 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Transfer Learning via Shared Latent Geometry: Theory and Applications
May 30, 2026Inference and control in engineered physical systems pay a heavy physics cost at deployment: state estimators, inverse-problem solvers, model-predictive controllers, schedulers, and observers are often not closed-form and must re-solve a numerical optimization per instance, with the operator re-supplied each time. Physics-informed learning moves this cost to training, but uses a single encoder pathway whose latent geometry de-learns under fine-tuning and admits no quantitative transfer guarantee. We propose an asymmetric two-pathway architecture that resolves both issues. A teacher encoder consumes privileged dense states from a high-fidelity simulator and represents the system through operator-polynomial features stable under spectral perturbation; a student encoder learns the same latent geometry from sparse field data and operator descriptors. At deployment the teacher is discarded, and the frozen student runs in a single forward pass with a transfer certificate. The design connects to privileged-information learning, knowledge distillation, and cross-modal distillation, but targets cross-instance transfer rather than fixed-instance prediction: topology and operator may change, while the latent task does not. We establish sufficient and near-necessary transfer conditions via Wasserstein proximity between latent laws, yielding a zero-shot error bound, and develop a finite-sample certification protocol with active expansion when coverage is incomplete. The framework applies wherever a system admits an operator with reportable spectrum. On power-system estimation, it achieves zero-shot transfer to 100 unseen topologies, a 95% certificate pass rate, accuracy competitive with topology-aware Newton--Raphson, and sub-millisecond inference. These results suggest asymmetric pathways plus operator-anchored latent geometry provide a foundation for certified zero-shot inference and control.
Universal Graph Learning for Power System Reconfigurations: Transfer Across Topology Variations
Sep 10, 2025This work addresses a fundamental challenge in applying deep learning to power systems: developing neural network models that transfer across significant system changes, including networks with entirely different topologies and dimensionalities, without requiring training data from unseen reconfigurations. Despite extensive research, most ML-based approaches remain system-specific, limiting real-world deployment. This limitation stems from a dual barrier. First, topology changes shift feature distributions and alter input dimensions due to power flow physics. Second, reconfigurations redefine output semantics and dimensionality, requiring models to handle configuration-specific outputs while maintaining transferable feature extraction. To overcome this challenge, we introduce a Universal Graph Convolutional Network (UGCN) that achieves transferability to any reconfiguration or variation of existing power systems without any prior knowledge of new grid topologies or retraining during implementation. Our approach applies to both transmission and distribution networks and demonstrates generalization capability to completely unseen system reconfigurations, such as network restructuring and major grid expansions. Experimental results across power system applications, including false data injection detection and state forecasting, show that UGCN significantly outperforms state-of-the-art methods in cross-system zero-shot transferability of new reconfigurations.
Decentralized Differentially Private Power Method
Jul 30, 2025We propose a novel Decentralized Differentially Private Power Method (D-DP-PM) for performing Principal Component Analysis (PCA) in networked multi-agent settings. Unlike conventional decentralized PCA approaches where each agent accesses the full n-dimensional sample space, we address the challenging scenario where each agent observes only a subset of dimensions through row-wise data partitioning. Our method ensures $(\epsilon,\delta)$-Differential Privacy (DP) while enabling collaborative estimation of global eigenvectors across the network without requiring a central aggregator. We achieve this by having agents share only local embeddings of the current eigenvector iterate, leveraging both the inherent privacy from random initialization and carefully calibrated Gaussian noise additions. We prove that our algorithm satisfies the prescribed $(\epsilon,\delta)$-DP guarantee and establish convergence rates that explicitly characterize the impact of the network topology. Our theoretical analysis, based on linear dynamics and high-dimensional probability theory, provides tight bounds on both privacy and utility. Experiments on real-world datasets demonstrate that D-DP-PM achieves superior privacy-utility tradeoffs compared to naive local DP approaches, with particularly strong performance in moderate privacy regimes ($\epsilon\in[2, 5]$). The method converges rapidly, allowing practitioners to trade iterations for enhanced privacy while maintaining competitive utility.
Preserving Smart Grid Integrity: A Differential Privacy Framework for Secure Detection of False Data Injection Attacks in the Smart Grid
Mar 04, 2024In this paper, we present a framework based on differential privacy (DP) for querying electric power measurements to detect system anomalies or bad data caused by false data injections (FDIs). Our DP approach conceals consumption and system matrix data, while simultaneously enabling an untrusted third party to test hypotheses of anomalies, such as an FDI attack, by releasing a randomized sufficient statistic for hypothesis-testing. We consider a measurement model corrupted by Gaussian noise and a sparse noise vector representing the attack, and we observe that the optimal test statistic is a chi-square random variable. To detect possible attacks, we propose a novel DP chi-square noise mechanism that ensures the test does not reveal private information about power injections or the system matrix. The proposed framework provides a robust solution for detecting FDIs while preserving the privacy of sensitive power system data.
MALCOM-PSGD: Inexact Proximal Stochastic Gradient Descent for Communication-Efficient Decentralized Machine Learning
Nov 09, 2023Recent research indicates that frequent model communication stands as a major bottleneck to the efficiency of decentralized machine learning (ML), particularly for large-scale and over-parameterized neural networks (NNs). In this paper, we introduce MALCOM-PSGD, a new decentralized ML algorithm that strategically integrates gradient compression techniques with model sparsification. MALCOM-PSGD leverages proximal stochastic gradient descent to handle the non-smoothness resulting from the $\ell_1$ regularization in model sparsification. Furthermore, we adapt vector source coding and dithering-based quantization for compressed gradient communication of sparsified models. Our analysis shows that decentralized proximal stochastic gradient descent with compressed communication has a convergence rate of $\mathcal{O}\left(\ln(t)/\sqrt{t}\right)$ assuming a diminishing learning rate and where $t$ denotes the number of iterations. Numerical results verify our theoretical findings and demonstrate that our method reduces communication costs by approximately $75\%$ when compared to the state-of-the-art method.
Blind Graph Matching Using Graph Signals
Jun 27, 2023Classical graph matching aims to find a node correspondence between two unlabeled graphs of known topologies. This problem has a wide range of applications, from matching identities in social networks to identifying similar biological network functions across species. However, when the underlying graphs are unknown, the use of conventional graph matching methods requires inferring the graph topologies first, a process that is highly sensitive to observation errors. In this paper, we tackle the blind graph matching problem with unknown underlying graphs directly using observations of graph signals, which are generated from graph filters applied to graph signal excitations. We propose to construct sample covariance matrices from the observed signals and match the nodes based on the selected sample eigenvectors. Our analysis shows that the blind matching outcome converges to the result obtained with known graph topologies when the signal sampling size is large and the signal noise is small. Numerical results showcase the performance improvement of the proposed algorithm compared to matching two estimated underlying graphs learned from the graph signals.
Differential Privacy for Class-based Data: A Practical Gaussian Mechanism
Jun 08, 2023



In this paper, we present a notion of differential privacy (DP) for data that comes from different classes. Here, the class-membership is private information that needs to be protected. The proposed method is an output perturbation mechanism that adds noise to the release of query response such that the analyst is unable to infer the underlying class-label. The proposed DP method is capable of not only protecting the privacy of class-based data but also meets quality metrics of accuracy and is computationally efficient and practical. We illustrate the efficacy of the proposed method empirically while outperforming the baseline additive Gaussian noise mechanism. We also examine a real-world application and apply the proposed DP method to the autoregression and moving average (ARMA) forecasting method, protecting the privacy of the underlying data source. Case studies on the real-world advanced metering infrastructure (AMI) measurements of household power consumption validate the excellent performance of the proposed DP method while also satisfying the accuracy of forecasted power consumption measurements.
Solar Photovoltaic Systems Metadata Inference and Differentially Private Publication
Apr 07, 2023Stakeholders in electricity delivery infrastructure are amassing data about their system demand, use, and operations. Still, they are reluctant to share them, as even sharing aggregated or anonymized electric grid data risks the disclosure of sensitive information. This paper highlights how applying differential privacy to distributed energy resource production data can preserve the usefulness of that data for operations, planning, and research purposes without violating privacy constraints. Differentially private mechanisms can be optimized for queries of interest in the energy sector, with provable privacy and accuracy trade-offs, and can help design differentially private databases for further analysis and research. In this paper, we consider the problem of inference and publication of solar photovoltaic systems' metadata. Metadata such as nameplate capacity, surface azimuth and surface tilt may reveal personally identifiable information regarding the installation behind-the-meter. We describe a methodology to infer the metadata and propose a mechanism based on Bayesian optimization to publish the inferred metadata in a differentially private manner. The proposed mechanism is numerically validated using real-world solar power generation data.
Complex-Value Spatio-temporal Graph Convolutional Neural Networks and its Applications to Electric Power Systems AI
Aug 17, 2022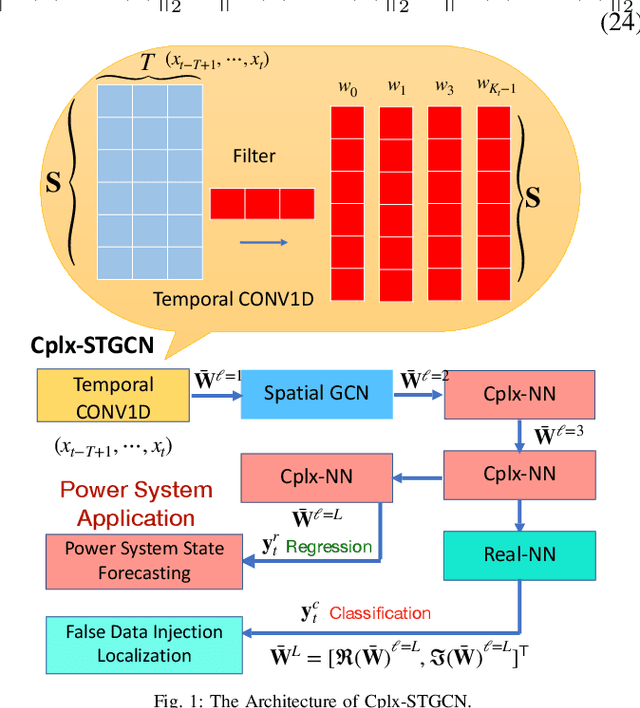
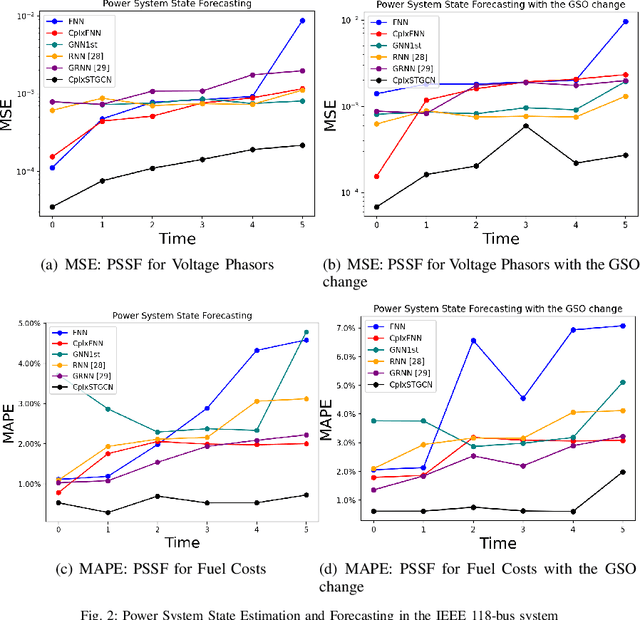
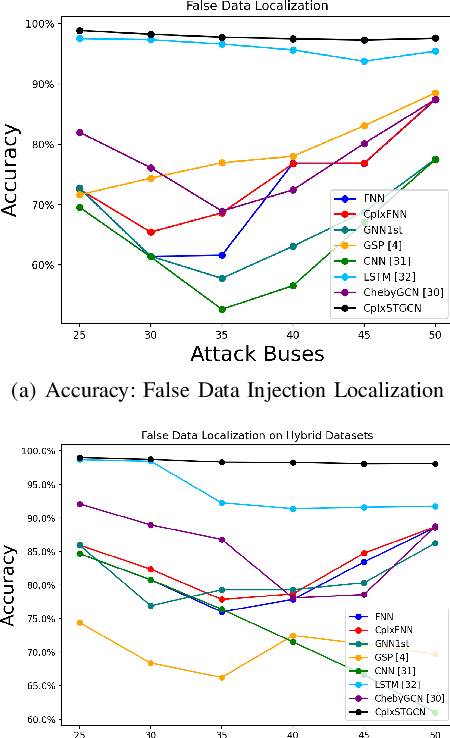
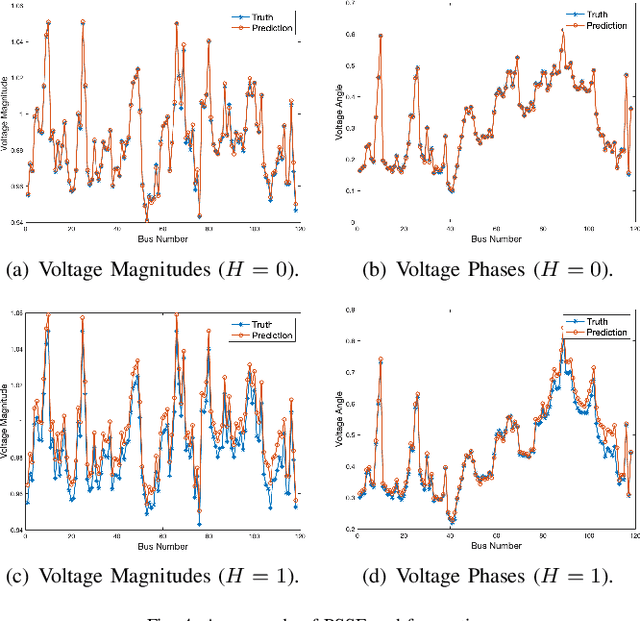
The effective representation, precessing, analysis, and visualization of large-scale structured data over graphs are gaining a lot of attention. So far most of the literature has focused on real-valued signals. However, signals are often sparse in the Fourier domain, and more informative and compact representations for them can be obtained using the complex envelope of their spectral components, as opposed to the original real-valued signals. Motivated by this fact, in this work we generalize graph convolutional neural networks (GCN) to the complex domain, deriving the theory that allows to incorporate a complex-valued graph shift operators (GSO) in the definition of graph filters (GF) and process complex-valued graph signals (GS). The theory developed can handle spatio-temporal complex network processes. We prove that complex-valued GCNs are stable with respect to perturbations of the underlying graph support, the bound of the transfer error and the bound of error propagation through multiply layers. Then we apply complex GCN to power grid state forecasting, power grid cyber-attack detection and localization.
Differentially Private $K$-means Clustering Applied to Meter Data Analysis and Synthesis
Dec 07, 2021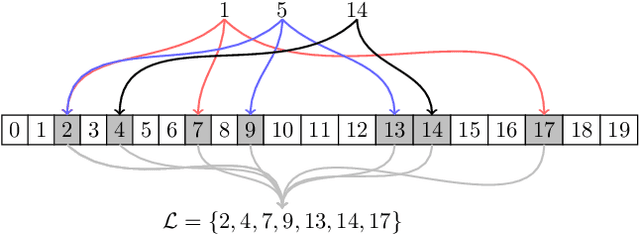
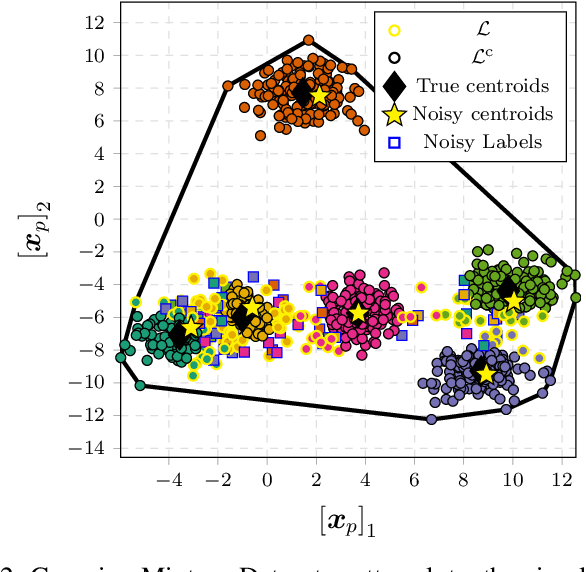
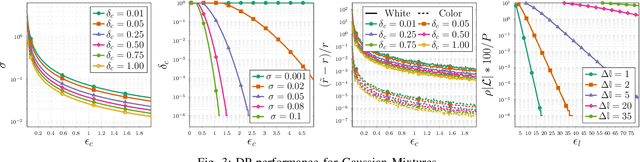
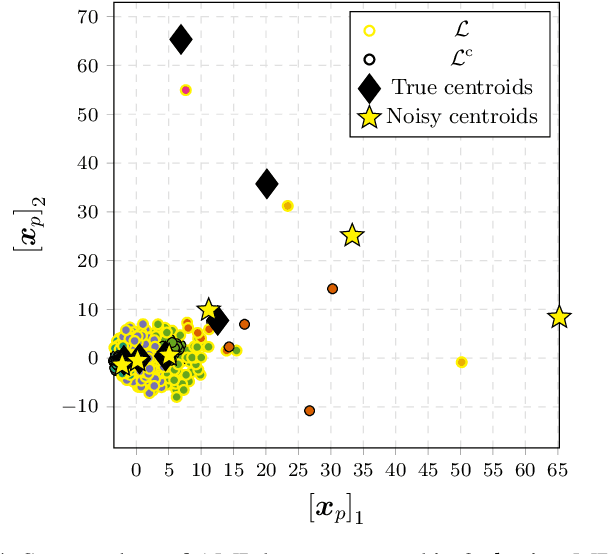
The proliferation of smart meters has resulted in a large amount of data being generated. It is increasingly apparent that methods are required for allowing a variety of stakeholders to leverage the data in a manner that preserves the privacy of the consumers. The sector is scrambling to define policies, such as the so called '15/15 rule', to respond to the need. However, the current policies fail to adequately guarantee privacy. In this paper, we address the problem of allowing third parties to apply $K$-means clustering, obtaining customer labels and centroids for a set of load time series by applying the framework of differential privacy. We leverage the method to design an algorithm that generates differentially private synthetic load data consistent with the labeled data. We test our algorithm's utility by answering summary statistics such as average daily load profiles for a 2-dimensional synthetic dataset and a real-world power load dataset.