 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Base Station Optimal Tour in Wide Area IoT Sensor Networks
Mar 09, 2026Wide-area IoT sensor networks require efficient data collection mechanisms when sensors are dispersed over large regions with limited communication infrastructure. Unmanned aerial vehicle (UAV)-mounted Mobile Base Stations (MBSs) provide a flexible solution; however, their limited onboard energy and the strict energy budgets of sensors necessitate carefully optimized tour planning. In this paper, we introduce the Mobile Base Station Optimal Tour (MOT) problem, which seeks a minimum-cost, non-revisiting tour over a subset of candidate stops such that the union of their coverage regions ensures complete sensor data collection under a global sensor energy constraint. The tour also avoids restricted areas. We formally model the MOT problem as a combinatorial optimization problem, which is NP-complete. Owing to its computational intractability, we develop a polynomial-time greedy heuristic that jointly considers travel cost and incremental coverage gain while avoiding restricted areas. Using simulations, we obtain tours with low cost, complete sensor coverage, and faster execution. Our proposed greedy algorithm outperforms state-of-the-art approaches in terms of a performance indicator defined as the product of tour length and algorithm execution time, achieving an improvement of 39.15%. The proposed framework provides both theoretical insight into the structural complexity of MBS-assisted data collection and a practical algorithmic solution for large-scale IoT deployments.
Three-Way Emotion Classification of EEG-based Signals using Machine Learning
Jan 31, 2026Electroencephalography (EEG) is a widely used technique for measuring brain activity. EEG-based signals can reveal a persons emotional state, as they directly reflect activity in different brain regions. Emotion-aware systems and EEG-based emotion recognition are a growing research area. This paper presents how machine learning (ML) models categorize a limited dataset of EEG signals into three different classes, namely Negative, Neutral, or Positive. It also presents the complete workflow, including data preprocessing and comparison of ML models. To understand which ML classification model works best for this kind of problem, we train and test the following three commonly used models: logistic regression (LR), support vector machine (SVM), and random forest (RF). The performance of each is evaluated with respect to accuracy and F1-score. The results indicate that ML models can be effectively utilized for three-way emotion classification of EEG signals. Among the three ML models trained on the available dataset, the RF model gave the best results. Its higher accuracy and F1-score suggest that it is able to capture the emotional patterns more accurately and effectively than the other two models. The RF model also outperformed the existing state-of-the-art classification models in terms of the accuracy parameter.
Semantic Communication-Empowered Traffic Management using Vehicle Count Prediction
Jul 23, 2023Vehicle count prediction is an important aspect of smart city traffic management. Most major roads are monitored by cameras with computing and transmitting capabilities. These cameras provide data to the central traffic controller (CTC), which is in charge of traffic control management. In this paper, we propose a joint CNN-LSTM-based semantic communication (SemCom) model in which the semantic encoder of a camera extracts the relevant semantics from raw images. The encoded semantics are then sent to the CTC by the transmitter in the form of symbols. The semantic decoder of the CTC predicts the vehicle count on each road based on the sequence of received symbols and develops a traffic management strategy accordingly. An optimization problem to improve the quality of experience (QoE) is introduced and numerically solved, taking into account constraints such as vehicle user safety, transmit power of camera devices, vehicle count prediction accuracy, and semantic entropy. Using numerical results, we show that the proposed SemCom model reduces overhead by $54.42\%$ when compared to source encoder/decoder methods. Also, we demonstrate through simulations that the proposed model outperforms state-of-the-art models in terms of mean absolute error (MAE) and QoE.
Node Cardinality Estimation in a Heterogeneous Wireless Network Deployed Over a Large Region Using a Mobile Base Station
Jun 15, 2023



We consider the problem of estimation of the node cardinality of each node type in a heterogeneous wireless network with $T$ types of nodes deployed over a large region, where $T \ge 2$ is an integer. A mobile base station (MBS), such as that mounted on an unmanned aerial vehicle, is used in such cases since a single static base station is not sufficient to cover such a large region. The MBS moves around in the region and makes multiple stops, and at the last stop, it is able to estimate the node cardinalities for the entire region. In this paper, we propose two schemes, viz., HSRC-M1 and HSRC-M2, to rapidly estimate the number of nodes of each type. Both schemes have two phases, and they are performed at each stop. We prove that the node cardinality estimates computed using our proposed schemes are equal to, and hence as accurate as, the estimates that would have been obtained if a well-known estimation protocol designed for homogeneous networks in prior work were separately executed $T$ times. We compute closed-form expressions for the expected number of slots required by HSRC-M1 to execute and the expected energy consumption of a node under HSRC-M1. We formulate the problem of finding the optimal tour of the MBS around the region, which covers all the nodes and minimizes the travel cost of the MBS, show that it is NP-complete, and provide a greedy algorithm to solve it. Using simulations, we show that the numbers of slots required by the proposed schemes, HSRC-M1 and HSRC-M2, for computing node cardinality estimates are significantly less than the number of slots required for $T$ separate executions of the above estimation protocol for homogeneous networks.
Knowledge-Aware Semantic Communication System Design
Jan 28, 2023The recent emergence of 6G raises the challenge of increasing the transmission data rate even further in order to break the barrier set by the Shannon limit. Traditional communication methods fall short of the 6G goals, paving the way for Semantic Communication (SemCom) systems. These systems find applications in wide range of fields such as economics, metaverse, autonomous transportation systems, healthcare, smart factories, etc. In SemCom systems, only the relevant information from the data, known as semantic data, is extracted to eliminate unwanted overheads in the raw data and then transmitted after encoding. In this paper, we first use the shared knowledge base to extract the keywords from the dataset. Then, we design an auto-encoder and auto-decoder that only transmit these keywords and, respectively, recover the data using the received keywords and the shared knowledge. We show analytically that the overall semantic distortion function has an upper bound, which is shown in the literature to converge. We numerically compute the accuracy of the reconstructed sentences at the receiver. Using simulations, we show that the proposed methods outperform a state-of-the-art method in terms of the average number of words per sentence.
Knowledge-Aware Semantic Communication System Design and Data Allocation
Dec 30, 2022The recent emergence of 6G raises the challenge of increasing the transmission data rate even further in order to overcome the Shannon limit. Traditional communication methods fall short of the 6G goals, paving the way for Semantic Communication (SemCom) systems that have applications in the metaverse, healthcare, economics, etc. In SemCom systems, only the relevant keywords from the data are extracted and used for transmission. In this paper, we design an auto-encoder and auto-decoder that only transmit these keywords and, respectively, recover the data using the received keywords and the shared knowledge. This SemCom system is used in a setup in which the receiver allocates various categories of the same dataset collected from the transmitter, which differ in size and accuracy, to a number of users. This scenario is formulated using an optimization problem called the data allocation problem (DAP). We show that it is NP-complete and propose a greedy algorithm to solve it. Using simulations, we show that the proposed methods for SemCom system design outperform state-of-the-art methods in terms of average number of words per sentence for a given accuracy, and that the proposed greedy algorithm solution of the DAP performs significantly close to the optimal solution.
Differentially Private $K$-means Clustering Applied to Meter Data Analysis and Synthesis
Dec 07, 2021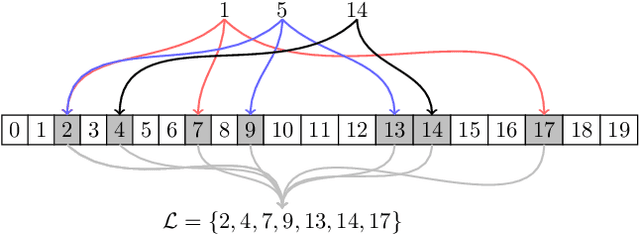
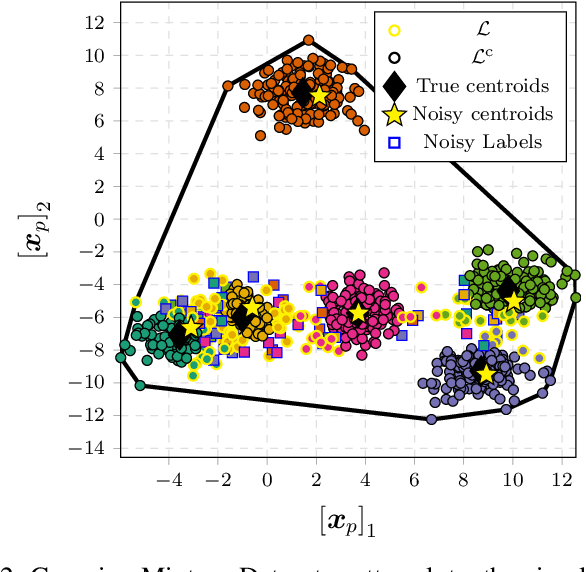
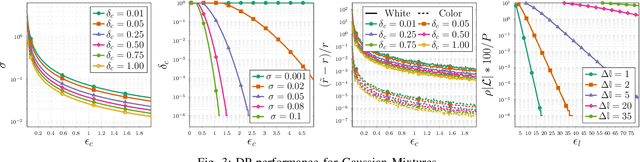
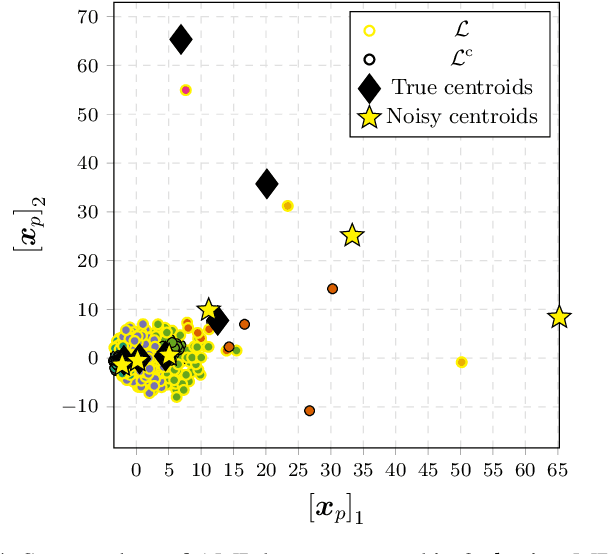
The proliferation of smart meters has resulted in a large amount of data being generated. It is increasingly apparent that methods are required for allowing a variety of stakeholders to leverage the data in a manner that preserves the privacy of the consumers. The sector is scrambling to define policies, such as the so called '15/15 rule', to respond to the need. However, the current policies fail to adequately guarantee privacy. In this paper, we address the problem of allowing third parties to apply $K$-means clustering, obtaining customer labels and centroids for a set of load time series by applying the framework of differential privacy. We leverage the method to design an algorithm that generates differentially private synthetic load data consistent with the labeled data. We test our algorithm's utility by answering summary statistics such as average daily load profiles for a 2-dimensional synthetic dataset and a real-world power load dataset.