 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Non-Membership in LLM Training Data via Rank Correlations
Mar 24, 2026As large language models (LLMs) are trained on increasingly vast and opaque text corpora, determining which data contributed to training has become essential for copyright enforcement, compliance auditing, and user trust. While prior work focuses on detecting whether a dataset was used in training (membership inference), the complementary problem -- verifying that a dataset was not used -- has received little attention. We address this gap by introducing PRISM, a test that detects dataset-level non-membership using only grey-box access to model logits. Our key insight is that two models that have not seen a dataset exhibit higher rank correlation in their normalized token log probabilities than when one model has been trained on that data. Using this observation, we construct a correlation-based test that detects non-membership. Empirically, PRISM reliably rules out membership in training data across all datasets tested while avoiding false positives, thus offering a framework for verifying that specific datasets were excluded from LLM training.
ExStrucTiny: A Benchmark for Schema-Variable Structured Information Extraction from Document Images
Feb 12, 2026Enterprise documents, such as forms and reports, embed critical information for downstream applications like data archiving, automated workflows, and analytics. Although generalist Vision Language Models (VLMs) perform well on established document understanding benchmarks, their ability to conduct holistic, fine-grained structured extraction across diverse document types and flexible schemas is not well studied. Existing Key Entity Extraction (KEE), Relation Extraction (RE), and Visual Question Answering (VQA) datasets are limited by narrow entity ontologies, simple queries, or homogeneous document types, often overlooking the need for adaptable and structured extraction. To address these gaps, we introduce ExStrucTiny, a new benchmark dataset for structured Information Extraction (IE) from document images, unifying aspects of KEE, RE, and VQA. Built through a novel pipeline combining manual and synthetic human-validated samples, ExStrucTiny covers more varied document types and extraction scenarios. We analyze open and closed VLMs on this benchmark, highlighting challenges such as schema adaptation, query under-specification, and answer localization. We hope our work provides a bedrock for improving generalist models for structured IE in documents.
Perturb Your Data: Paraphrase-Guided Training Data Watermarking
Dec 18, 2025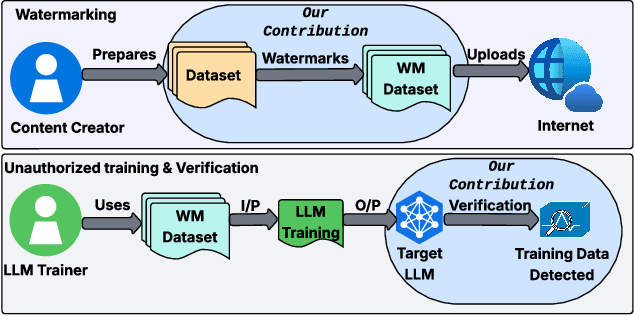
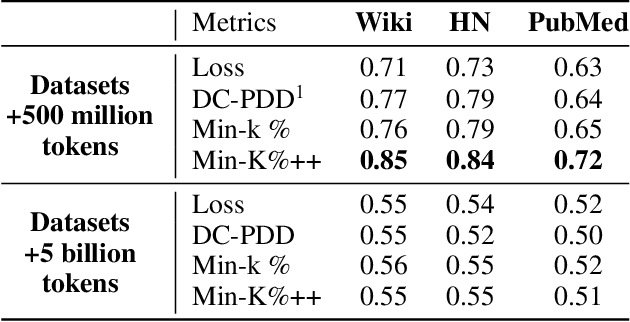
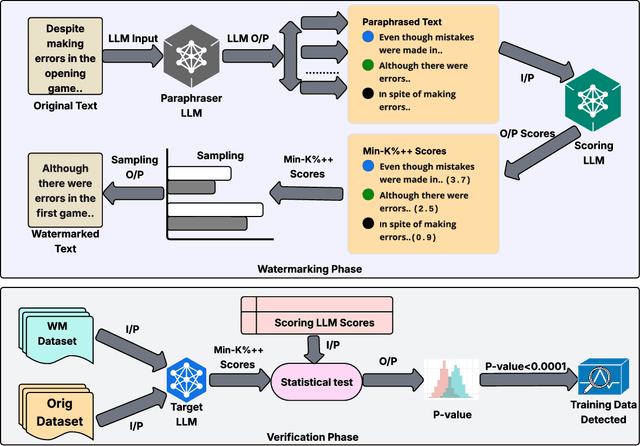
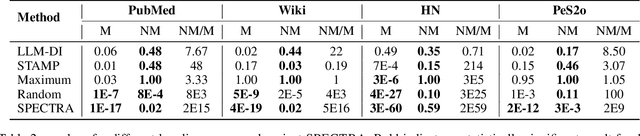
Training data detection is critical for enforcing copyright and data licensing, as Large Language Models (LLM) are trained on massive text corpora scraped from the internet. We present SPECTRA, a watermarking approach that makes training data reliably detectable even when it comprises less than 0.001% of the training corpus. SPECTRA works by paraphrasing text using an LLM and assigning a score based on how likely each paraphrase is, according to a separate scoring model. A paraphrase is chosen so that its score closely matches that of the original text, to avoid introducing any distribution shifts. To test whether a suspect model has been trained on the watermarked data, we compare its token probabilities against those of the scoring model. We demonstrate that SPECTRA achieves a consistent p-value gap of over nine orders of magnitude when detecting data used for training versus data not used for training, which is greater than all baselines tested. SPECTRA equips data owners with a scalable, deploy-before-release watermark that survives even large-scale LLM training.
CoCoLex: Confidence-guided Copy-based Decoding for Grounded Legal Text Generation
Aug 07, 2025Due to their ability to process long and complex contexts, LLMs can offer key benefits to the Legal domain, but their adoption has been hindered by their tendency to generate unfaithful, ungrounded, or hallucinatory outputs. While Retrieval-Augmented Generation offers a promising solution by grounding generations in external knowledge, it offers no guarantee that the provided context will be effectively integrated. To address this, context-aware decoding strategies have been proposed to amplify the influence of relevant context, but they usually do not explicitly enforce faithfulness to the context. In this work, we introduce Confidence-guided Copy-based Decoding for Legal Text Generation (CoCoLex)-a decoding strategy that dynamically interpolates the model produced vocabulary distribution with a distribution derived based on copying from the context. CoCoLex encourages direct copying based on the model's confidence, ensuring greater fidelity to the source. Experimental results on five legal benchmarks demonstrate that CoCoLex outperforms existing context-aware decoding methods, particularly in long-form generation tasks.
Where is this coming from? Making groundedness count in the evaluation of Document VQA models
Mar 24, 2025Document Visual Question Answering (VQA) models have evolved at an impressive rate over the past few years, coming close to or matching human performance on some benchmarks. We argue that common evaluation metrics used by popular benchmarks do not account for the semantic and multimodal groundedness of a model's outputs. As a result, hallucinations and major semantic errors are treated the same way as well-grounded outputs, and the evaluation scores do not reflect the reasoning capabilities of the model. In response, we propose a new evaluation methodology that accounts for the groundedness of predictions with regard to the semantic characteristics of the output as well as the multimodal placement of the output within the input document. Our proposed methodology is parameterized in such a way that users can configure the score according to their preferences. We validate our scoring methodology using human judgment and show its potential impact on existing popular leaderboards. Through extensive analyses, we demonstrate that our proposed method produces scores that are a better indicator of a model's robustness and tends to give higher rewards to better-calibrated answers.
"What is the value of {templates}?" Rethinking Document Information Extraction Datasets for LLMs
Oct 20, 2024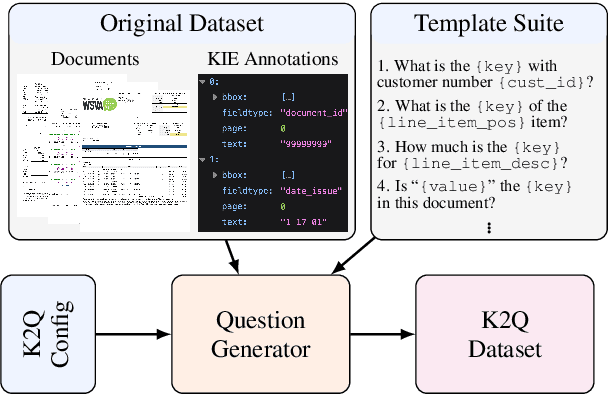
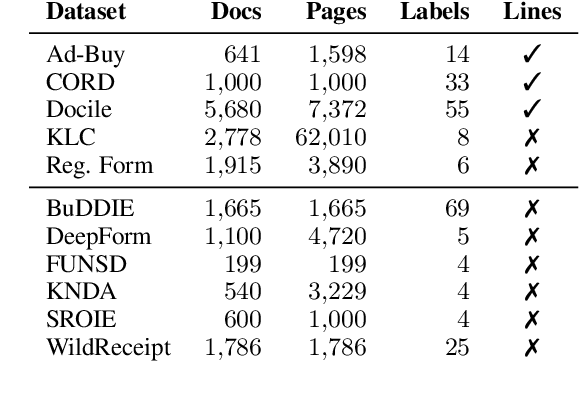

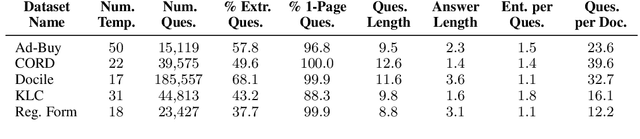
The rise of large language models (LLMs) for visually rich document understanding (VRDU) has kindled a need for prompt-response, document-based datasets. As annotating new datasets from scratch is labor-intensive, the existing literature has generated prompt-response datasets from available resources using simple templates. For the case of key information extraction (KIE), one of the most common VRDU tasks, past work has typically employed the template "What is the value for the {key}?". However, given the variety of questions encountered in the wild, simple and uniform templates are insufficient for creating robust models in research and industrial contexts. In this work, we present K2Q, a diverse collection of five datasets converted from KIE to a prompt-response format using a plethora of bespoke templates. The questions in K2Q can span multiple entities and be extractive or boolean. We empirically compare the performance of seven baseline generative models on K2Q with zero-shot prompting. We further compare three of these models when training on K2Q versus training on simpler templates to motivate the need of our work. We find that creating diverse and intricate KIE questions enhances the performance and robustness of VRDU models. We hope this work encourages future studies on data quality for generative model training.
Accelerating materials discovery for polymer solar cells: Data-driven insights enabled by natural language processing
Feb 29, 2024



We present a natural language processing pipeline that was used to extract polymer solar cell property data from the literature and simulate various active learning strategies. While data-driven methods have been well established to discover novel materials faster than Edisonian trial-and-error approaches, their benefits have not been quantified. Our approach demonstrates a potential reduction in discovery time by approximately 75 %, equivalent to a 15 year acceleration in material innovation. Our pipeline enables us to extract data from more than 3300 papers which is ~5 times larger than similar data sets reported by others. We also trained machine learning models to predict the power conversion efficiency and used our model to identify promising donor-acceptor combinations that are as yet unreported. We thus demonstrate a workflow that goes from published literature to extracted material property data which in turn is used to obtain data-driven insights. Our insights include active learning strategies that can simultaneously optimize the material system and train strong predictive models of material properties. This work provides a valuable framework for research in material science.
PolyIE: A Dataset of Information Extraction from Polymer Material Scientific Literature
Nov 13, 2023



Scientific information extraction (SciIE), which aims to automatically extract information from scientific literature, is becoming more important than ever. However, there are no existing SciIE datasets for polymer materials, which is an important class of materials used ubiquitously in our daily lives. To bridge this gap, we introduce POLYIE, a new SciIE dataset for polymer materials. POLYIE is curated from 146 full-length polymer scholarly articles, which are annotated with different named entities (i.e., materials, properties, values, conditions) as well as their N-ary relations by domain experts. POLYIE presents several unique challenges due to diverse lexical formats of entities, ambiguity between entities, and variable-length relations. We evaluate state-of-the-art named entity extraction and relation extraction models on POLYIE, analyze their strengths and weaknesses, and highlight some difficult cases for these models. To the best of our knowledge, POLYIE is the first SciIE benchmark for polymer materials, and we hope it will lead to more research efforts from the community on this challenging task. Our code and data are available on: https://github.com/jerry3027/PolyIE.
Cross-Geography Generalization of Machine Learning Methods for Classification of Flooded Regions in Aerial Images
Oct 04, 2022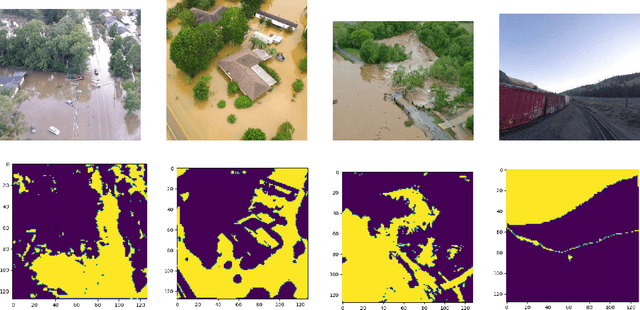
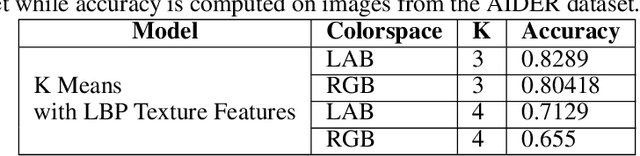
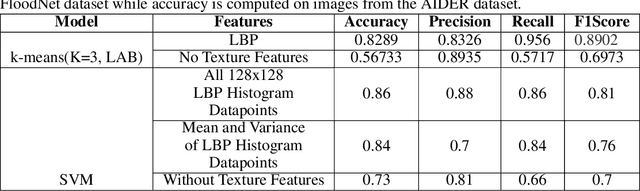
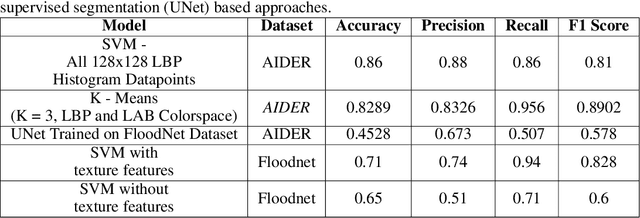
Identification of regions affected by floods is a crucial piece of information required for better planning and management of post-disaster relief and rescue efforts. Traditionally, remote sensing images are analysed to identify the extent of damage caused by flooding. The data acquired from sensors onboard earth observation satellites are analyzed to detect the flooded regions, which can be affected by low spatial and temporal resolution. However, in recent years, the images acquired from Unmanned Aerial Vehicles (UAVs) have also been utilized to assess post-disaster damage. Indeed, a UAV based platform can be rapidly deployed with a customized flight plan and minimum dependence on the ground infrastructure. This work proposes two approaches for identifying flooded regions in UAV aerial images. The first approach utilizes texture-based unsupervised segmentation to detect flooded areas, while the second uses an artificial neural network on the texture features to classify images as flooded and non-flooded. Unlike the existing works where the models are trained and tested on images of the same geographical regions, this work studies the performance of the proposed model in identifying flooded regions across geographical regions. An F1-score of 0.89 is obtained using the proposed segmentation-based approach which is higher than existing classifiers. The robustness of the proposed approach demonstrates that it can be utilized to identify flooded regions of any region with minimum or no user intervention.
A general-purpose material property data extraction pipeline from large polymer corpora using Natural Language Processing
Sep 27, 2022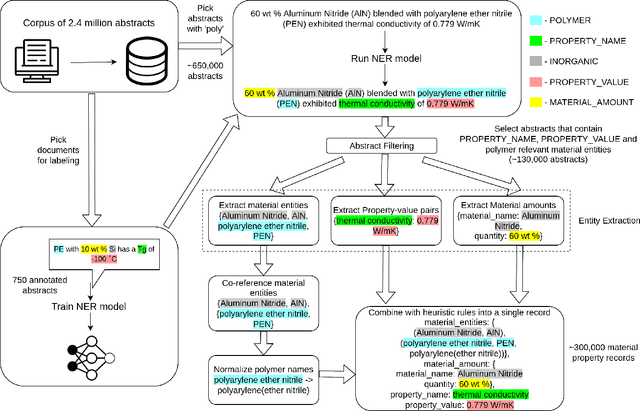
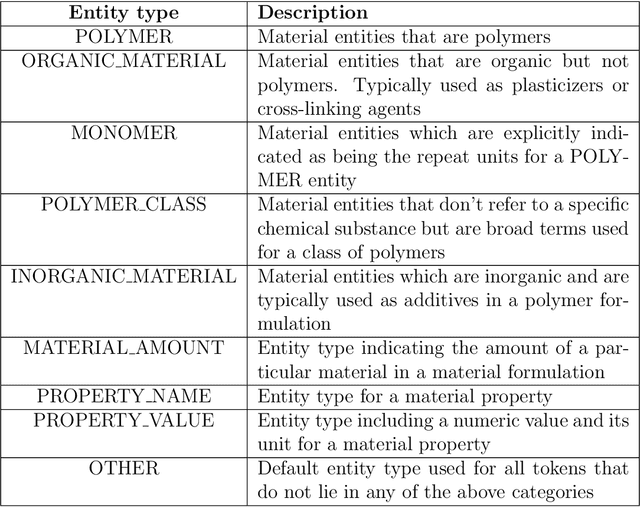
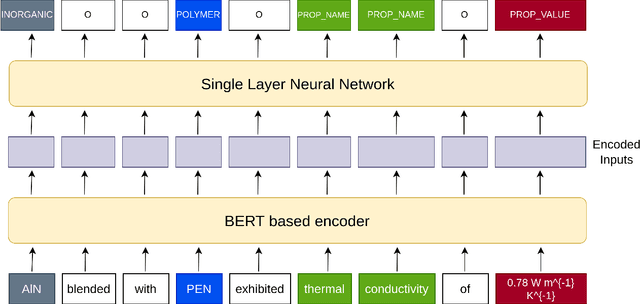
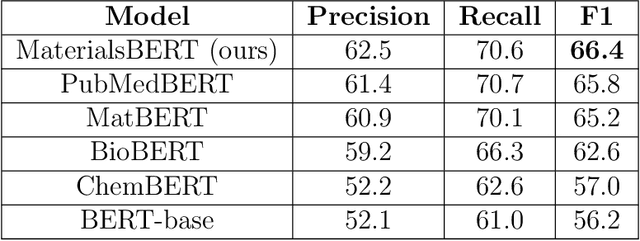
The ever-increasing number of materials science articles makes it hard to infer chemistry-structure-property relations from published literature. We used natural language processing (NLP) methods to automatically extract material property data from the abstracts of polymer literature. As a component of our pipeline, we trained MaterialsBERT, a language model, using 2.4 million materials science abstracts, which outperforms other baseline models in three out of five named entity recognition datasets when used as the encoder for text. Using this pipeline, we obtained ~300,000 material property records from ~130,000 abstracts in 60 hours. The extracted data was analyzed for a diverse range of applications such as fuel cells, supercapacitors, and polymer solar cells to recover non-trivial insights. The data extracted through our pipeline is made available through a web platform at https://polymerscholar.org which can be used to locate material property data recorded in abstracts conveniently. This work demonstrates the feasibility of an automatic pipeline that starts from published literature and ends with a complete set of extracted material property information.