 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Low-Rank Adaptation Under Demographic Privacy Constraints
Mar 07, 2025Pre-trained foundation models can be adapted for specific tasks using Low-Rank Adaptation (LoRA). However, the fairness properties of these adapted classifiers remain underexplored. Existing fairness-aware fine-tuning methods rely on direct access to sensitive attributes or their predictors, but in practice, these sensitive attributes are often held under strict consumer privacy controls, and neither the attributes nor their predictors are available to model developers, hampering the development of fair models. To address this issue, we introduce a set of LoRA-based fine-tuning methods that can be trained in a distributed fashion, where model developers and fairness auditors collaborate without sharing sensitive attributes or predictors. In this paper, we evaluate three such methods - sensitive unlearning, adversarial training, and orthogonality loss - against a fairness-unaware baseline, using experiments on the CelebA and UTK-Face datasets with an ImageNet pre-trained ViT-Base model. We find that orthogonality loss consistently reduces bias while maintaining or improving utility, whereas adversarial training improves False Positive Rate Parity and Demographic Parity in some cases, and sensitive unlearning provides no clear benefit. In tasks where significant biases are present, distributed fairness-aware fine-tuning methods can effectively eliminate bias without compromising consumer privacy and, in most cases, improve model utility.
Neural Text Sanitization with Privacy Risk Indicators: An Empirical Analysis
Oct 22, 2023Text sanitization is the task of redacting a document to mask all occurrences of (direct or indirect) personal identifiers, with the goal of concealing the identity of the individual(s) referred in it. In this paper, we consider a two-step approach to text sanitization and provide a detailed analysis of its empirical performance on two recently published datasets: the Text Anonymization Benchmark (Pil\'an et al., 2022) and a collection of Wikipedia biographies (Papadopoulou et al., 2022). The text sanitization process starts with a privacy-oriented entity recognizer that seeks to determine the text spans expressing identifiable personal information. This privacy-oriented entity recognizer is trained by combining a standard named entity recognition model with a gazetteer populated by person-related terms extracted from Wikidata. The second step of the text sanitization process consists in assessing the privacy risk associated with each detected text span, either isolated or in combination with other text spans. We present five distinct indicators of the re-identification risk, respectively based on language model probabilities, text span classification, sequence labelling, perturbations, and web search. We provide a contrastive analysis of each privacy indicator and highlight their benefits and limitations, notably in relation to the available labeled data.
Learnable Frontends that do not Learn: Quantifying Sensitivity to Filterbank Initialisation
Feb 20, 2023



While much of modern speech and audio processing relies on deep neural networks trained using fixed audio representations, recent studies suggest great potential in acoustic frontends learnt jointly with a backend. In this study, we focus specifically on learnable filterbanks. Prior studies have reported that in frontends using learnable filterbanks initialised to a mel scale, the learned filters do not differ substantially from their initialisation. Using a Gabor-based filterbank, we investigate the sensitivity of a learnable filterbank to its initialisation using several initialisation strategies on two audio tasks: voice activity detection and bird species identification. We use the Jensen-Shannon Distance and analysis of the learned filters before and after training. We show that although performance is overall improved, the filterbanks exhibit strong sensitivity to their initialisation strategy. The limited movement from initialised values suggests that alternate optimisation strategies may allow a learnable frontend to reach better overall performance.
Parsing linearizations appreciate PoS tags - but some are fussy about errors
Oct 27, 2022PoS tags, once taken for granted as a useful resource for syntactic parsing, have become more situational with the popularization of deep learning. Recent work on the impact of PoS tags on graph- and transition-based parsers suggests that they are only useful when tagging accuracy is prohibitively high, or in low-resource scenarios. However, such an analysis is lacking for the emerging sequence labeling parsing paradigm, where it is especially relevant as some models explicitly use PoS tags for encoding and decoding. We undertake a study and uncover some trends. Among them, PoS tags are generally more useful for sequence labeling parsers than for other paradigms, but the impact of their accuracy is highly encoding-dependent, with the PoS-based head-selection encoding being best only when both tagging accuracy and resource availability are high.
Learnable Acoustic Frontends in Bird Activity Detection
Oct 03, 2022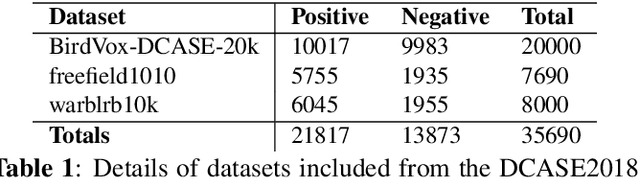
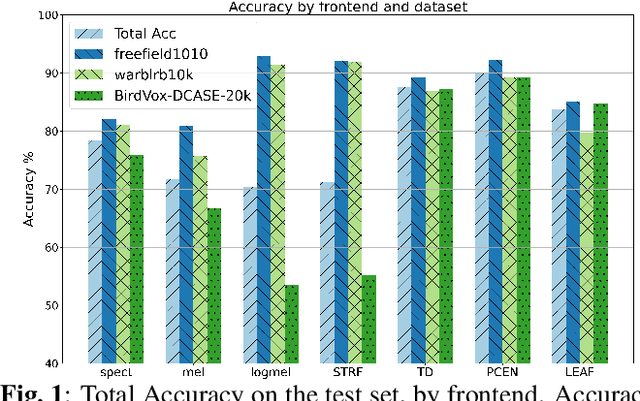

Autonomous recording units and passive acoustic monitoring present minimally intrusive methods of collecting bioacoustics data. Combining this data with species agnostic bird activity detection systems enables the monitoring of activity levels of bird populations. Unfortunately, variability in ambient noise levels and subject distance contribute to difficulties in accurately detecting bird activity in recordings. The choice of acoustic frontend directly affects the impact these issues have on system performance. In this paper, we benchmark traditional fixed-parameter acoustic frontends against the new generation of learnable frontends on a wide-ranging bird audio detection task using data from the DCASE2018 BAD Challenge. We observe that Per-Channel Energy Normalization is the best overall performer, achieving an accuracy of 89.9%, and that in general learnable frontends significantly outperform traditional methods. We also identify challenges in learning filterbanks for bird audio.
The Impact of Edge Displacement Vaserstein Distance on UD Parsing Performance
Sep 15, 2022We contribute to the discussion on parsing performance in NLP by introducing a measurement that evaluates the differences between the distributions of edge displacement (the directed distance of edges) seen in training and test data. We hypothesize that this measurement will be related to differences observed in parsing performance across treebanks. We motivate this by building upon previous work and then attempt to falsify this hypothesis by using a number of statistical methods. We establish that there is a statistical correlation between this measurement and parsing performance even when controlling for potential covariants. We then use this to establish a sampling technique that gives us an adversarial and complementary split. This gives an idea of the lower and upper bounds of parsing systems for a given treebank in lieu of freshly sampled data. In a broader sense, the methodology presented here can act as a reference for future correlation-based exploratory work in NLP.
* This is the final peer-reviewed manuscript accepted for publication in Computational Linguistics. The journal version with the final editorial and typesetting changes is available open-access at https://doi.org/10.1162/coli_a_00440
Assessing the Limits of the Distributional Hypothesis in Semantic Spaces: Trait-based Relational Knowledge and the Impact of Co-occurrences
May 16, 2022
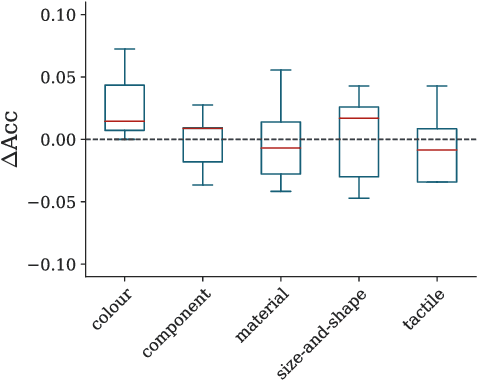
The increase in performance in NLP due to the prevalence of distributional models and deep learning has brought with it a reciprocal decrease in interpretability. This has spurred a focus on what neural networks learn about natural language with less of a focus on how. Some work has focused on the data used to develop data-driven models, but typically this line of work aims to highlight issues with the data, e.g. highlighting and offsetting harmful biases. This work contributes to the relatively untrodden path of what is required in data for models to capture meaningful representations of natural language. This entails evaluating how well English and Spanish semantic spaces capture a particular type of relational knowledge, namely the traits associated with concepts (e.g. bananas-yellow), and exploring the role of co-occurrences in this context.
Low Resource Species Agnostic Bird Activity Detection
Dec 16, 2021



This paper explores low resource classifiers and features for the detection of bird activity, suitable for embedded Automatic Recording Units which are typically deployed for long term remote monitoring of bird populations. Features include low-level spectral parameters, statistical moments on pitch samples, and features derived from amplitude modulation. Performance is evaluated on several lightweight classifiers using the NIPS4Bplus dataset. Our experiments show that random forest classifiers perform best on this task, achieving an accuracy of 0.721 and an F1-Score of 0.604. We compare the results of our system against both a Convolutional Neural Network based detector, and standard MFCC features. Our experiments show that we can achieve equal or better performance in most metrics using features and models with a smaller computational cost and which are suitable for edge deployment.
* This paper is accepted and presented at the IEEE Workshop on Signal Processing Systems (SiPS) October 2021, 3 Figures, 5 Tables
Bioacoustic Event Detection with prototypical networks and data augmentation
Dec 16, 2021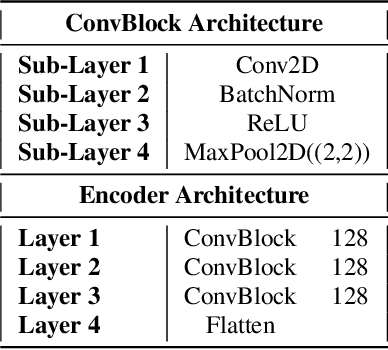
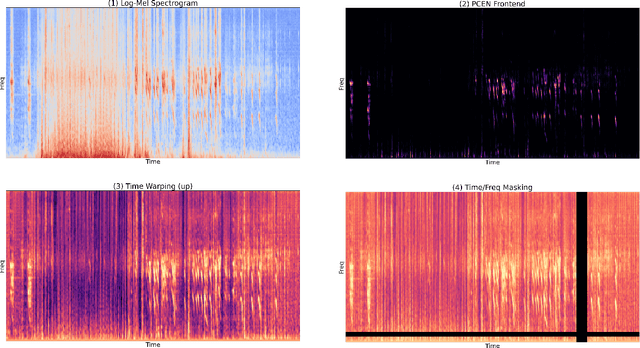
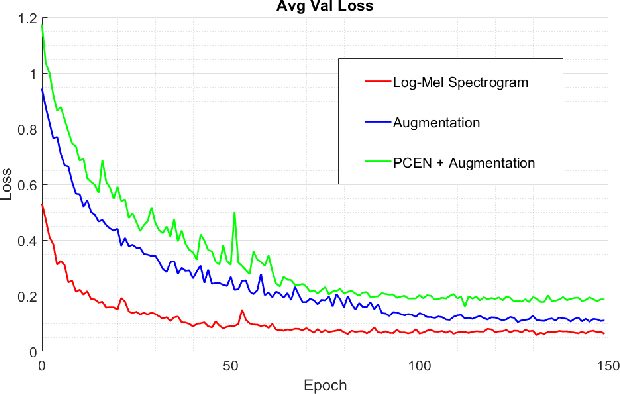
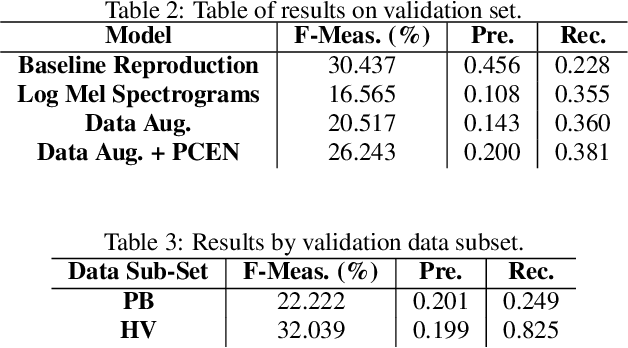
This report presents deep learning and data augmentation techniques used by a system entered into the Few-Shot Bioacoustic Event Detection for the DCASE2021 Challenge. The remit was to develop a few-shot learning system for animal (mammal and bird) vocalisations. Participants were tasked with developing a method that can extract information from five exemplar vocalisations, or shots, of mammals or birds and detect and classify sounds in field recordings. In the system described in this report, prototypical networks are used to learn a metric space, from which classification is performed by computing the distance of a query point to class prototypes, classifying based on shortest distance. We describe the architecture of this network, feature extraction methods, and data augmentation performed on the given dataset and compare our work to the challenge's baseline networks.
Learning from learning machines: a new generation of AI technology to meet the needs of science
Nov 27, 2021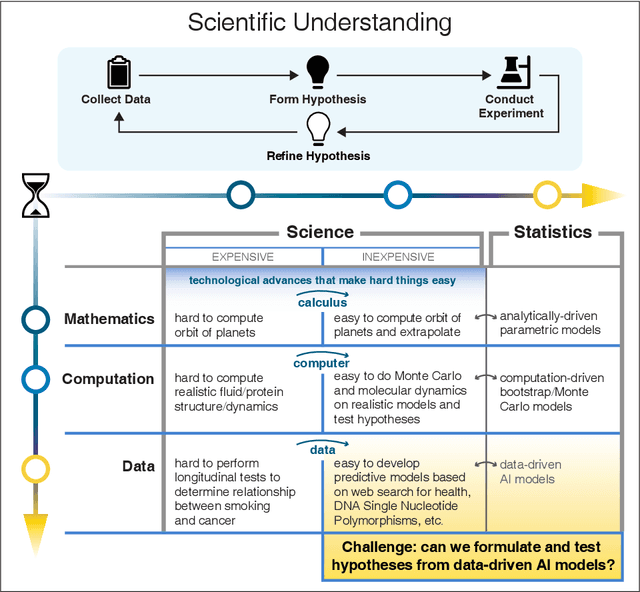

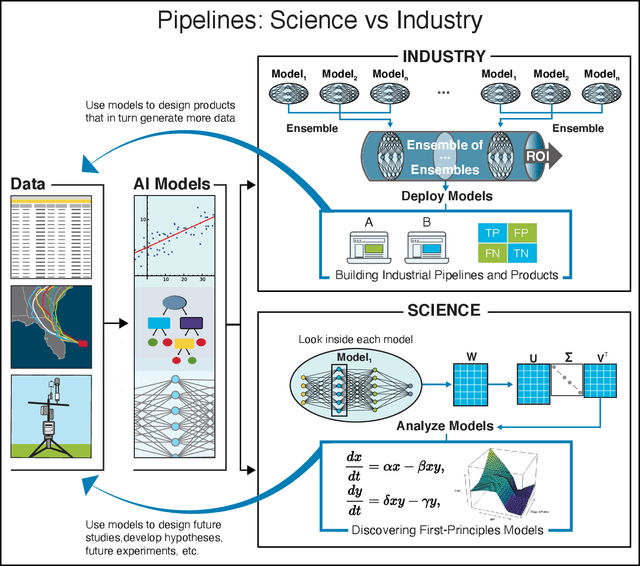
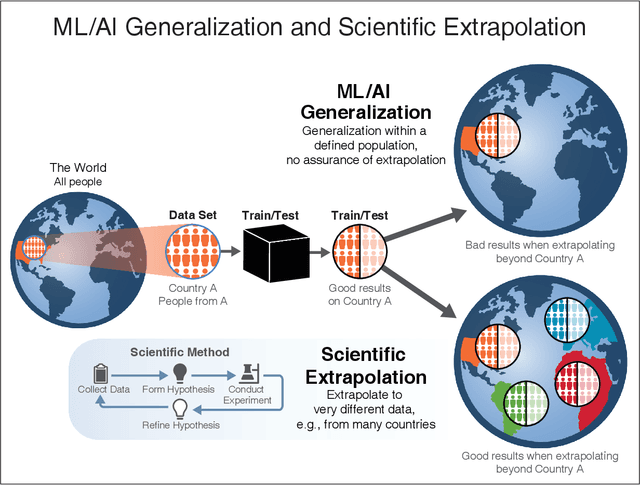
We outline emerging opportunities and challenges to enhance the utility of AI for scientific discovery. The distinct goals of AI for industry versus the goals of AI for science create tension between identifying patterns in data versus discovering patterns in the world from data. If we address the fundamental challenges associated with "bridging the gap" between domain-driven scientific models and data-driven AI learning machines, then we expect that these AI models can transform hypothesis generation, scientific discovery, and the scientific process itself.