 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilevel Optimization of Synthetic Trajectories for Multi-Turn LLM Fine-Tuning
May 23, 2026While LLMs excel at single-turn generation, they struggle with long-horizon, multi-turn interactions. Offline reinforcement learning (RL) offers a scalable approach, yet its performance hinges on the availability and quality of multi-turn trajectory data. A common remedy is to augment training with synthetic trajectories generated by LLMs or simulators, but synthetic data is highly heterogeneous in quality, and naively treating all trajectories as equally informative can degrade performance. We propose BOOST, a bilevel optimization framework where the inner level trains the LLM on reweighted data and the outer level trains a lightweight reweighting head on held-out real validation tasks, assigning continuous trajectory-level weights without requiring an external judge. To ground this approach, we derive a PAC-Bayesian bound revealing a three-way trade-off: synthetic data increases diversity but risks task-shift, while concentrating weight on high-quality trajectories improves empirical performance at the cost of effective sample size. Empirically, our method consistently outperforms multiple baselines. Analysis reveals it upweights synthetic trajectories that align with the real data distribution and exhibit higher qualitative merit.
Decisions and Deployment: The Five-Year SAHELI Project (2020-2025) on Restless Multi-Armed Bandits for Improving Maternal and Child Health
Apr 08, 2026Maternal and child health is a critical concern around the world. In many global health programs disseminating preventive care and health information, limited healthcare worker resources prevent continuous, personalised engagement with vulnerable beneficiaries. In such scenarios, it becomes crucial to optimally schedule limited live-service resources to maximise long-term engagement. To address this fundamental challenge, the multi-year SAHELI project (2020-2025), in collaboration with partner NGO ARMMAN, leverages AI to allocate scarce resources in a maternal and child health program in India. The SAHELI system solves this sequential resource allocation problem using a Restless Multi-Armed Bandit (RMAB) framework. A key methodological innovation is the transition from a traditional Two-Stage "predict-then-optimize" approach to Decision-Focused Learning (DFL), which directly aligns the framework's learning method with the ultimate goal of maximizing beneficiary engagement. Empirical evaluation through large-scale randomized controlled trials demonstrates that the DFL policy reduced cumulative engagement drops by 31% relative to the current standard of care, significantly outperforming the Two-Stage model. Crucially, the studies also confirmed that this increased program engagement translates directly into statistically significant improvements in real-world health behaviors, notably the continued consumption of vital iron and calcium supplements by new mothers. Ultimately, the SAHELI project provides a scalable blueprint for applying sequential decision-making AI to optimize resource allocation in health programs.
Measuring Fairness in Financial Transaction Machine Learning Models
Jan 18, 2025



Mastercard, a global leader in financial services, develops and deploys machine learning models aimed at optimizing card usage and preventing attrition through advanced predictive models. These models use aggregated and anonymized card usage patterns, including cross-border transactions and industry-specific spending, to tailor bank offerings and maximize revenue opportunities. Mastercard has established an AI Governance program, based on its Data and Tech Responsibility Principles, to evaluate any built and bought AI for efficacy, fairness, and transparency. As part of this effort, Mastercard has sought expertise from the Turing Institute through a Data Study Group to better assess fairness in more complex AI/ML models. The Data Study Group challenge lies in defining, measuring, and mitigating fairness in these predictions, which can be complex due to the various interpretations of fairness, gaps in the research literature, and ML-operations challenges.
Balancing Act: Prioritization Strategies for LLM-Designed Restless Bandit Rewards
Aug 22, 2024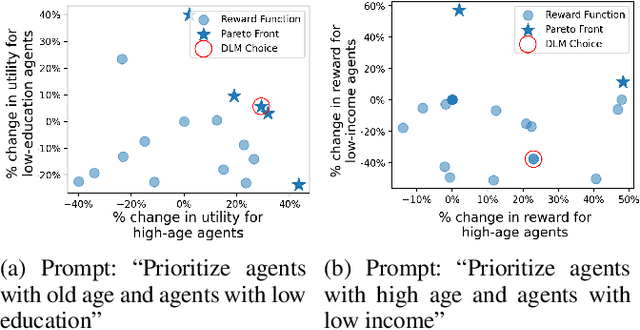



LLMs are increasingly used to design reward functions based on human preferences in Reinforcement Learning (RL). We focus on LLM-designed rewards for Restless Multi-Armed Bandits, a framework for allocating limited resources among agents. In applications such as public health, this approach empowers grassroots health workers to tailor automated allocation decisions to community needs. In the presence of multiple agents, altering the reward function based on human preferences can impact subpopulations very differently, leading to complex tradeoffs and a multi-objective resource allocation problem. We are the first to present a principled method termed Social Choice Language Model for dealing with these tradeoffs for LLM-designed rewards for multiagent planners in general and restless bandits in particular. The novel part of our model is a transparent and configurable selection component, called an adjudicator, external to the LLM that controls complex tradeoffs via a user-selected social welfare function. Our experiments demonstrate that our model reliably selects more effective, aligned, and balanced reward functions compared to purely LLM-based approaches.
Analyzing and Predicting Low-Listenership Trends in a Large-Scale Mobile Health Program: A Preliminary Investigation
Nov 13, 2023Mobile health programs are becoming an increasingly popular medium for dissemination of health information among beneficiaries in less privileged communities. Kilkari is one of the world's largest mobile health programs which delivers time sensitive audio-messages to pregnant women and new mothers. We have been collaborating with ARMMAN, a non-profit in India which operates the Kilkari program, to identify bottlenecks to improve the efficiency of the program. In particular, we provide an initial analysis of the trajectories of beneficiaries' interaction with the mHealth program and examine elements of the program that can be potentially enhanced to boost its success. We cluster the cohort into different buckets based on listenership so as to analyze listenership patterns for each group that could help boost program success. We also demonstrate preliminary results on using historical data in a time-series prediction to identify beneficiary dropouts and enable NGOs in devising timely interventions to strengthen beneficiary retention.
Limited Resource Allocation in a Non-Markovian World: The Case of Maternal and Child Healthcare
May 22, 2023The success of many healthcare programs depends on participants' adherence. We consider the problem of scheduling interventions in low resource settings (e.g., placing timely support calls from health workers) to increase adherence and/or engagement. Past works have successfully developed several classes of Restless Multi-armed Bandit (RMAB) based solutions for this problem. Nevertheless, all past RMAB approaches assume that the participants' behaviour follows the Markov property. We demonstrate significant deviations from the Markov assumption on real-world data on a maternal health awareness program from our partner NGO, ARMMAN. Moreover, we extend RMABs to continuous state spaces, a previously understudied area. To tackle the generalised non-Markovian RMAB setting we (i) model each participant's trajectory as a time-series, (ii) leverage the power of time-series forecasting models to learn complex patterns and dynamics to predict future states, and (iii) propose the Time-series Arm Ranking Index (TARI) policy, a novel algorithm that selects the RMAB arms that will benefit the most from an intervention, given our future state predictions. We evaluate our approach on both synthetic data, and a secondary analysis on real data from ARMMAN, and demonstrate significant increase in engagement compared to the SOTA, deployed Whittle index solution. This translates to 16.3 hours of additional content listened, 90.8% more engagement drops prevented, and reaching more than twice as many high dropout-risk beneficiaries.
Decision-Focused Evaluation: Analyzing Performance of Deployed Restless Multi-Arm Bandits
Jan 19, 2023Restless multi-arm bandits (RMABs) is a popular decision-theoretic framework that has been used to model real-world sequential decision making problems in public health, wildlife conservation, communication systems, and beyond. Deployed RMAB systems typically operate in two stages: the first predicts the unknown parameters defining the RMAB instance, and the second employs an optimization algorithm to solve the constructed RMAB instance. In this work we provide and analyze the results from a first-of-its-kind deployment of an RMAB system in public health domain, aimed at improving maternal and child health. Our analysis is focused towards understanding the relationship between prediction accuracy and overall performance of deployed RMAB systems. This is crucial for determining the value of investing in improving predictive accuracy towards improving the final system performance, and is useful for diagnosing, monitoring deployed RMAB systems. Using real-world data from our deployed RMAB system, we demonstrate that an improvement in overall prediction accuracy may even be accompanied by a degradation in the performance of RMAB system -- a broad investment of resources to improve overall prediction accuracy may not yield expected results. Following this, we develop decision-focused evaluation metrics to evaluate the predictive component and show that it is better at explaining (both empirically and theoretically) the overall performance of a deployed RMAB system.
Decision-Focused Learning in Restless Multi-Armed Bandits with Application to Maternal and Child Care Domain
Feb 02, 2022
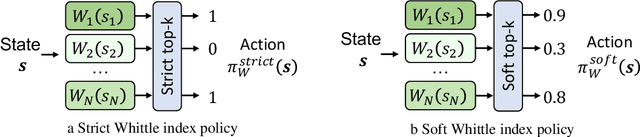

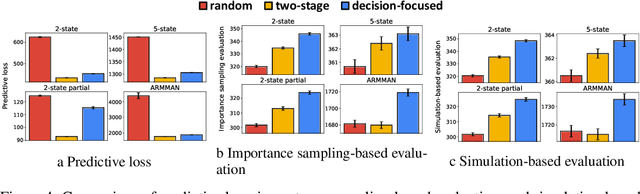
This paper studies restless multi-armed bandit (RMAB) problems with unknown arm transition dynamics but with known correlated arm features. The goal is to learn a model to predict transition dynamics given features, where the Whittle index policy solves the RMAB problems using predicted transitions. However, prior works often learn the model by maximizing the predictive accuracy instead of final RMAB solution quality, causing a mismatch between training and evaluation objectives. To address this shortcoming we propose a novel approach for decision-focused learning in RMAB that directly trains the predictive model to maximize the Whittle index solution quality. We present three key contributions: (i) we establish the differentiability of the Whittle index policy to support decision-focused learning; (ii) we significantly improve the scalability of previous decision-focused learning approaches in sequential problems; (iii) we apply our algorithm to the service call scheduling problem on a real-world maternal and child health domain. Our algorithm is the first for decision-focused learning in RMAB that scales to large-scale real-world problems. \end{abstract}
Field Study in Deploying Restless Multi-Armed Bandits: Assisting Non-Profits in Improving Maternal and Child Health
Sep 16, 2021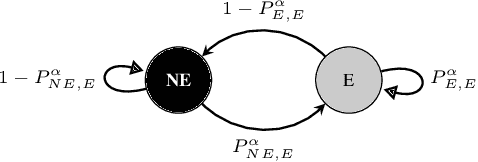
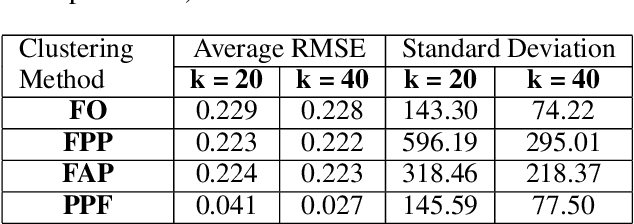
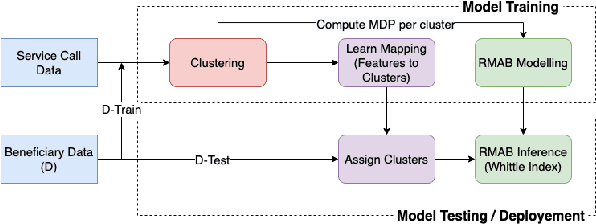
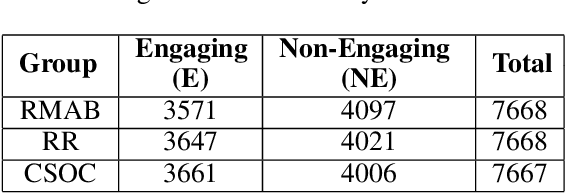
The widespread availability of cell phones has enabled non-profits to deliver critical health information to their beneficiaries in a timely manner. This paper describes our work to assist non-profits that employ automated messaging programs to deliver timely preventive care information to beneficiaries (new and expecting mothers) during pregnancy and after delivery. Unfortunately, a key challenge in such information delivery programs is that a significant fraction of beneficiaries drop out of the program. Yet, non-profits often have limited health-worker resources (time) to place crucial service calls for live interaction with beneficiaries to prevent such engagement drops. To assist non-profits in optimizing this limited resource, we developed a Restless Multi-Armed Bandits (RMABs) system. One key technical contribution in this system is a novel clustering method of offline historical data to infer unknown RMAB parameters. Our second major contribution is evaluation of our RMAB system in collaboration with an NGO, via a real-world service quality improvement study. The study compared strategies for optimizing service calls to 23003 participants over a period of 7 weeks to reduce engagement drops. We show that the RMAB group provides statistically significant improvement over other comparison groups, reducing ~ 30% engagement drops. To the best of our knowledge, this is the first study demonstrating the utility of RMABs in real world public health settings. We are transitioning our RMAB system to the NGO for real-world use.
Deep Reinforcement Learning for Single-Shot Diagnosis and Adaptation in Damaged Robots
Oct 02, 2019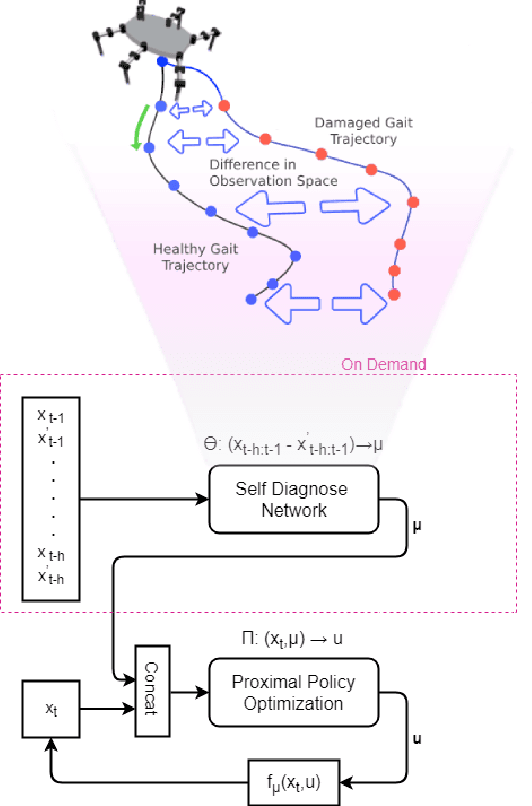

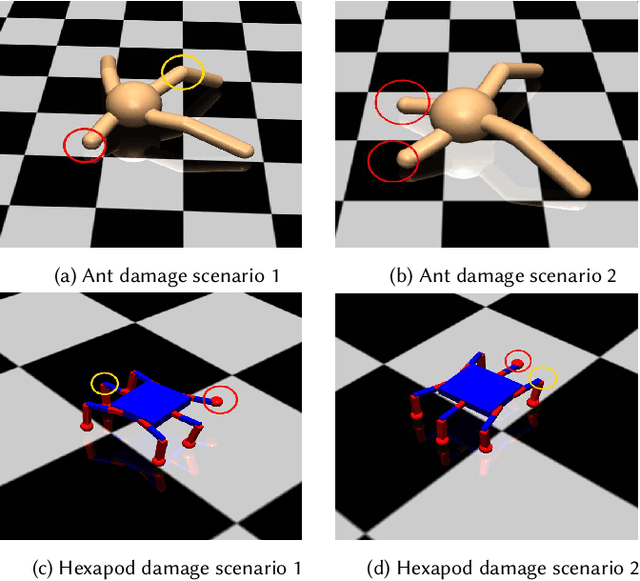
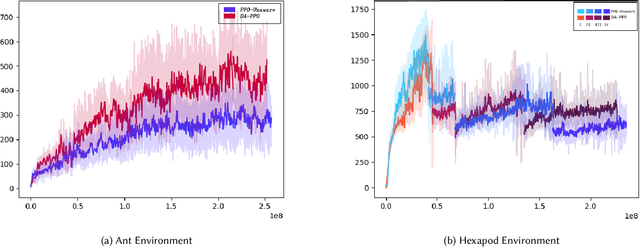
Robotics has proved to be an indispensable tool in many industrial as well as social applications, such as warehouse automation, manufacturing, disaster robotics, etc. In most of these scenarios, damage to the agent while accomplishing mission-critical tasks can result in failure. To enable robotic adaptation in such situations, the agent needs to adopt policies which are robust to a diverse set of damages and must do so with minimum computational complexity. We thus propose a damage aware control architecture which diagnoses the damage prior to gait selection while also incorporating domain randomization in the damage space for learning a robust policy. To implement damage awareness, we have used a Long Short Term Memory based supervised learning network which diagnoses the damage and predicts the type of damage. The main novelty of this approach is that only a single policy is trained to adapt against a wide variety of damages and the diagnosis is done in a single trial at the time of damage.