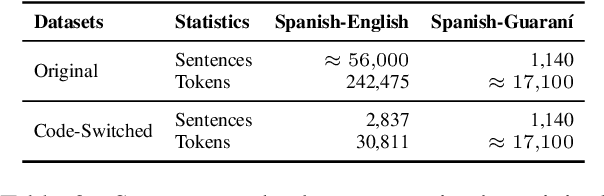
Code-switching presents a complex challenge for syntactic analysis, especially in low-resource language settings where annotated data is scarce. While recent work has explored the use of large language models (LLMs) for sequence-level tagging, few approaches systematically investigate how well these models capture syntactic structure in code-switched contexts. Moreover, existing parsers trained on monolingual treebanks often fail to generalize to multilingual and mixed-language input. To address this gap, we introduce the BiLingua Parser, an LLM-based annotation pipeline designed to produce Universal Dependencies (UD) annotations for code-switched text. First, we develop a prompt-based framework for Spanish-English and Spanish-Guaran\'i data, combining few-shot LLM prompting with expert review. Second, we release two annotated datasets, including the first Spanish-Guaran\'i UD-parsed corpus. Third, we conduct a detailed syntactic analysis of switch points across language pairs and communicative contexts. Experimental results show that BiLingua Parser achieves up to 95.29% LAS after expert revision, significantly outperforming prior baselines and multilingual parsers. These results show that LLMs, when carefully guided, can serve as practical tools for bootstrapping syntactic resources in under-resourced, code-switched environments. Data and source code are available at https://github.com/N3mika/ParsingProject
Prostate Cancer Screening with Artificial Intelligence-Enhanced Micro-Ultrasound: A Comparative Study with Traditional Methods
May 27, 2025Background and objective: Micro-ultrasound (micro-US) is a novel imaging modality with diagnostic accuracy comparable to MRI for detecting clinically significant prostate cancer (csPCa). We investigated whether artificial intelligence (AI) interpretation of micro-US can outperform clinical screening methods using PSA and digital rectal examination (DRE). Methods: We retrospectively studied 145 men who underwent micro-US guided biopsy (79 with csPCa, 66 without). A self-supervised convolutional autoencoder was used to extract deep image features from 2D micro-US slices. Random forest classifiers were trained using five-fold cross-validation to predict csPCa at the slice level. Patients were classified as csPCa-positive if 88 or more consecutive slices were predicted positive. Model performance was compared with a classifier using PSA, DRE, prostate volume, and age. Key findings and limitations: The AI-based micro-US model and clinical screening model achieved AUROCs of 0.871 and 0.753, respectively. At a fixed threshold, the micro-US model achieved 92.5% sensitivity and 68.1% specificity, while the clinical model showed 96.2% sensitivity but only 27.3% specificity. Limitations include a retrospective single-center design and lack of external validation. Conclusions and clinical implications: AI-interpreted micro-US improves specificity while maintaining high sensitivity for csPCa detection. This method may reduce unnecessary biopsies and serve as a low-cost alternative to PSA-based screening. Patient summary: We developed an AI system to analyze prostate micro-ultrasound images. It outperformed PSA and DRE in detecting aggressive cancer and may help avoid unnecessary biopsies.
Detecting Actionable Requests and Offers on Social Media During Crises Using LLMs
Apr 22, 2025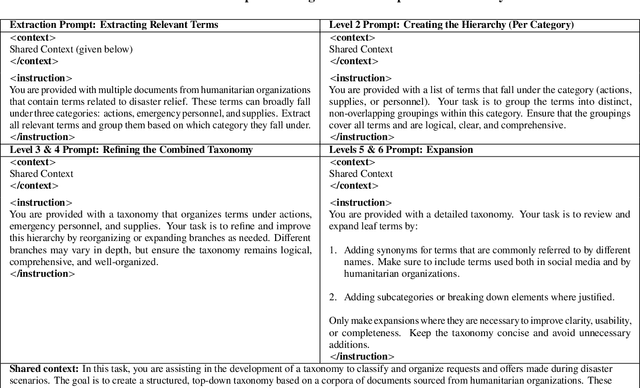
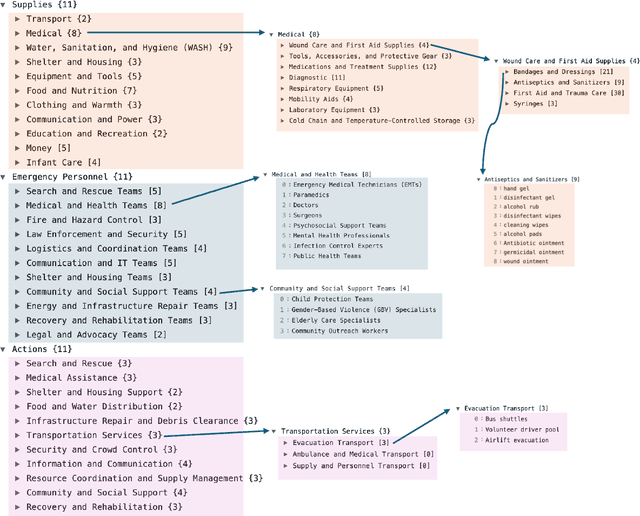

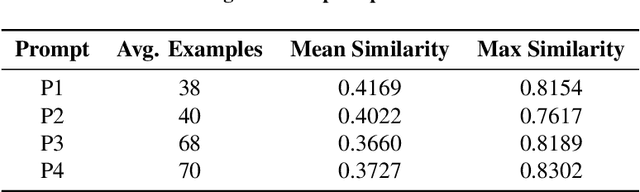
Natural disasters often result in a surge of social media activity, including requests for assistance, offers of help, sentiments, and general updates. To enable humanitarian organizations to respond more efficiently, we propose a fine-grained hierarchical taxonomy to systematically organize crisis-related information about requests and offers into three critical dimensions: supplies, emergency personnel, and actions. Leveraging the capabilities of Large Language Models (LLMs), we introduce Query-Specific Few-shot Learning (QSF Learning) that retrieves class-specific labeled examples from an embedding database to enhance the model's performance in detecting and classifying posts. Beyond classification, we assess the actionability of messages to prioritize posts requiring immediate attention. Extensive experiments demonstrate that our approach outperforms baseline prompting strategies, effectively identifying and prioritizing actionable requests and offers.
"Actionable Help" in Crises: A Novel Dataset and Resource-Efficient Models for Identifying Request and Offer Social Media Posts
Feb 24, 2025During crises, social media serves as a crucial coordination tool, but the vast influx of posts--from "actionable" requests and offers to generic content like emotional support, behavioural guidance, or outdated information--complicates effective classification. Although generative LLMs (Large Language Models) can address this issue with few-shot classification, their high computational demands limit real-time crisis response. While fine-tuning encoder-only models (e.g., BERT) is a popular choice, these models still exhibit higher inference times in resource-constrained environments. Moreover, although distilled variants (e.g., DistilBERT) exist, they are not tailored for the crisis domain. To address these challenges, we make two key contributions. First, we present CrisisHelpOffer, a novel dataset of 101k tweets collaboratively labelled by generative LLMs and validated by humans, specifically designed to distinguish actionable content from noise. Second, we introduce the first crisis-specific mini models optimized for deployment in resource-constrained settings. Across 13 crisis classification tasks, our mini models surpass BERT (also outperform or match the performance of RoBERTa, MPNet, and BERTweet), offering higher accuracy with significantly smaller sizes and faster speeds. The Medium model is 47% smaller with 3.8% higher accuracy at 3.5x speed, the Small model is 68% smaller with a 1.8% accuracy gain at 7.7x speed, and the Tiny model, 83% smaller, matches BERT's accuracy at 18.6x speed. All models outperform existing distilled variants, setting new benchmarks. Finally, as a case study, we analyze social media posts from a global crisis to explore help-seeking and assistance-offering behaviours in selected developing and developed countries.