 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multi-Source Data Fusion Through Latent Variable Gaussian Process
Feb 16, 2024With the advent of artificial intelligence (AI) and machine learning (ML), various domains of science and engineering communites has leveraged data-driven surrogates to model complex systems from numerous sources of information (data). The proliferation has led to significant reduction in cost and time involved in development of superior systems designed to perform specific functionalities. A high proposition of such surrogates are built extensively fusing multiple sources of data, may it be published papers, patents, open repositories, or other resources. However, not much attention has been paid to the differences in quality and comprehensiveness of the known and unknown underlying physical parameters of the information sources that could have downstream implications during system optimization. Towards resolving this issue, a multi-source data fusion framework based on Latent Variable Gaussian Process (LVGP) is proposed. The individual data sources are tagged as a characteristic categorical variable that are mapped into a physically interpretable latent space, allowing the development of source-aware data fusion modeling. Additionally, a dissimilarity metric based on the latent variables of LVGP is introduced to study and understand the differences in the sources of data. The proposed approach is demonstrated on and analyzed through two mathematical (representative parabola problem, 2D Ackley function) and two materials science (design of FeCrAl and SmCoFe alloys) case studies. From the case studies, it is observed that compared to using single-source and source unaware ML models, the proposed multi-source data fusion framework can provide better predictions for sparse-data problems, interpretability regarding the sources, and enhanced modeling capabilities by taking advantage of the correlations and relationships among different sources.
Bioplastic Design using Multitask Deep Neural Networks
Mar 22, 2022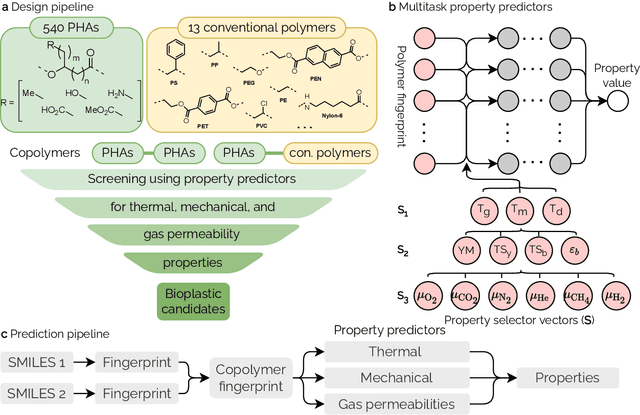
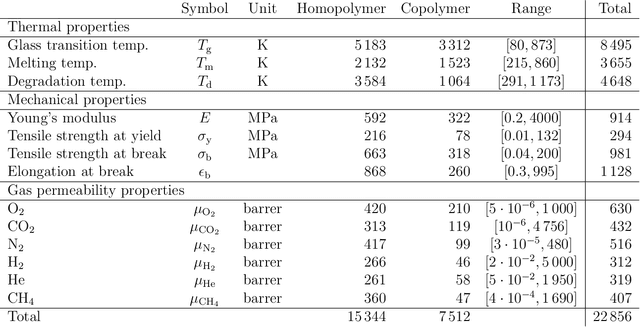
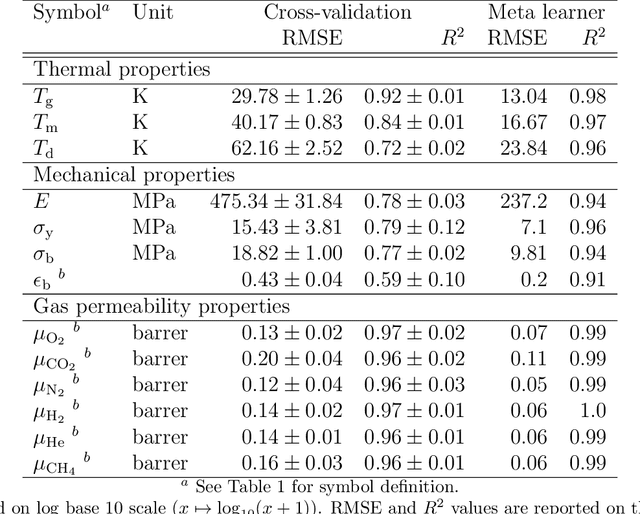
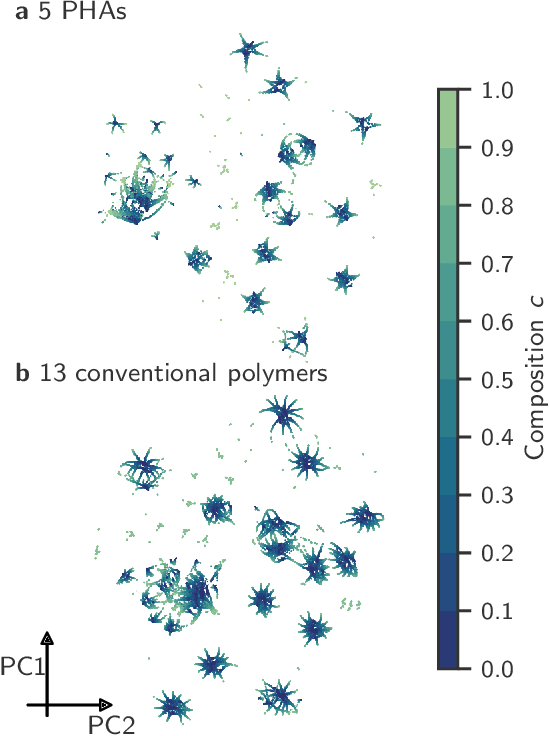
Non-degradable plastic waste stays for decades on land and in water, jeopardizing our environment; yet our modern lifestyle and current technologies are impossible to sustain without plastics. Bio-synthesized and biodegradable alternatives such as the polymer family of polyhydroxyalkanoates (PHAs) have the potential to replace large portions of the world's plastic supply with cradle-to-cradle materials, but their chemical complexity and diversity limit traditional resource-intensive experimentation. In this work, we develop multitask deep neural network property predictors using available experimental data for a diverse set of nearly 23000 homo- and copolymer chemistries. Using the predictors, we identify 14 PHA-based bioplastics from a search space of almost 1.4 million candidates which could serve as potential replacements for seven petroleum-based commodity plastics that account for 75% of the world's yearly plastic production. We discuss possible synthesis routes for these identified promising materials. The developed multitask polymer property predictors are made available as a part of the Polymer Genome project at https://PolymerGenome.org.
Learning from learning machines: a new generation of AI technology to meet the needs of science
Nov 27, 2021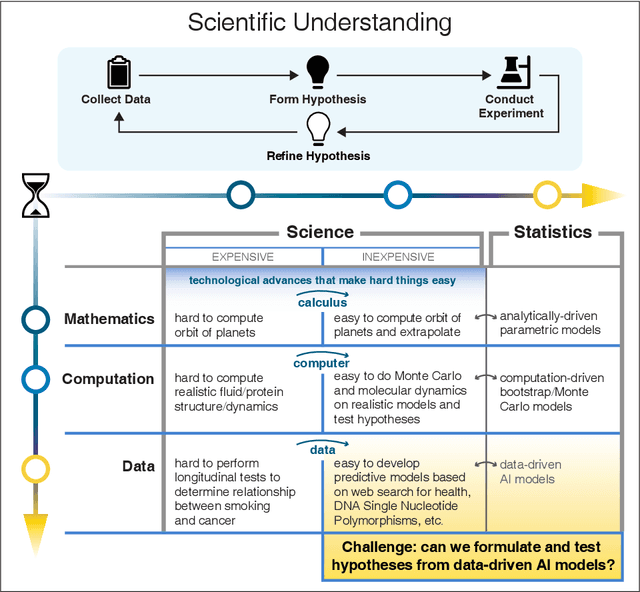

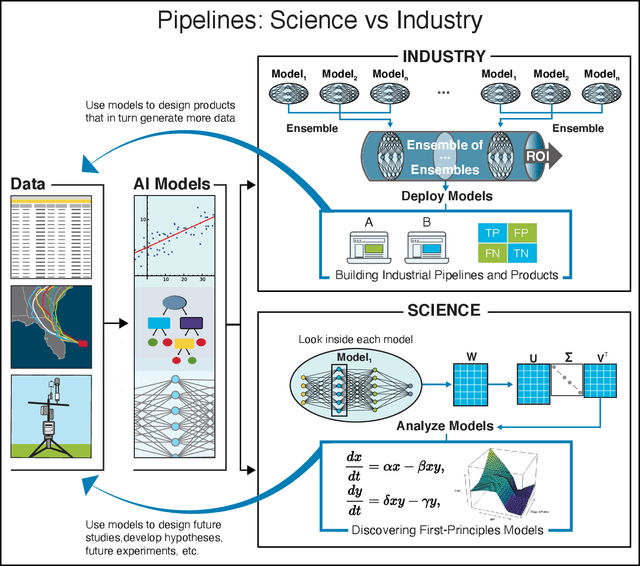
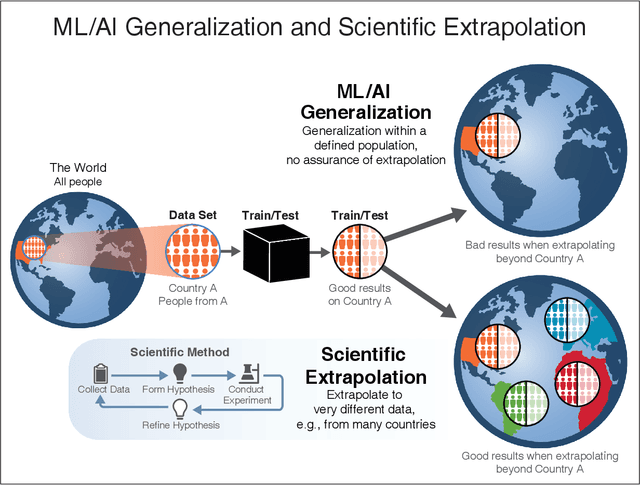
We outline emerging opportunities and challenges to enhance the utility of AI for scientific discovery. The distinct goals of AI for industry versus the goals of AI for science create tension between identifying patterns in data versus discovering patterns in the world from data. If we address the fundamental challenges associated with "bridging the gap" between domain-driven scientific models and data-driven AI learning machines, then we expect that these AI models can transform hypothesis generation, scientific discovery, and the scientific process itself.
Polymer Informatics: Current Status and Critical Next Steps
Nov 01, 2020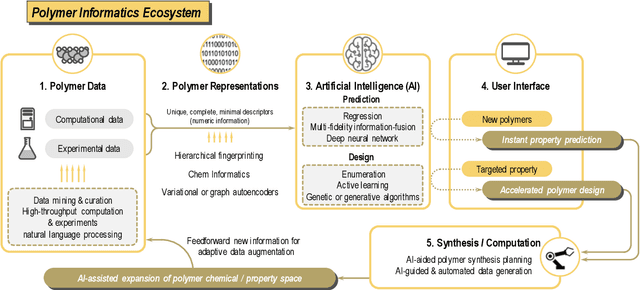

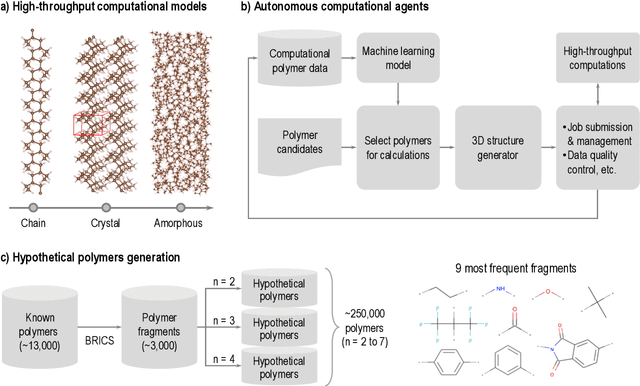

Artificial intelligence (AI) based approaches are beginning to impact several domains of human life, science and technology. Polymer informatics is one such domain where AI and machine learning (ML) tools are being used in the efficient development, design and discovery of polymers. Surrogate models are trained on available polymer data for instant property prediction, allowing screening of promising polymer candidates with specific target property requirements. Questions regarding synthesizability, and potential (retro)synthesis steps to create a target polymer, are being explored using statistical means. Data-driven strategies to tackle unique challenges resulting from the extraordinary chemical and physical diversity of polymers at small and large scales are being explored. Other major hurdles for polymer informatics are the lack of widespread availability of curated and organized data, and approaches to create machine-readable representations that capture not just the structure of complex polymeric situations but also synthesis and processing conditions. Methods to solve inverse problems, wherein polymer recommendations are made using advanced AI algorithms that meet application targets, are being investigated. As various parts of the burgeoning polymer informatics ecosystem mature and become integrated, efficiency improvements, accelerated discoveries and increased productivity can result. Here, we review emergent components of this polymer informatics ecosystem and discuss imminent challenges and opportunities.