 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Discovery of High Performance Polymer Electrodes for Next-Generation Batteries
Feb 19, 2025The use of transition group metals in electric batteries requires extensive usage of critical elements like lithium, cobalt and nickel, which poses significant environmental challenges. Replacing these metals with redox-active organic materials offers a promising alternative, thereby reducing the carbon footprint of batteries by one order of magnitude. However, this approach faces critical obstacles, including the limited availability of suitable redox-active organic materials and issues such as lower electronic conductivity, voltage, specific capacity, and long-term stability. To overcome the limitations for lower voltage and specific capacity, a machine learning (ML) driven battery informatics framework is developed and implemented. This framework utilizes an extensive battery dataset and advanced ML techniques to accelerate and enhance the identification, optimization, and design of redox-active organic materials. In this contribution, a data-fusion ML coupled meta learning model capable of predicting the battery properties, voltage and specific capacity, for various organic negative electrodes and charge carriers (positive electrode materials) combinations is presented. The ML models accelerate experimentation, facilitate the inverse design of battery materials, and identify suitable candidates from three extensive material libraries to advance sustainable energy-storage technologies.
polyBERT: A chemical language model to enable fully machine-driven ultrafast polymer informatics
Sep 29, 2022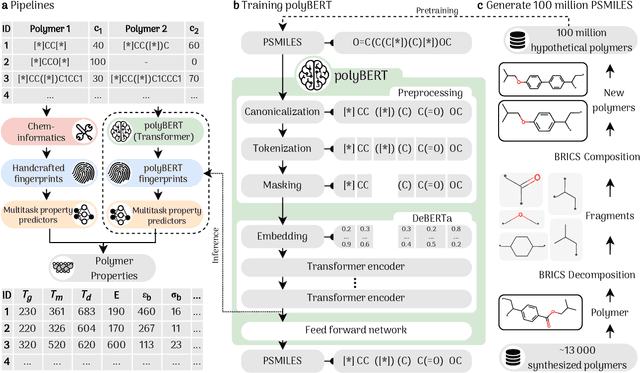
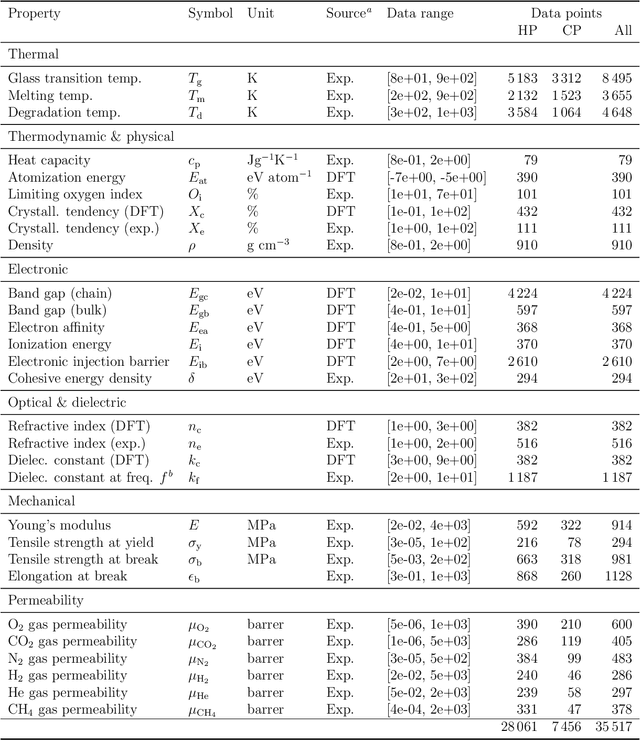
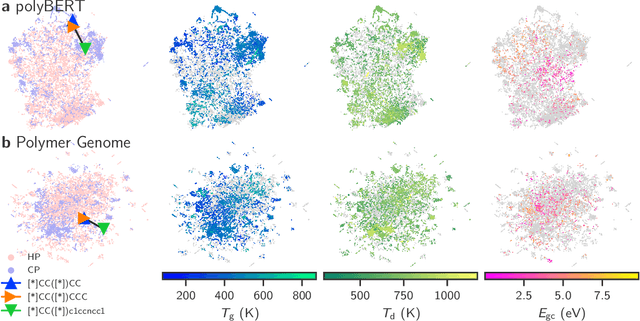
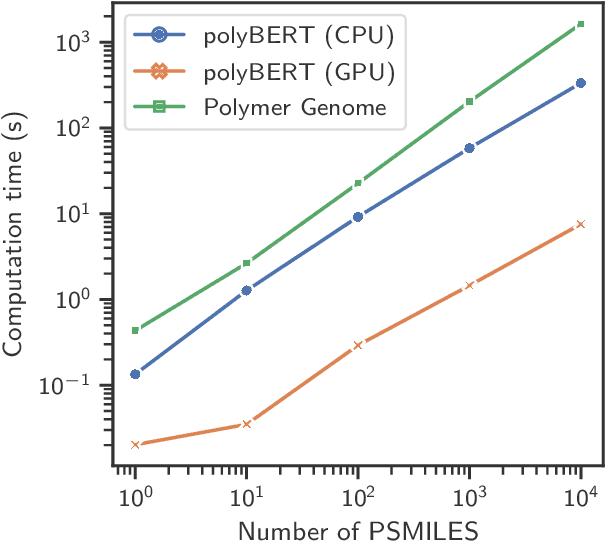
Polymers are a vital part of everyday life. Their chemical universe is so large that it presents unprecedented opportunities as well as significant challenges to identify suitable application-specific candidates. We present a complete end-to-end machine-driven polymer informatics pipeline that can search this space for suitable candidates at unprecedented speed and accuracy. This pipeline includes a polymer chemical fingerprinting capability called polyBERT (inspired by Natural Language Processing concepts), and a multitask learning approach that maps the polyBERT fingerprints to a host of properties. polyBERT is a chemical linguist that treats the chemical structure of polymers as a chemical language. The present approach outstrips the best presently available concepts for polymer property prediction based on handcrafted fingerprint schemes in speed by two orders of magnitude while preserving accuracy, thus making it a strong candidate for deployment in scalable architectures including cloud infrastructures.
A general-purpose material property data extraction pipeline from large polymer corpora using Natural Language Processing
Sep 27, 2022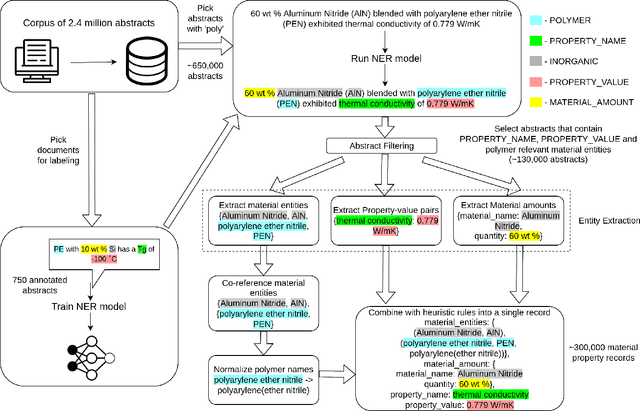
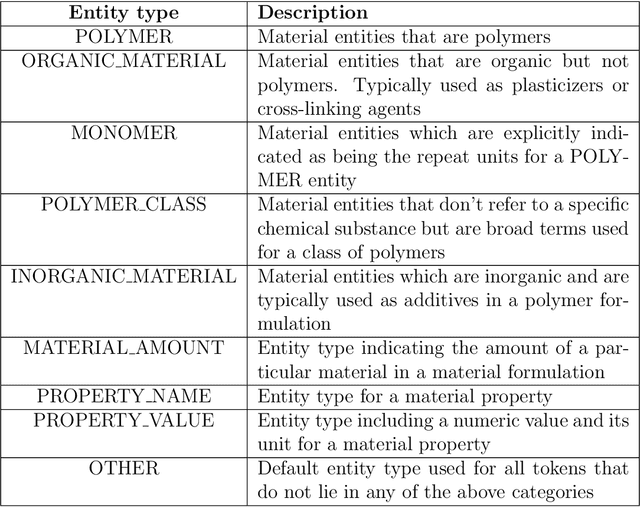
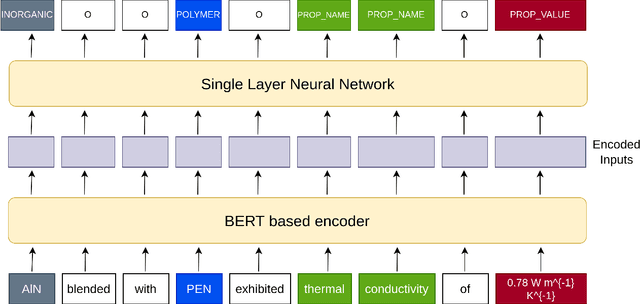
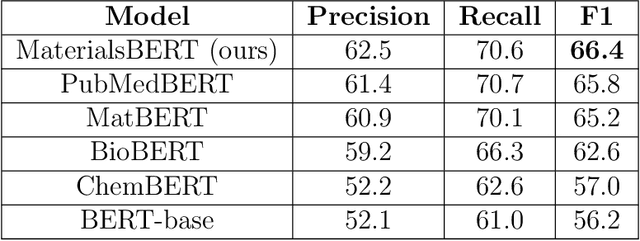
The ever-increasing number of materials science articles makes it hard to infer chemistry-structure-property relations from published literature. We used natural language processing (NLP) methods to automatically extract material property data from the abstracts of polymer literature. As a component of our pipeline, we trained MaterialsBERT, a language model, using 2.4 million materials science abstracts, which outperforms other baseline models in three out of five named entity recognition datasets when used as the encoder for text. Using this pipeline, we obtained ~300,000 material property records from ~130,000 abstracts in 60 hours. The extracted data was analyzed for a diverse range of applications such as fuel cells, supercapacitors, and polymer solar cells to recover non-trivial insights. The data extracted through our pipeline is made available through a web platform at https://polymerscholar.org which can be used to locate material property data recorded in abstracts conveniently. This work demonstrates the feasibility of an automatic pipeline that starts from published literature and ends with a complete set of extracted material property information.
Bioplastic Design using Multitask Deep Neural Networks
Mar 22, 2022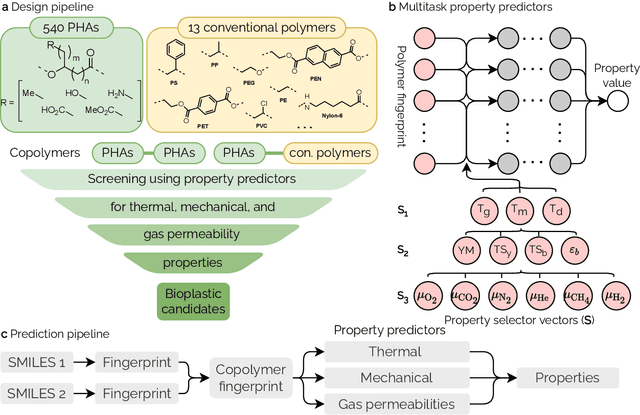
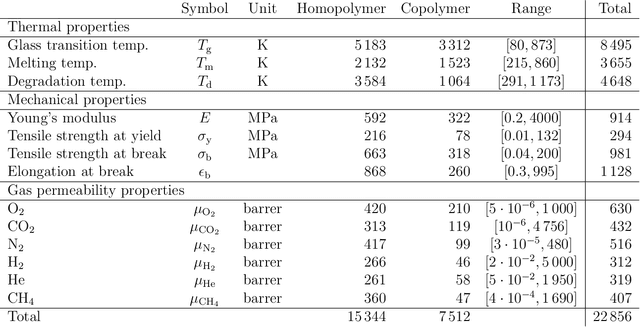
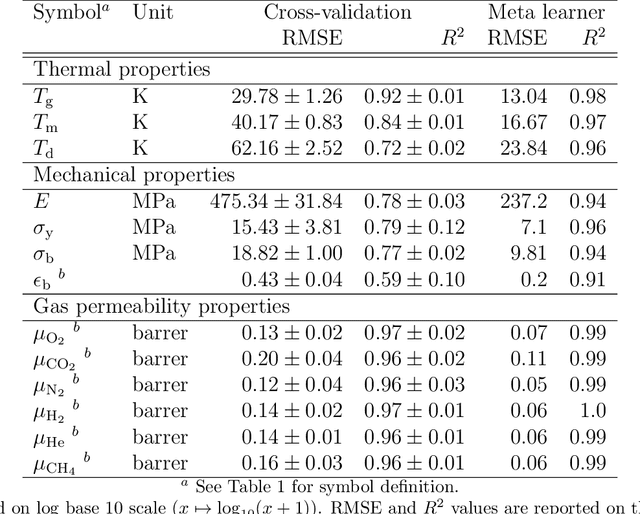
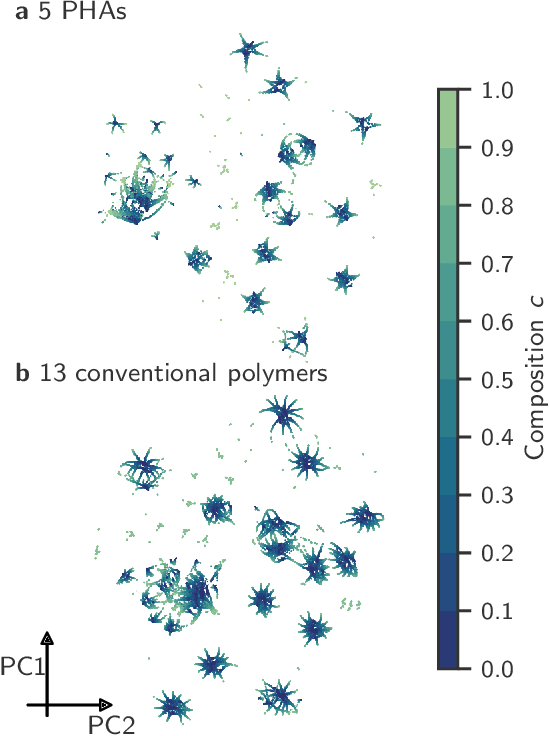
Non-degradable plastic waste stays for decades on land and in water, jeopardizing our environment; yet our modern lifestyle and current technologies are impossible to sustain without plastics. Bio-synthesized and biodegradable alternatives such as the polymer family of polyhydroxyalkanoates (PHAs) have the potential to replace large portions of the world's plastic supply with cradle-to-cradle materials, but their chemical complexity and diversity limit traditional resource-intensive experimentation. In this work, we develop multitask deep neural network property predictors using available experimental data for a diverse set of nearly 23000 homo- and copolymer chemistries. Using the predictors, we identify 14 PHA-based bioplastics from a search space of almost 1.4 million candidates which could serve as potential replacements for seven petroleum-based commodity plastics that account for 75% of the world's yearly plastic production. We discuss possible synthesis routes for these identified promising materials. The developed multitask polymer property predictors are made available as a part of the Polymer Genome project at https://PolymerGenome.org.
Copolymer Informatics with Multi-Task Deep Neural Networks
Mar 25, 2021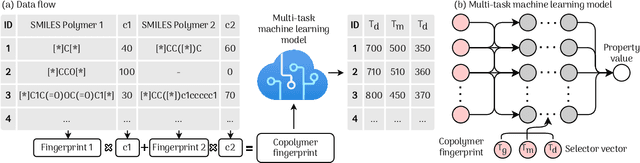

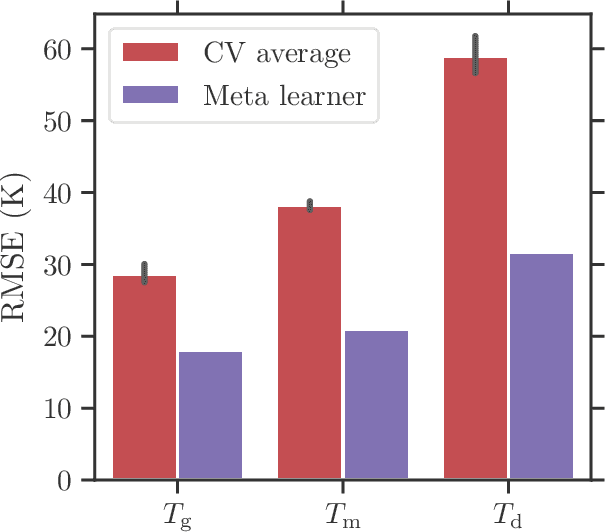
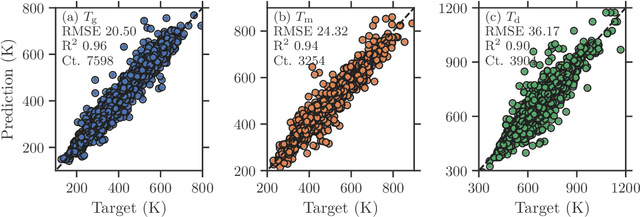
Polymer informatics tools have been recently gaining ground to efficiently and effectively develop, design, and discover new polymers that meet specific application needs. So far, however, these data-driven efforts have largely focused on homopolymers. Here, we address the property prediction challenge for copolymers, extending the polymer informatics framework beyond homopolymers. Advanced polymer fingerprinting and deep-learning schemes that incorporate multi-task learning and meta-learning are proposed. A large data set containing over 18,000 data points of glass transition, melting, and degradation temperature of homopolymers and copolymers of up to two monomers is used to demonstrate the copolymer prediction efficacy. The developed models are accurate, fast, flexible, and scalable to more copolymer properties when suitable data become available.
Polymer Informatics: Current Status and Critical Next Steps
Nov 01, 2020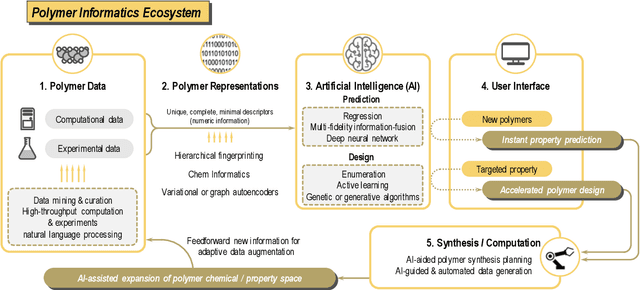

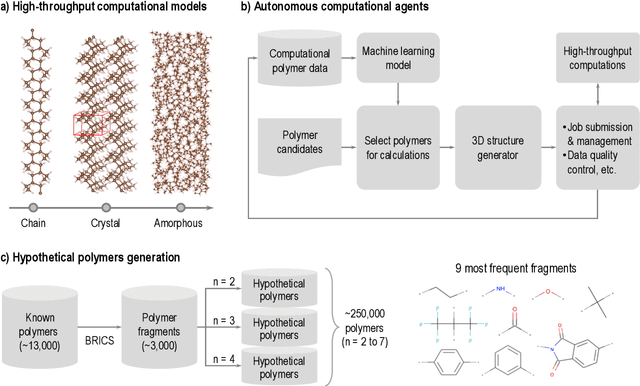

Artificial intelligence (AI) based approaches are beginning to impact several domains of human life, science and technology. Polymer informatics is one such domain where AI and machine learning (ML) tools are being used in the efficient development, design and discovery of polymers. Surrogate models are trained on available polymer data for instant property prediction, allowing screening of promising polymer candidates with specific target property requirements. Questions regarding synthesizability, and potential (retro)synthesis steps to create a target polymer, are being explored using statistical means. Data-driven strategies to tackle unique challenges resulting from the extraordinary chemical and physical diversity of polymers at small and large scales are being explored. Other major hurdles for polymer informatics are the lack of widespread availability of curated and organized data, and approaches to create machine-readable representations that capture not just the structure of complex polymeric situations but also synthesis and processing conditions. Methods to solve inverse problems, wherein polymer recommendations are made using advanced AI algorithms that meet application targets, are being investigated. As various parts of the burgeoning polymer informatics ecosystem mature and become integrated, efficiency improvements, accelerated discoveries and increased productivity can result. Here, we review emergent components of this polymer informatics ecosystem and discuss imminent challenges and opportunities.