 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Differentially Private Power Method
Jul 30, 2025We propose a novel Decentralized Differentially Private Power Method (D-DP-PM) for performing Principal Component Analysis (PCA) in networked multi-agent settings. Unlike conventional decentralized PCA approaches where each agent accesses the full n-dimensional sample space, we address the challenging scenario where each agent observes only a subset of dimensions through row-wise data partitioning. Our method ensures $(\epsilon,\delta)$-Differential Privacy (DP) while enabling collaborative estimation of global eigenvectors across the network without requiring a central aggregator. We achieve this by having agents share only local embeddings of the current eigenvector iterate, leveraging both the inherent privacy from random initialization and carefully calibrated Gaussian noise additions. We prove that our algorithm satisfies the prescribed $(\epsilon,\delta)$-DP guarantee and establish convergence rates that explicitly characterize the impact of the network topology. Our theoretical analysis, based on linear dynamics and high-dimensional probability theory, provides tight bounds on both privacy and utility. Experiments on real-world datasets demonstrate that D-DP-PM achieves superior privacy-utility tradeoffs compared to naive local DP approaches, with particularly strong performance in moderate privacy regimes ($\epsilon\in[2, 5]$). The method converges rapidly, allowing practitioners to trade iterations for enhanced privacy while maintaining competitive utility.
Preserving Smart Grid Integrity: A Differential Privacy Framework for Secure Detection of False Data Injection Attacks in the Smart Grid
Mar 04, 2024In this paper, we present a framework based on differential privacy (DP) for querying electric power measurements to detect system anomalies or bad data caused by false data injections (FDIs). Our DP approach conceals consumption and system matrix data, while simultaneously enabling an untrusted third party to test hypotheses of anomalies, such as an FDI attack, by releasing a randomized sufficient statistic for hypothesis-testing. We consider a measurement model corrupted by Gaussian noise and a sparse noise vector representing the attack, and we observe that the optimal test statistic is a chi-square random variable. To detect possible attacks, we propose a novel DP chi-square noise mechanism that ensures the test does not reveal private information about power injections or the system matrix. The proposed framework provides a robust solution for detecting FDIs while preserving the privacy of sensitive power system data.
Differential Privacy for Class-based Data: A Practical Gaussian Mechanism
Jun 08, 2023



In this paper, we present a notion of differential privacy (DP) for data that comes from different classes. Here, the class-membership is private information that needs to be protected. The proposed method is an output perturbation mechanism that adds noise to the release of query response such that the analyst is unable to infer the underlying class-label. The proposed DP method is capable of not only protecting the privacy of class-based data but also meets quality metrics of accuracy and is computationally efficient and practical. We illustrate the efficacy of the proposed method empirically while outperforming the baseline additive Gaussian noise mechanism. We also examine a real-world application and apply the proposed DP method to the autoregression and moving average (ARMA) forecasting method, protecting the privacy of the underlying data source. Case studies on the real-world advanced metering infrastructure (AMI) measurements of household power consumption validate the excellent performance of the proposed DP method while also satisfying the accuracy of forecasted power consumption measurements.
Solar Photovoltaic Systems Metadata Inference and Differentially Private Publication
Apr 07, 2023Stakeholders in electricity delivery infrastructure are amassing data about their system demand, use, and operations. Still, they are reluctant to share them, as even sharing aggregated or anonymized electric grid data risks the disclosure of sensitive information. This paper highlights how applying differential privacy to distributed energy resource production data can preserve the usefulness of that data for operations, planning, and research purposes without violating privacy constraints. Differentially private mechanisms can be optimized for queries of interest in the energy sector, with provable privacy and accuracy trade-offs, and can help design differentially private databases for further analysis and research. In this paper, we consider the problem of inference and publication of solar photovoltaic systems' metadata. Metadata such as nameplate capacity, surface azimuth and surface tilt may reveal personally identifiable information regarding the installation behind-the-meter. We describe a methodology to infer the metadata and propose a mechanism based on Bayesian optimization to publish the inferred metadata in a differentially private manner. The proposed mechanism is numerically validated using real-world solar power generation data.
Differentially Private $K$-means Clustering Applied to Meter Data Analysis and Synthesis
Dec 07, 2021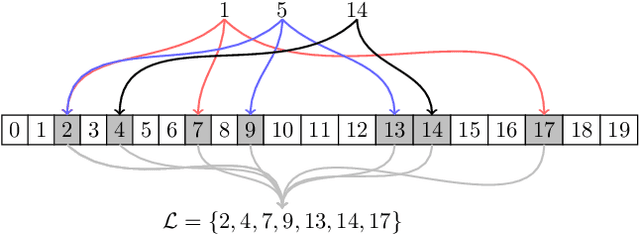
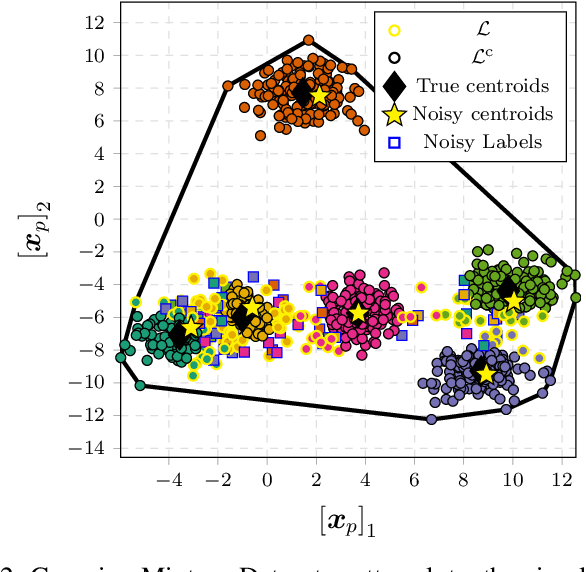
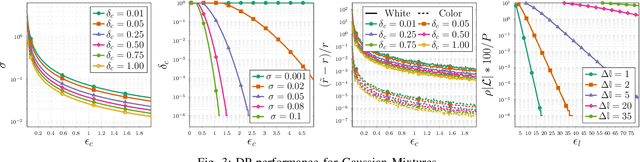
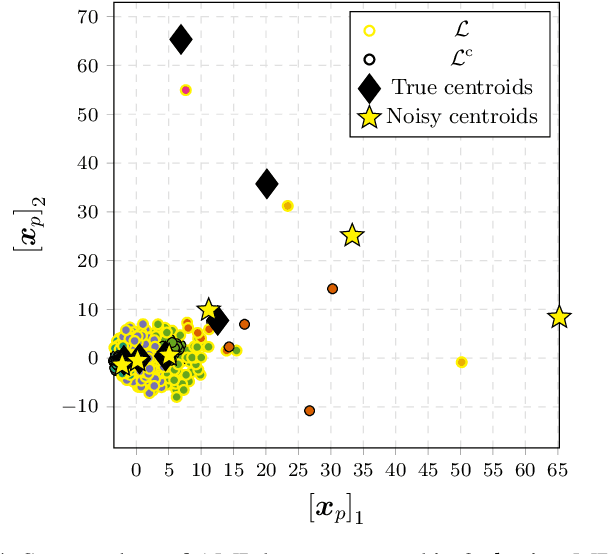
The proliferation of smart meters has resulted in a large amount of data being generated. It is increasingly apparent that methods are required for allowing a variety of stakeholders to leverage the data in a manner that preserves the privacy of the consumers. The sector is scrambling to define policies, such as the so called '15/15 rule', to respond to the need. However, the current policies fail to adequately guarantee privacy. In this paper, we address the problem of allowing third parties to apply $K$-means clustering, obtaining customer labels and centroids for a set of load time series by applying the framework of differential privacy. We leverage the method to design an algorithm that generates differentially private synthetic load data consistent with the labeled data. We test our algorithm's utility by answering summary statistics such as average daily load profiles for a 2-dimensional synthetic dataset and a real-world power load dataset.
Learning from learning machines: a new generation of AI technology to meet the needs of science
Nov 27, 2021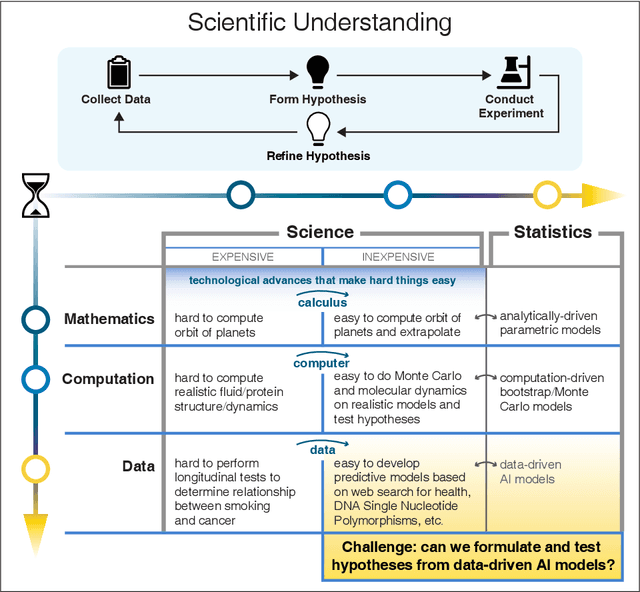

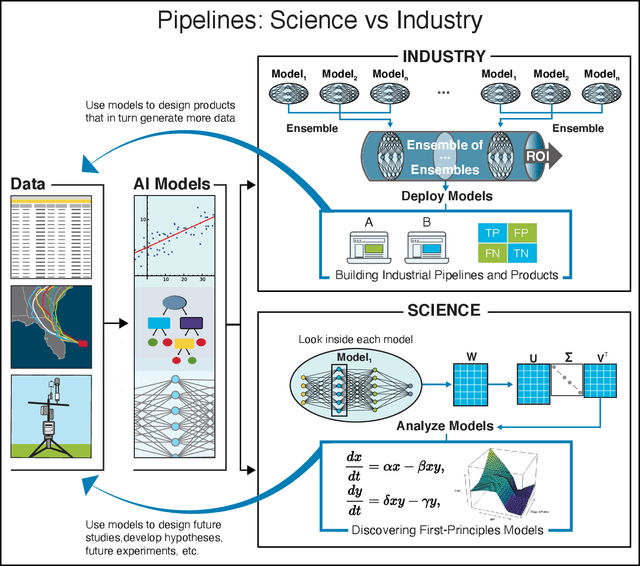
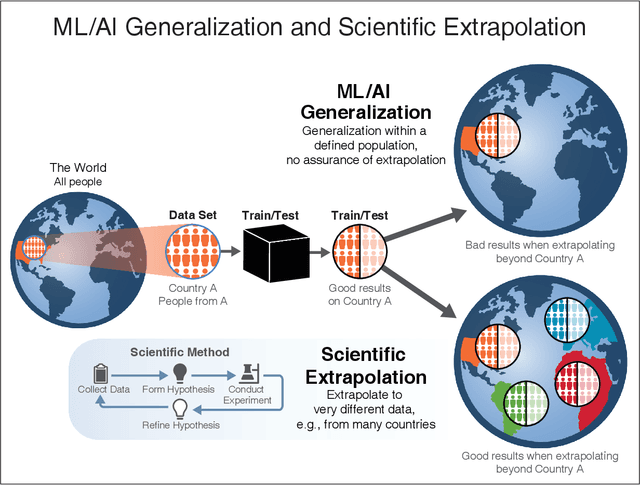
We outline emerging opportunities and challenges to enhance the utility of AI for scientific discovery. The distinct goals of AI for industry versus the goals of AI for science create tension between identifying patterns in data versus discovering patterns in the world from data. If we address the fundamental challenges associated with "bridging the gap" between domain-driven scientific models and data-driven AI learning machines, then we expect that these AI models can transform hypothesis generation, scientific discovery, and the scientific process itself.
Colored Noise Mechanism for Differentially Private Clustering
Nov 15, 2021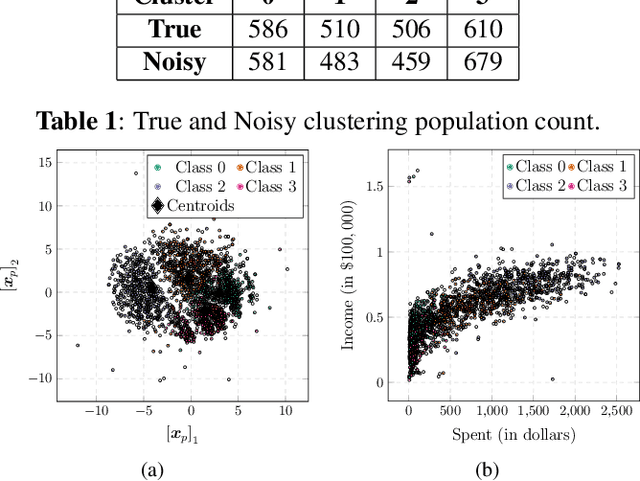
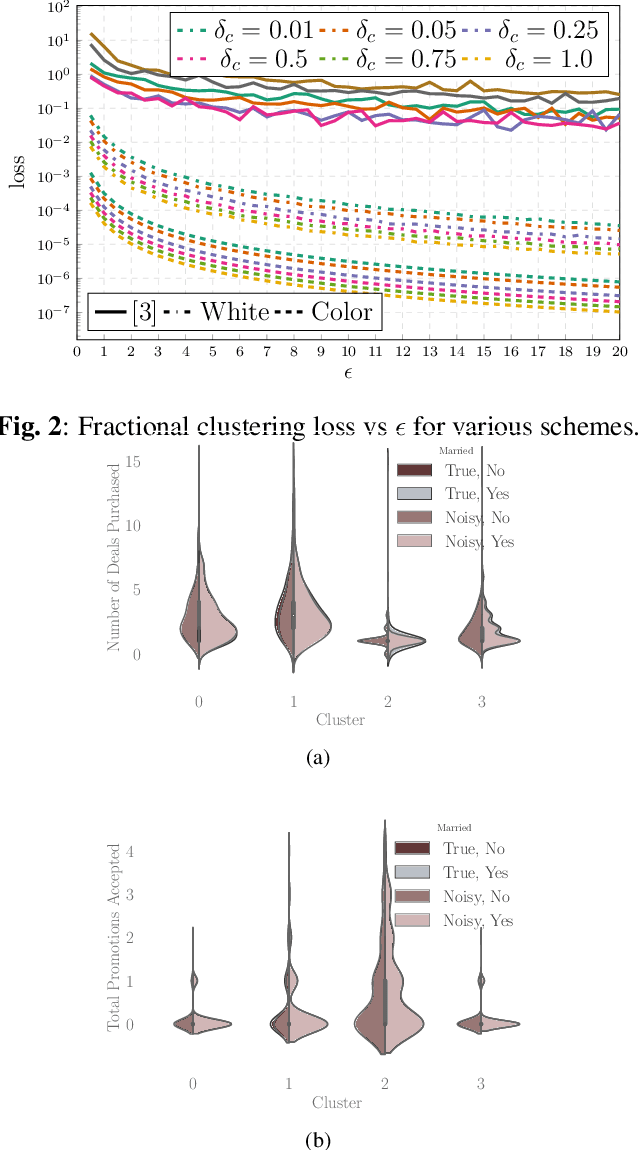
The goal of this paper is to propose and analyze a differentially private randomized mechanism for the $K$-means query. The goal is to ensure that the information received about the cluster-centroids is differentially private. The method consists in adding Gaussian noise with an optimum covariance. The main result of the paper is the analytical solution for the optimum covariance as a function of the database. Comparisons with the state of the art prove the efficacy of our approach.
Catch Me If You Can: Using Power Analysis to Identify HPC Activity
May 06, 2020
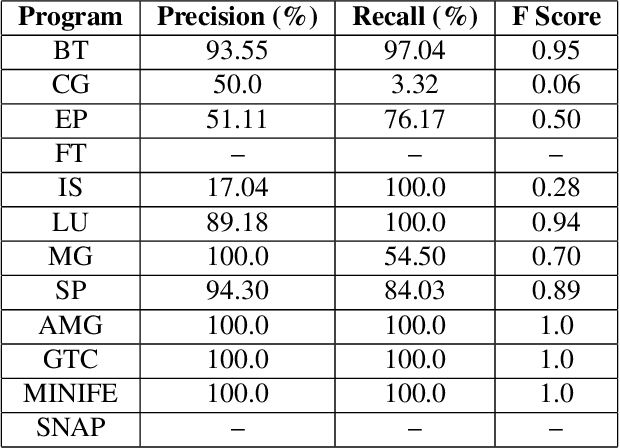
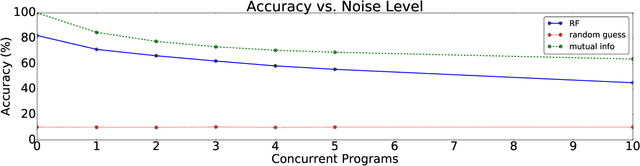

Monitoring users on large computing platforms such as high performance computing (HPC) and cloud computing systems is non-trivial. Utilities such as process viewers provide limited insight into what users are running, due to granularity limitation, and other sources of data, such as system call tracing, can impose significant operational overhead. However, despite technical and procedural measures, instances of users abusing valuable HPC resources for personal gains have been documented in the past \cite{hpcbitmine}, and systems that are open to large numbers of loosely-verified users from around the world are at risk of abuse. In this paper, we show how electrical power consumption data from an HPC platform can be used to identify what programs are executed. The intuition is that during execution, programs exhibit various patterns of CPU and memory activity. These patterns are reflected in the power consumption of the system and can be used to identify programs running. We test our approach on an HPC rack at Lawrence Berkeley National Laboratory using a variety of scientific benchmarks. Among other interesting observations, our results show that by monitoring the power consumption of an HPC rack, it is possible to identify if particular programs are running with precision up to and recall of 95\% even in noisy scenarios.