 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReGen: Zero-Shot Text Classification via Training Data Generation with Progressive Dense Retrieval
Paper and Code
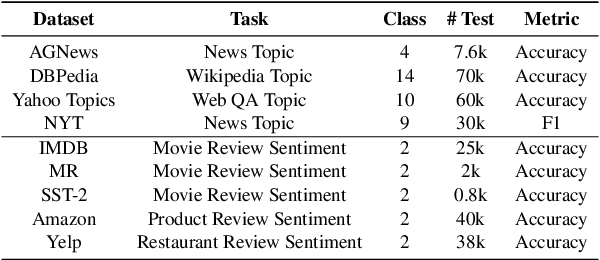

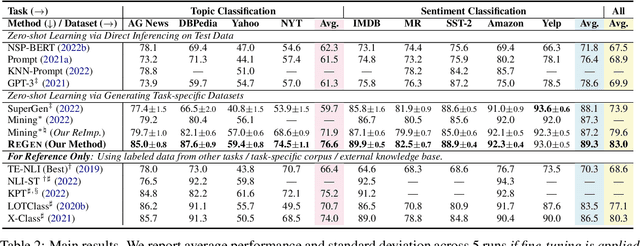
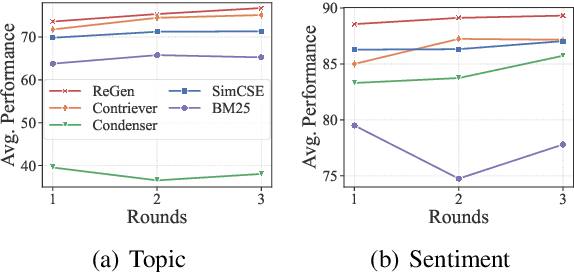
With the development of large language models (LLMs), zero-shot learning has attracted much attention for various NLP tasks. Different from prior works that generate training data with billion-scale natural language generation (NLG) models, we propose a retrieval-enhanced framework to create training data from a general-domain unlabeled corpus. To realize this, we first conduct contrastive pretraining to learn an unsupervised dense retriever for extracting the most relevant documents using class-descriptive verbalizers. We then further propose two simple strategies, namely Verbalizer Augmentation with Demonstrations and Self-consistency Guided Filtering to improve the topic coverage of the dataset while removing noisy examples. Experiments on nine datasets demonstrate that REGEN achieves 4.3% gain over the strongest baselines and saves around 70% of the time compared to baselines using large NLG models. Besides, REGEN can be naturally integrated with recently proposed large language models to boost performance.