 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolymer Informatics: Current Status and Critical Next Steps
Paper and Code
Nov 01, 2020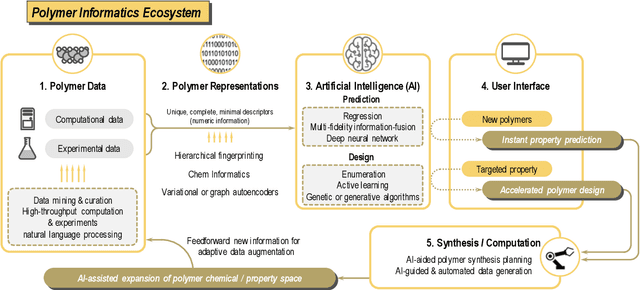

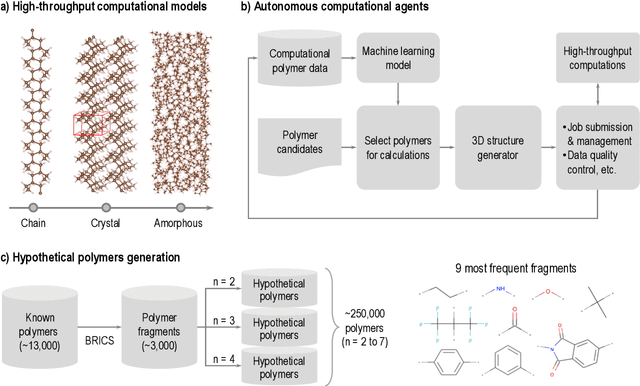

Artificial intelligence (AI) based approaches are beginning to impact several domains of human life, science and technology. Polymer informatics is one such domain where AI and machine learning (ML) tools are being used in the efficient development, design and discovery of polymers. Surrogate models are trained on available polymer data for instant property prediction, allowing screening of promising polymer candidates with specific target property requirements. Questions regarding synthesizability, and potential (retro)synthesis steps to create a target polymer, are being explored using statistical means. Data-driven strategies to tackle unique challenges resulting from the extraordinary chemical and physical diversity of polymers at small and large scales are being explored. Other major hurdles for polymer informatics are the lack of widespread availability of curated and organized data, and approaches to create machine-readable representations that capture not just the structure of complex polymeric situations but also synthesis and processing conditions. Methods to solve inverse problems, wherein polymer recommendations are made using advanced AI algorithms that meet application targets, are being investigated. As various parts of the burgeoning polymer informatics ecosystem mature and become integrated, efficiency improvements, accelerated discoveries and increased productivity can result. Here, we review emergent components of this polymer informatics ecosystem and discuss imminent challenges and opportunities.