 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Aligned, Less Diverse? Analyzing the Grammar and Lexicon of Two Generations of LLMs
May 07, 2026This study contributes to a growing line of research in comparing LLM-generated texts with human-authored text, in this case, English news text. We focus in particular on the evaluation of syntactic properties through formal grammar frameworks. Our analysis compares two generations of LLMs in the context of two human-authored English news datasets from two different years. Employing the Head-Driven Phrase Structure Grammar (HPSG) formalism, we investigate the distributions of syntactic structures and lexical types of AI-generated texts and contrast them with the corresponding distributions in the human-authored New York Times (NYT) articles. We use diversity metrics from ecology and information theory to quantify variation in grammatical constructions and lexical types. We show that English news text has changed little in the given time frame, while newer LLMs display reduced syntactic and, especially, lexical diversity compared to older, non-instruction-tuned models. These findings point to future work in studying effects of instruction tuning, which, while enhancing coherence and adherence to prompts, may narrow the expressive range of model output.
HEAD-QA v2: Expanding a Healthcare Benchmark for Reasoning
Nov 19, 2025We introduce HEAD-QA v2, an expanded and updated version of a Spanish/English healthcare multiple-choice reasoning dataset originally released by Vilares and Gómez-Rodríguez (2019). The update responds to the growing need for high-quality datasets that capture the linguistic and conceptual complexity of healthcare reasoning. We extend the dataset to over 12,000 questions from ten years of Spanish professional exams, benchmark several open-source LLMs using prompting, RAG, and probability-based answer selection, and provide additional multilingual versions to support future work. Results indicate that performance is mainly driven by model scale and intrinsic reasoning ability, with complex inference strategies obtaining limited gains. Together, these results establish HEAD-QA v2 as a reliable resource for advancing research on biomedical reasoning and model improvement.
Hierarchical Bracketing Encodings Work for Dependency Graphs
Sep 11, 2025We revisit hierarchical bracketing encodings from a practical perspective in the context of dependency graph parsing. The approach encodes graphs as sequences, enabling linear-time parsing with $n$ tagging actions, and still representing reentrancies, cycles, and empty nodes. Compared to existing graph linearizations, this representation substantially reduces the label space while preserving structural information. We evaluate it on a multilingual and multi-formalism benchmark, showing competitive results and consistent improvements over other methods in exact match accuracy.
Evaluating Compositional Approaches for Focus and Sentiment Analysis
Aug 11, 2025

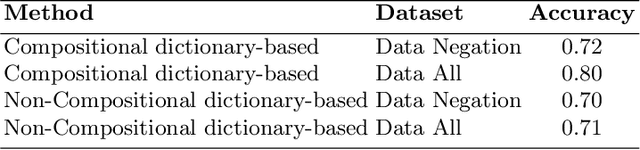

This paper summarizes the results of evaluating a compositional approach for Focus Analysis (FA) in Linguistics and Sentiment Analysis (SA) in Natural Language Processing (NLP). While quantitative evaluations of compositional and non-compositional approaches in SA exist in NLP, similar quantitative evaluations are very rare in FA in Linguistics that deal with linguistic expressions representing focus or emphasis such as "it was John who left". We fill this gap in research by arguing that compositional rules in SA also apply to FA because FA and SA are closely related meaning that SA is part of FA. Our compositional approach in SA exploits basic syntactic rules such as rules of modification, coordination, and negation represented in the formalism of Universal Dependencies (UDs) in English and applied to words representing sentiments from sentiment dictionaries. Some of the advantages of our compositional analysis method for SA in contrast to non-compositional analysis methods are interpretability and explainability. We test the accuracy of our compositional approach and compare it with a non-compositional approach VADER that uses simple heuristic rules to deal with negation, coordination and modification. In contrast to previous related work that evaluates compositionality in SA on long reviews, this study uses more appropriate datasets to evaluate compositionality. In addition, we generalize the results of compositional approaches in SA to compositional approaches in FA.
Parsing the Switch: LLM-Based UD Annotation for Complex Code-Switched and Low-Resource Languages
Jun 08, 2025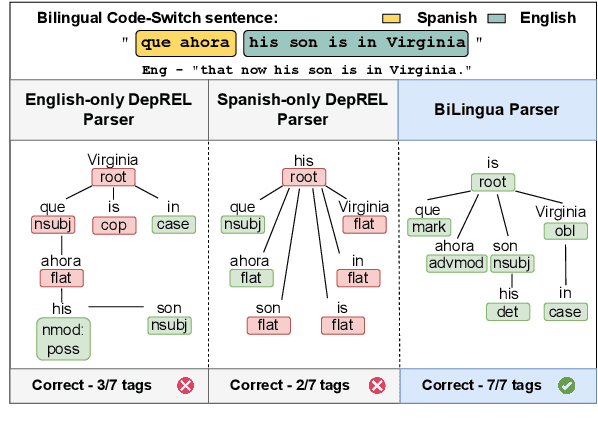
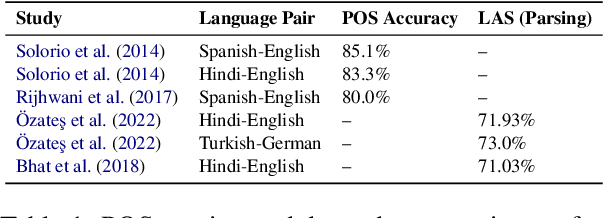
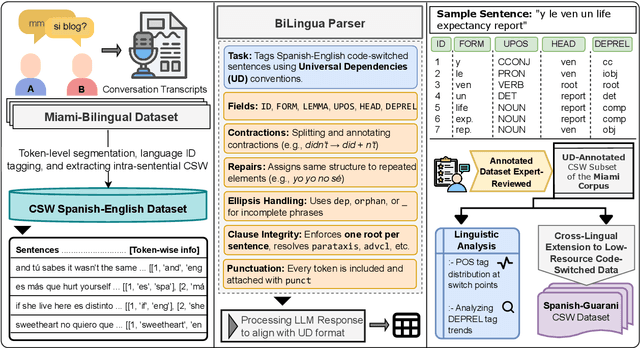
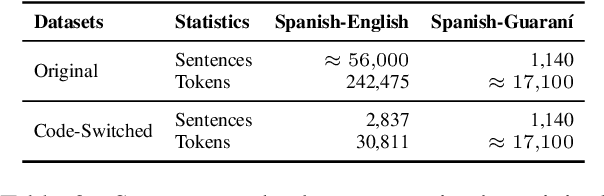
Code-switching presents a complex challenge for syntactic analysis, especially in low-resource language settings where annotated data is scarce. While recent work has explored the use of large language models (LLMs) for sequence-level tagging, few approaches systematically investigate how well these models capture syntactic structure in code-switched contexts. Moreover, existing parsers trained on monolingual treebanks often fail to generalize to multilingual and mixed-language input. To address this gap, we introduce the BiLingua Parser, an LLM-based annotation pipeline designed to produce Universal Dependencies (UD) annotations for code-switched text. First, we develop a prompt-based framework for Spanish-English and Spanish-Guaran\'i data, combining few-shot LLM prompting with expert review. Second, we release two annotated datasets, including the first Spanish-Guaran\'i UD-parsed corpus. Third, we conduct a detailed syntactic analysis of switch points across language pairs and communicative contexts. Experimental results show that BiLingua Parser achieves up to 95.29% LAS after expert revision, significantly outperforming prior baselines and multilingual parsers. These results show that LLMs, when carefully guided, can serve as practical tools for bootstrapping syntactic resources in under-resourced, code-switched environments. Data and source code are available at https://github.com/N3mika/ParsingProject
Nested Named Entity Recognition as Single-Pass Sequence Labeling
May 22, 2025We cast nested named entity recognition (NNER) as a sequence labeling task by leveraging prior work that linearizes constituency structures, effectively reducing the complexity of this structured prediction problem to straightforward token classification. By combining these constituency linearizations with pretrained encoders, our method captures nested entities while performing exactly $n$ tagging actions. Our approach achieves competitive performance compared to less efficient systems, and it can be trained using any off-the-shelf sequence labeling library.
Hierarchical Bracketing Encodings for Dependency Parsing as Tagging
May 16, 2025We present a family of encodings for sequence labeling dependency parsing, based on the concept of hierarchical bracketing. We prove that the existing 4-bit projective encoding belongs to this family, but it is suboptimal in the number of labels used to encode a tree. We derive an optimal hierarchical bracketing, which minimizes the number of symbols used and encodes projective trees using only 12 distinct labels (vs. 16 for the 4-bit encoding). We also extend optimal hierarchical bracketing to support arbitrary non-projectivity in a more compact way than previous encodings. Our new encodings yield competitive accuracy on a diverse set of treebanks.
Better Benchmarking LLMs for Zero-Shot Dependency Parsing
Feb 28, 2025While LLMs excel in zero-shot tasks, their performance in linguistic challenges like syntactic parsing has been less scrutinized. This paper studies state-of-the-art open-weight LLMs on the task by comparing them to baselines that do not have access to the input sentence, including baselines that have not been used in this context such as random projective trees or optimal linear arrangements. The results show that most of the tested LLMs cannot outperform the best uninformed baselines, with only the newest and largest versions of LLaMA doing so for most languages, and still achieving rather low performance. Thus, accurate zero-shot syntactic parsing is not forthcoming with open LLMs.
Grandes modelos de lenguaje: de la predicción de palabras a la comprensión?
Feb 25, 2025Large language models, such as the well-known ChatGPT, have brought about an unexpected revolution in the field of artificial intelligence. On the one hand, they have numerous practical applications and enormous potential still to be explored. On the other hand, they are also the subject of debate from scientific, philosophical, and social perspectives: there are doubts about the exact mechanisms of their functioning and their actual capacity for language comprehension, and their applications raise ethical dilemmas. In this chapter, we describe how this technology has been developed and the fundamentals of its operation, allowing us to better understand its capabilities and limitations and to introduce some of the main debates surrounding its development and use. -- Los grandes modelos de lenguaje, como el conocido ChatGPT, han supuesto una inesperada revoluci\'on en el \'ambito de la inteligencia artificial. Por un lado, cuentan con multitud de aplicaciones pr\'acticas y un enorme potencial todav\'ia por explorar. Por otro lado, son tambi\'en objeto de debate, tanto desde el punto de vista cient\'ifico y filos\'ofico como social: hay dudas sobre los mecanismos exactos de su funcionamiento y su capacidad real de comprensi\'on del lenguaje, y sus aplicaciones plantean dilemas \'eticos. En este cap\'itulo describimos c\'omo se ha llegado a esta tecnolog\'ia y los fundamentos de su funcionamiento, permiti\'endonos as\'i comprender mejor sus capacidades y limitaciones e introducir algunos de los principales debates que rodean su desarrollo y uso.
* 26 pages, in Spanish. Chapter from book "La Inteligencia Artificial hoy y sus aplicaciones con Big Data", (Amparo Alonso Betanzos, Daniel Pe\~na y Pilar Poncela, eds.). Publisher: Funcas. ISBN 978-84-17609-94-8
Dependency Graph Parsing as Sequence Labeling
Oct 23, 2024
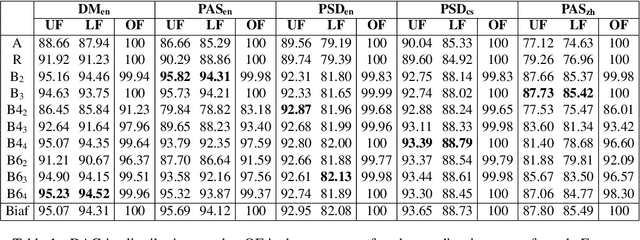
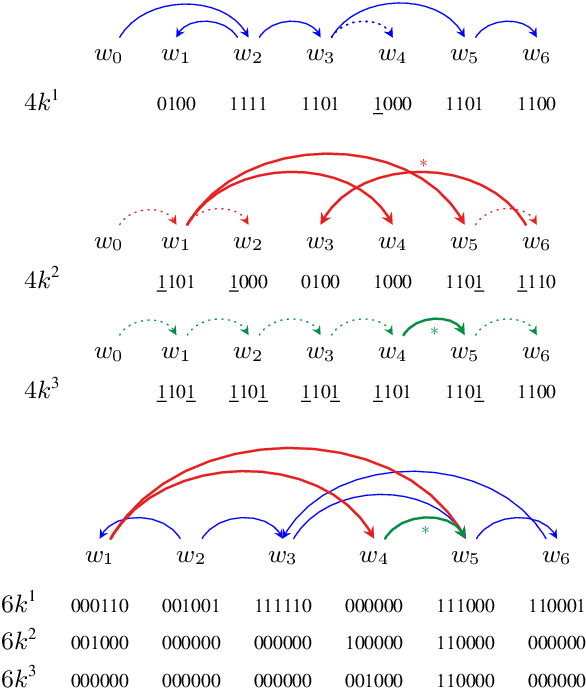

Various linearizations have been proposed to cast syntactic dependency parsing as sequence labeling. However, these approaches do not support more complex graph-based representations, such as semantic dependencies or enhanced universal dependencies, as they cannot handle reentrancy or cycles. By extending them, we define a range of unbounded and bounded linearizations that can be used to cast graph parsing as a tagging task, enlarging the toolbox of problems that can be solved under this paradigm. Experimental results on semantic dependency and enhanced UD parsing show that with a good choice of encoding, sequence-labeling dependency graph parsers combine high efficiency with accuracies close to the state of the art, in spite of their simplicity.