 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoHoSearch: Benchmarking Long-Horizon Search Agents Beyond the Human Difficulty Ceiling
Jun 11, 2026Search agent benchmarks exemplified by BrowseComp have rapidly saturated over the past year, with the strongest models surpassing 90% accuracy. Since these benchmarks are predominantly human-authored, annotators lack a global perspective on entity statistics and cannot systematically maximize search space size and structural complexity. This creates a difficulty ceiling that is hard to break. To address this, we introduce LoHoSearch (Long-Horizon Search Agents), a challenging benchmark comprising 544 human-verified questions across 11 domains. LoHoSearch is constructed via an automated pipeline built upon a knowledge graph covering over 7 million Wikipedia entities, which selects relations with large search spaces and assembles them into structurally complex questions with KG-verified unique answers. Our evaluation demonstrates that even the strongest model achieves only 34.74% accuracy, and existing context management strategies (best +6.8%) yield far smaller gains than on prior benchmarks. LoHoSearch provides a more demanding standard for evaluating long-horizon reasoning and context management in search agents.
QUBRIC: Co-Designing Queries and Rubrics for RL Beyond Verifiable Rewards
Jun 02, 2026Rubric-based RL is a promising route for extending reinforcement learning beyond verifiable rewards, yet existing methods optimize rubrics while treating the query distribution as fixed. We identify a structural bottleneck: rubric quality is constrained by query structure. Open-ended queries yield vague rubrics; naively narrowing them introduces fabricated references that no model can verify, so all responses fail and training receives no reward signal. We present QUBRIC, a framework that co-designs queries and rubrics. Teacher-derived key points ground the rewriting of open-ended queries into scenario-based, evaluable questions. Contrastive rubric generation then turns teacher-policy gaps into query-level criteria, and learnability filtering retains only informative query-rubric pairs for GRPO training. QUBRIC achieves a +5.5 point gain on ArenaHard over the SFT baseline. Trained only on instruction-following data, it further transfers to three held-out benchmarks spanning legal, moral, and narrative reasoning (+6.3 points on average), with improvements concentrated in reasoning-related dimensions. These results provide evidence that co-designing queries and rubrics can make rubric-based RL a practical complement to RLVR beyond strictly verifiable tasks.
HeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
MLE-Dojo: Interactive Environments for Empowering LLM Agents in Machine Learning Engineering
May 12, 2025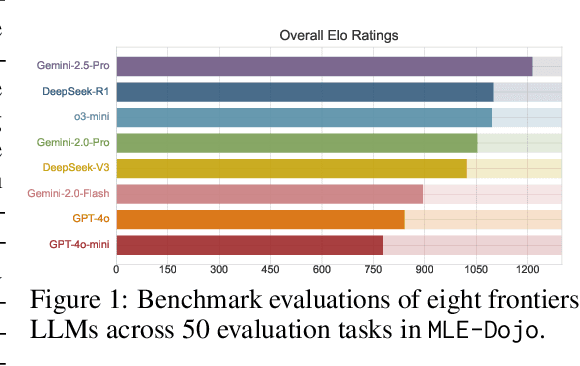



We introduce MLE-Dojo, a Gym-style framework for systematically reinforcement learning, evaluating, and improving autonomous large language model (LLM) agents in iterative machine learning engineering (MLE) workflows. Unlike existing benchmarks that primarily rely on static datasets or single-attempt evaluations, MLE-Dojo provides an interactive environment enabling agents to iteratively experiment, debug, and refine solutions through structured feedback loops. Built upon 200+ real-world Kaggle challenges, MLE-Dojo covers diverse, open-ended MLE tasks carefully curated to reflect realistic engineering scenarios such as data processing, architecture search, hyperparameter tuning, and code debugging. Its fully executable environment supports comprehensive agent training via both supervised fine-tuning and reinforcement learning, facilitating iterative experimentation, realistic data sampling, and real-time outcome verification. Extensive evaluations of eight frontier LLMs reveal that while current models achieve meaningful iterative improvements, they still exhibit significant limitations in autonomously generating long-horizon solutions and efficiently resolving complex errors. Furthermore, MLE-Dojo's flexible and extensible architecture seamlessly integrates diverse data sources, tools, and evaluation protocols, uniquely enabling model-based agent tuning and promoting interoperability, scalability, and reproducibility. We open-source our framework and benchmarks to foster community-driven innovation towards next-generation MLE agents.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
LoRC: Low-Rank Compression for LLMs KV Cache with a Progressive Compression Strategy
Oct 04, 2024



The Key-Value (KV) cache is a crucial component in serving transformer-based autoregressive large language models (LLMs), enabling faster inference by storing previously computed KV vectors. However, its memory consumption scales linearly with sequence length and batch size, posing a significant bottleneck in LLM deployment. Existing approaches to mitigate this issue include: (1) efficient attention variants integrated in upcycling stages, which requires extensive parameter tuning thus unsuitable for pre-trained LLMs; (2) KV cache compression at test time, primarily through token eviction policies, which often overlook inter-layer dependencies and can be task-specific. This paper introduces an orthogonal approach to KV cache compression. We propose a low-rank approximation of KV weight matrices, allowing for plug-in integration with existing transformer-based LLMs without model retraining. To effectively compress KV cache at the weight level, we adjust for layerwise sensitivity and introduce a progressive compression strategy, which is supported by our theoretical analysis on how compression errors accumulate in deep networks. Our method is designed to function without model tuning in upcycling stages or task-specific profiling in test stages. Extensive experiments with LLaMA models ranging from 8B to 70B parameters across various tasks show that our approach significantly reduces the GPU memory footprint while maintaining performance.
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Jun 06, 2024



Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models
Mar 17, 2024Although Large Language Models (LLMs) exhibit remarkable adaptability across domains, these models often fall short in structured knowledge extraction tasks such as named entity recognition (NER). This paper explores an innovative, cost-efficient strategy to harness LLMs with modest NER capabilities for producing superior NER datasets. Our approach diverges from the basic class-conditional prompts by instructing LLMs to self-reflect on the specific domain, thereby generating domain-relevant attributes (such as category and emotions for movie reviews), which are utilized for creating attribute-rich training data. Furthermore, we preemptively generate entity terms and then develop NER context data around these entities, effectively bypassing the LLMs' challenges with complex structures. Our experiments across both general and niche domains reveal significant performance enhancements over conventional data generation methods while being more cost-effective than existing alternatives.
TPD: Enhancing Student Language Model Reasoning via Principle Discovery and Guidance
Jan 24, 2024



Large Language Models (LLMs) have recently showcased remarkable reasoning abilities. However, larger models often surpass their smaller counterparts in reasoning tasks, posing the challenge of effectively transferring these capabilities from larger models. Existing approaches heavily rely on extensive fine-tuning data or continuous interactions with a superior teacher LLM during inference. We introduce a principle-based teacher-student framework called ``Teaching via Principle Discovery'' (TPD) to address these limitations. Inspired by human learning mechanisms, TPD mimics the interaction between a teacher and a student using a principle-based approach. The teacher LLM generates problem-solving instructions and corrective principles based on the student LLM's errors. These principles guide the refinement of instructions and the selection of instructive examples from a validation set. This enables the student model to learn from both the teacher's guidance and its own mistakes. Once the student model begins making inferences, TPD requires no further intervention from the teacher LLM or humans. Through extensive experiments across eight reasoning tasks, we demonstrate the effectiveness of TPD. Compared to standard chain-of-thought prompting, TPD significantly improves the student model's performance, achieving $6.2\%$ improvement on average.