 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping for Inference-Time Alignment: A Stackelberg Game Perspective
Jan 31, 2026Existing alignment methods directly use the reward model learned from user preference data to optimize an LLM policy, subject to KL regularization with respect to the base policy. This practice is suboptimal for maximizing user's utility because the KL regularization may cause the LLM to inherit the bias in the base policy that conflicts with user preferences. While amplifying rewards for preferred outputs can mitigate this bias, it also increases the risk of reward hacking. This tradeoff motivates the problem of optimally designing reward models under KL regularization. We formalize this reward model optimization problem as a Stackelberg game, and show that a simple reward shaping scheme can effectively approximate the optimal reward model. We empirically evaluate our method in inference-time alignment settings and demonstrate that it integrates seamlessly into existing alignment methods with minimal overhead. Our method consistently improves average reward and achieves win-tie rates exceeding 66% against all baselines, averaged across evaluation settings.
Latent Spherical Flow Policy for Reinforcement Learning with Combinatorial Actions
Jan 29, 2026Reinforcement learning (RL) with combinatorial action spaces remains challenging because feasible action sets are exponentially large and governed by complex feasibility constraints, making direct policy parameterization impractical. Existing approaches embed task-specific value functions into constrained optimization programs or learn deterministic structured policies, sacrificing generality and policy expressiveness. We propose a solver-induced \emph{latent spherical flow policy} that brings the expressiveness of modern generative policies to combinatorial RL while guaranteeing feasibility by design. Our method, LSFlow, learns a \emph{stochastic} policy in a compact continuous latent space via spherical flow matching, and delegates feasibility to a combinatorial optimization solver that maps each latent sample to a valid structured action. To improve efficiency, we train the value network directly in the latent space, avoiding repeated solver calls during policy optimization. To address the piecewise-constant and discontinuous value landscape induced by solver-based action selection, we introduce a smoothed Bellman operator that yields stable, well-defined learning targets. Empirically, our approach outperforms state-of-the-art baselines by an average of 20.6\% across a range of challenging combinatorial RL tasks.
Policy-Embedded Graph Expansion: Networked HIV Testing with Diffusion-Driven Network Samples
Jan 20, 2026HIV is a retrovirus that attacks the human immune system and can lead to death without proper treatment. In collaboration with the WHO and Wits University, we study how to improve the efficiency of HIV testing with the goal of eventual deployment, directly supporting progress toward UN Sustainable Development Goal 3.3. While prior work has demonstrated the promise of intelligent algorithms for sequential, network-based HIV testing, existing approaches rely on assumptions that are impractical in our real-world implementations. Here, we study sequential testing on incrementally revealed disease networks and introduce Policy-Embedded Graph Expansion (PEGE), a novel framework that directly embeds a generative distribution over graph expansions into the decision-making policy rather than attempting explicit topological reconstruction. We further propose Dynamics-Driven Branching (DDB), a diffusion-based graph expansion model that supports decision making in PEGE and is designed for data-limited settings where forest structures arise naturally, as in our real-world referral process. Experiments on real HIV transmission networks show that the combined approach (PEGE + DDB) consistently outperforms existing baselines (e.g., 13% improvement in discounted reward and 9% more HIV detections with 25% of the population tested) and explore key tradeoffs that drive decision quality.
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Dec 12, 2025Large Reasoning Models (LRMs) have expanded the mathematical reasoning frontier through Chain-of-Thought (CoT) techniques and Reinforcement Learning with Verifiable Rewards (RLVR), capable of solving AIME-level problems. However, the performance of LRMs is heavily dependent on the extended reasoning context length. For solving ultra-hard problems like those in the International Mathematical Olympiad (IMO), the required reasoning complexity surpasses the space that an LRM can explore in a single round. Previous works attempt to extend the reasoning context of LRMs but remain prompt-based and built upon proprietary models, lacking systematic structures and training pipelines. Therefore, this paper introduces Intern-S1-MO, a long-horizon math agent that conducts multi-round hierarchical reasoning, composed of an LRM-based multi-agent system including reasoning, summary, and verification. By maintaining a compact memory in the form of lemmas, Intern-S1-MO can more freely explore the lemma-rich reasoning spaces in multiple reasoning stages, thereby breaking through the context constraints for IMO-level math problems. Furthermore, we propose OREAL-H, an RL framework for training the LRM using the online explored trajectories to simultaneously bootstrap the reasoning ability of LRM and elevate the overall performance of Intern-S1-MO. Experiments show that Intern-S1-MO can obtain 26 out of 35 points on the non-geometry problems of IMO2025, matching the performance of silver medalists. It also surpasses the current advanced LRMs on inference benchmarks such as HMMT2025, AIME2025, and CNMO2025. In addition, our agent officially participates in CMO2025 and achieves a score of 102/126 under the judgment of human experts, reaching the gold medal level.
Guided Transfer Learning for Discrete Diffusion Models
Dec 11, 2025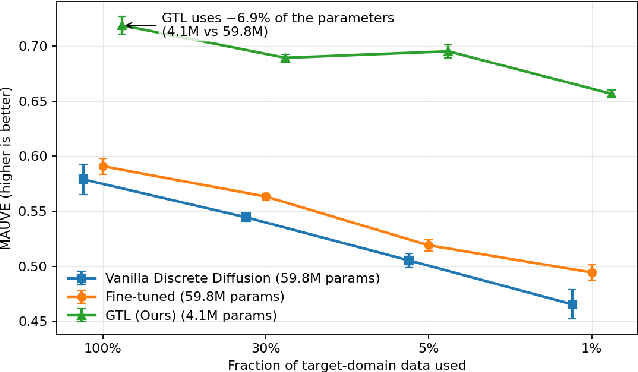

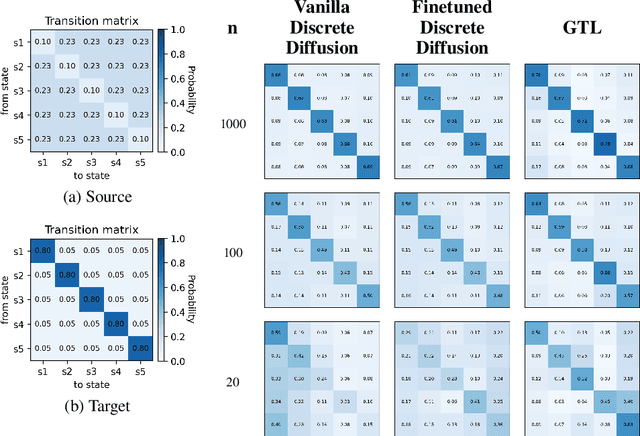
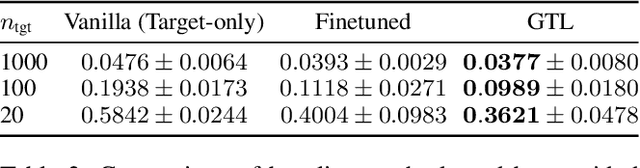
Discrete diffusion models achieve strong performance across language and other discrete domains, providing a powerful alternative to autoregressive models. However, their strong performance relies on large training datasets, which are costly or risky to obtain, especially when adapting to new domains. Transfer learning is the natural way to adapt pretrained discrete diffusion models, but current methods require fine-tuning large diffusion models, which is computationally expensive and often impractical. Building on ratio-based transfer learning for continuous diffusion, we provide Guided Transfer Learning for discrete diffusion models (GTL). This enables sampling from a target distribution without modifying the pretrained denoiser. The same guidance formulation applies to both discrete-time diffusion and continuous-time score-based discrete diffusion, yielding a unified treatment. Guided discrete diffusion often requires many forward passes of the guidance network, which becomes impractical for large vocabularies and long sequences. To address this, we further present an efficient guided sampler that concentrates evaluations on planner-selected positions and top candidate tokens, thus lowering sampling time and computation. This makes guided language modeling practical at scale for large vocabularies and long sequences. We evaluate GTL on sequential data, including synthetic Markov chains and language modeling, and provide empirical analyses of its behavior.
OPV: Outcome-based Process Verifier for Efficient Long Chain-of-Thought Verification
Dec 11, 2025Large language models (LLMs) have achieved significant progress in solving complex reasoning tasks by Reinforcement Learning with Verifiable Rewards (RLVR). This advancement is also inseparable from the oversight automated by reliable verifiers. However, current outcome-based verifiers (OVs) are unable to inspect the unreliable intermediate steps in the long reasoning chains of thought (CoTs). Meanwhile, current process-based verifiers (PVs) have difficulties in reliably detecting errors in the complex long CoTs, limited by the scarcity of high-quality annotations due to the prohibitive costs of human annotations. Therefore, we propose the Outcome-based Process Verifier (OPV), which verifies the rationale process of summarized outcomes from long CoTs to achieve both accurate and efficient verification and enable large-scale annotation. To empower the proposed verifier, we adopt an iterative active learning framework with expert annotations to progressively improve the verification capability of OPV with fewer annotation costs. Specifically, in each iteration, the most uncertain cases of the current best OPV are annotated and then subsequently used to train a new OPV through Rejection Fine-Tuning (RFT) and RLVR for the next round. Extensive experiments demonstrate OPV's superior performance and broad applicability. It achieves new state-of-the-art results on our held-out OPV-Bench, outperforming much larger open-source models such as Qwen3-Max-Preview with an F1 score of 83.1 compared to 76.3. Furthermore, OPV effectively detects false positives within synthetic dataset, closely align with expert assessment. When collaborating with policy models, OPV consistently yields performance gains, e.g., raising the accuracy of DeepSeek-R1-Distill-Qwen-32B from 55.2% to 73.3% on AIME2025 as the compute budget scales.
Generative AI Against Poaching: Latent Composite Flow Matching for Wildlife Conservation
Aug 20, 2025
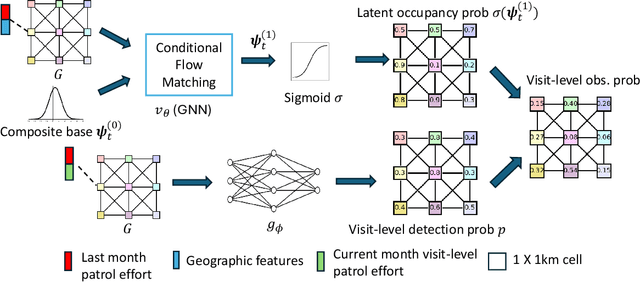
Poaching poses significant threats to wildlife and biodiversity. A valuable step in reducing poaching is to forecast poacher behavior, which can inform patrol planning and other conservation interventions. Existing poaching prediction methods based on linear models or decision trees lack the expressivity to capture complex, nonlinear spatiotemporal patterns. Recent advances in generative modeling, particularly flow matching, offer a more flexible alternative. However, training such models on real-world poaching data faces two central obstacles: imperfect detection of poaching events and limited data. To address imperfect detection, we integrate flow matching with an occupancy-based detection model and train the flow in latent space to infer the underlying occupancy state. To mitigate data scarcity, we adopt a composite flow initialized from a linear-model prediction rather than random noise which is the standard in diffusion models, injecting prior knowledge and improving generalization. Evaluations on datasets from two national parks in Uganda show consistent gains in predictive accuracy.
Composite Flow Matching for Reinforcement Learning with Shifted-Dynamics Data
May 29, 2025Incorporating pre-collected offline data from a source environment can significantly improve the sample efficiency of reinforcement learning (RL), but this benefit is often challenged by discrepancies between the transition dynamics of the source and target environments. Existing methods typically address this issue by penalizing or filtering out source transitions in high dynamics-gap regions. However, their estimation of the dynamics gap often relies on KL divergence or mutual information, which can be ill-defined when the source and target dynamics have disjoint support. To overcome these limitations, we propose CompFlow, a method grounded in the theoretical connection between flow matching and optimal transport. Specifically, we model the target dynamics as a conditional flow built upon the output distribution of the source-domain flow, rather than learning it directly from a Gaussian prior. This composite structure offers two key advantages: (1) improved generalization for learning target dynamics, and (2) a principled estimation of the dynamics gap via the Wasserstein distance between source and target transitions. Leveraging our principled estimation of the dynamics gap, we further introduce an optimistic active data collection strategy that prioritizes exploration in regions of high dynamics gap, and theoretically prove that it reduces the performance disparity with the optimal policy. Empirically, CompFlow outperforms strong baselines across several RL benchmarks with shifted dynamics.
LLM-Augmented Chemical Synthesis and Design Decision Programs
May 11, 2025Retrosynthesis, the process of breaking down a target molecule into simpler precursors through a series of valid reactions, stands at the core of organic chemistry and drug development. Although recent machine learning (ML) research has advanced single-step retrosynthetic modeling and subsequent route searches, these solutions remain restricted by the extensive combinatorial space of possible pathways. Concurrently, large language models (LLMs) have exhibited remarkable chemical knowledge, hinting at their potential to tackle complex decision-making tasks in chemistry. In this work, we explore whether LLMs can successfully navigate the highly constrained, multi-step retrosynthesis planning problem. We introduce an efficient scheme for encoding reaction pathways and present a new route-level search strategy, moving beyond the conventional step-by-step reactant prediction. Through comprehensive evaluations, we show that our LLM-augmented approach excels at retrosynthesis planning and extends naturally to the broader challenge of synthesizable molecular design.
What is the Right Notion of Distance between Predict-then-Optimize Tasks?
Sep 11, 2024Comparing datasets is a fundamental task in machine learning, essential for various learning paradigms; from evaluating train and test datasets for model generalization to using dataset similarity for detecting data drift. While traditional notions of dataset distances offer principled measures of similarity, their utility has largely been assessed through prediction error minimization. However, in Predict-then-Optimize (PtO) frameworks, where predictions serve as inputs for downstream optimization tasks, model performance is measured through decision regret minimization rather than prediction error minimization. In this work, we (i) show that traditional dataset distances, which rely solely on feature and label dimensions, lack informativeness in the PtO context, and (ii) propose a new dataset distance that incorporates the impacts of downstream decisions. Our results show that this decision-aware dataset distance effectively captures adaptation success in PtO contexts, providing a PtO adaptation bound in terms of dataset distance. Empirically, we show that our proposed distance measure accurately predicts transferability across three different PtO tasks from the literature.