 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Named Entity Recognition as Single-Pass Sequence Labeling
May 22, 2025We cast nested named entity recognition (NNER) as a sequence labeling task by leveraging prior work that linearizes constituency structures, effectively reducing the complexity of this structured prediction problem to straightforward token classification. By combining these constituency linearizations with pretrained encoders, our method captures nested entities while performing exactly $n$ tagging actions. Our approach achieves competitive performance compared to less efficient systems, and it can be trained using any off-the-shelf sequence labeling library.
Evaluating Pixel Language Models on Non-Standardized Languages
Dec 12, 2024
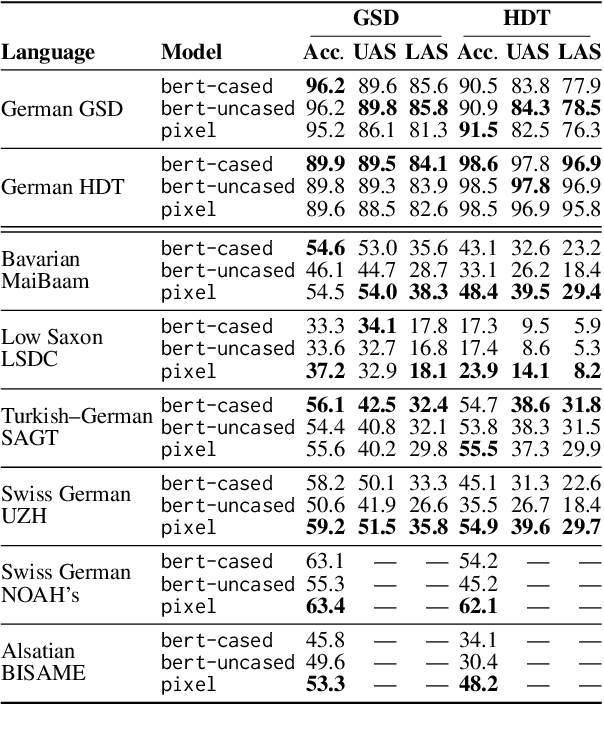

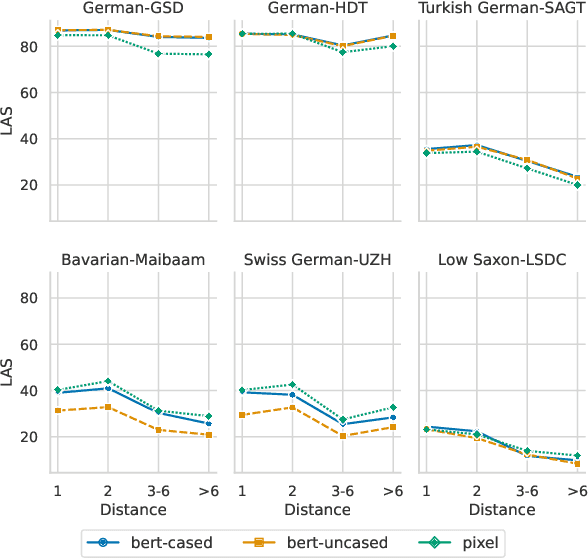
We explore the potential of pixel-based models for transfer learning from standard languages to dialects. These models convert text into images that are divided into patches, enabling a continuous vocabulary representation that proves especially useful for out-of-vocabulary words common in dialectal data. Using German as a case study, we compare the performance of pixel-based models to token-based models across various syntactic and semantic tasks. Our results show that pixel-based models outperform token-based models in part-of-speech tagging, dependency parsing and intent detection for zero-shot dialect evaluation by up to 26 percentage points in some scenarios, though not in Standard German. However, pixel-based models fall short in topic classification. These findings emphasize the potential of pixel-based models for handling dialectal data, though further research should be conducted to assess their effectiveness in various linguistic contexts.
Assessment of Pre-Trained Models Across Languages and Grammars
Sep 20, 2023We present an approach for assessing how multilingual large language models (LLMs) learn syntax in terms of multi-formalism syntactic structures. We aim to recover constituent and dependency structures by casting parsing as sequence labeling. To do so, we select a few LLMs and study them on 13 diverse UD treebanks for dependency parsing and 10 treebanks for constituent parsing. Our results show that: (i) the framework is consistent across encodings, (ii) pre-trained word vectors do not favor constituency representations of syntax over dependencies, (iii) sub-word tokenization is needed to represent syntax, in contrast to character-based models, and (iv) occurrence of a language in the pretraining data is more important than the amount of task data when recovering syntax from the word vectors.
Contrasting Linguistic Patterns in Human and LLM-Generated Text
Aug 17, 2023We conduct a quantitative analysis contrasting human-written English news text with comparable large language model (LLM) output from 4 LLMs from the LLaMa family. Our analysis spans several measurable linguistic dimensions, including morphological, syntactic, psychometric and sociolinguistic aspects. The results reveal various measurable differences between human and AI-generated texts. Among others, human texts exhibit more scattered sentence length distributions, a distinct use of dependency and constituent types, shorter constituents, and more aggressive emotions (fear, disgust) than LLM-generated texts. LLM outputs use more numbers, symbols and auxiliaries (suggesting objective language) than human texts, as well as more pronouns. The sexist bias prevalent in human text is also expressed by LLMs.
Another Dead End for Morphological Tags? Perturbed Inputs and Parsing
May 24, 2023The usefulness of part-of-speech tags for parsing has been heavily questioned due to the success of word-contextualized parsers. Yet, most studies are limited to coarse-grained tags and high quality written content; while we know little about their influence when it comes to models in production that face lexical errors. We expand these setups and design an adversarial attack to verify if the use of morphological information by parsers: (i) contributes to error propagation or (ii) if on the other hand it can play a role to correct mistakes that word-only neural parsers make. The results on 14 diverse UD treebanks show that under such attacks, for transition- and graph-based models their use contributes to degrade the performance even faster, while for the (lower-performing) sequence labeling parsers they are helpful. We also show that if morphological tags were utopically robust against lexical perturbations, they would be able to correct parsing mistakes.
Parsing linearizations appreciate PoS tags - but some are fussy about errors
Oct 27, 2022PoS tags, once taken for granted as a useful resource for syntactic parsing, have become more situational with the popularization of deep learning. Recent work on the impact of PoS tags on graph- and transition-based parsers suggests that they are only useful when tagging accuracy is prohibitively high, or in low-resource scenarios. However, such an analysis is lacking for the emerging sequence labeling parsing paradigm, where it is especially relevant as some models explicitly use PoS tags for encoding and decoding. We undertake a study and uncover some trends. Among them, PoS tags are generally more useful for sequence labeling parsers than for other paradigms, but the impact of their accuracy is highly encoding-dependent, with the PoS-based head-selection encoding being best only when both tagging accuracy and resource availability are high.
Cross-lingual Inflection as a Data Augmentation Method for Parsing
May 20, 2022



We propose a morphology-based method for low-resource (LR) dependency parsing. We train a morphological inflector for target LR languages, and apply it to related rich-resource (RR) treebanks to create cross-lingual (x-inflected) treebanks that resemble the target LR language. We use such inflected treebanks to train parsers in zero- (training on x-inflected treebanks) and few-shot (training on x-inflected and target language treebanks) setups. The results show that the method sometimes improves the baselines, but not consistently.
Not All Linearizations Are Equally Data-Hungry in Sequence Labeling Parsing
Aug 17, 2021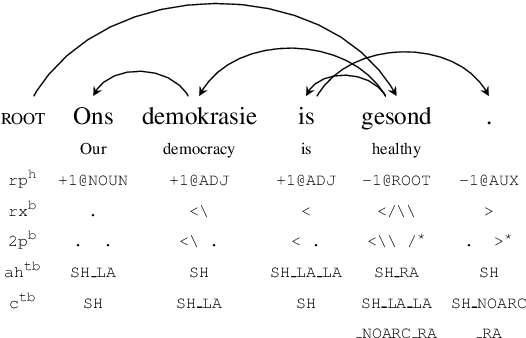



Different linearizations have been proposed to cast dependency parsing as sequence labeling and solve the task as: (i) a head selection problem, (ii) finding a representation of the token arcs as bracket strings, or (iii) associating partial transition sequences of a transition-based parser to words. Yet, there is little understanding about how these linearizations behave in low-resource setups. Here, we first study their data efficiency, simulating data-restricted setups from a diverse set of rich-resource treebanks. Second, we test whether such differences manifest in truly low-resource setups. The results show that head selection encodings are more data-efficient and perform better in an ideal (gold) framework, but that such advantage greatly vanishes in favour of bracketing formats when the running setup resembles a real-world low-resource configuration.