 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy But Effective: Collaborative Personalized Federated Learning with Heterogeneous Data
May 05, 2025In Federated Learning, heterogeneity in client data distributions often means that a single global model does not have the best performance for individual clients. Consider for example training a next-word prediction model for keyboards: user-specific language patterns due to demographics (dialect, age, etc.), language proficiency, and writing style result in a highly non-IID dataset across clients. Other examples are medical images taken with different machines, or driving data from different vehicle types. To address this, we propose a simple yet effective personalized federated learning framework (pFedLIA) that utilizes a computationally efficient influence approximation, called `Lazy Influence', to cluster clients in a distributed manner before model aggregation. Within each cluster, data owners collaborate to jointly train a model that captures the specific data patterns of the clients. Our method has been shown to successfully recover the global model's performance drop due to the non-IID-ness in various synthetic and real-world settings, specifically a next-word prediction task on the Nordic languages as well as several benchmark tasks. It matches the performance of a hypothetical Oracle clustering, and significantly improves on existing baselines, e.g., an improvement of 17% on CIFAR100.
Limited Resource Allocation in a Non-Markovian World: The Case of Maternal and Child Healthcare
May 22, 2023The success of many healthcare programs depends on participants' adherence. We consider the problem of scheduling interventions in low resource settings (e.g., placing timely support calls from health workers) to increase adherence and/or engagement. Past works have successfully developed several classes of Restless Multi-armed Bandit (RMAB) based solutions for this problem. Nevertheless, all past RMAB approaches assume that the participants' behaviour follows the Markov property. We demonstrate significant deviations from the Markov assumption on real-world data on a maternal health awareness program from our partner NGO, ARMMAN. Moreover, we extend RMABs to continuous state spaces, a previously understudied area. To tackle the generalised non-Markovian RMAB setting we (i) model each participant's trajectory as a time-series, (ii) leverage the power of time-series forecasting models to learn complex patterns and dynamics to predict future states, and (iii) propose the Time-series Arm Ranking Index (TARI) policy, a novel algorithm that selects the RMAB arms that will benefit the most from an intervention, given our future state predictions. We evaluate our approach on both synthetic data, and a secondary analysis on real data from ARMMAN, and demonstrate significant increase in engagement compared to the SOTA, deployed Whittle index solution. This translates to 16.3 hours of additional content listened, 90.8% more engagement drops prevented, and reaching more than twice as many high dropout-risk beneficiaries.
Privacy-preserving Data Filtering in Federated Learning Using Influence Approximation
May 23, 2022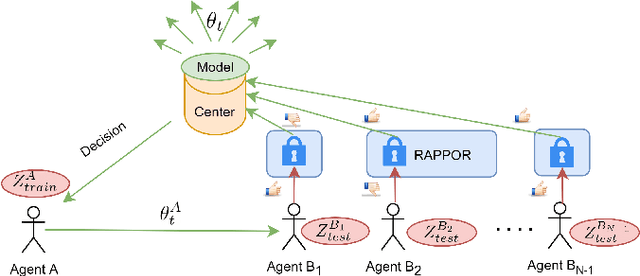
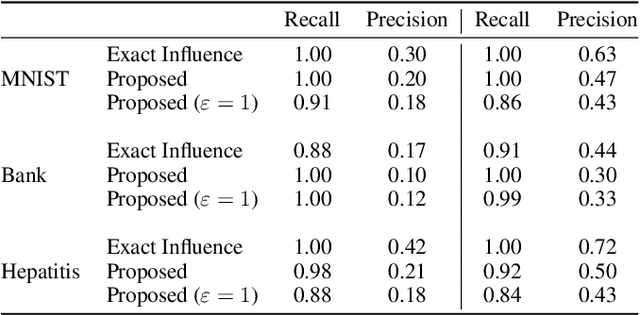
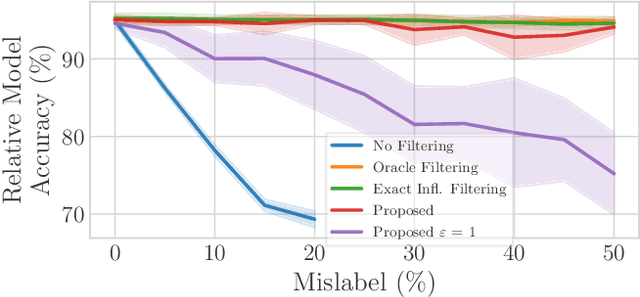
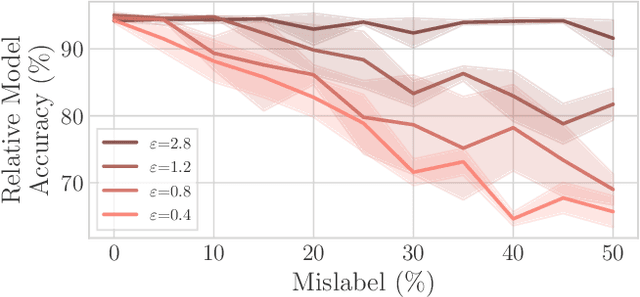
Federated Learning by nature is susceptible to low-quality, corrupted, or even malicious data that can severely degrade the quality of the learned model. Traditional techniques for data valuation cannot be applied as the data is never revealed. We present a novel technique for filtering, and scoring data based on a practical influence approximation that can be implemented in a privacy-preserving manner. Each agent uses his own data to evaluate the influence of another agent's batch, and reports to the center an obfuscated score using differential privacy. Our technique allows for almost perfect ($>92\%$ recall) filtering of corrupted data in a variety of applications using real-data. Importantly, the accuracy does not degrade significantly, even under really strong privacy guarantees ($\varepsilon \leq 1$), especially under realistic percentages of mislabeled data (for $15\%$ mislabeled data we only lose $10\%$ in accuracy).
Achieving Diverse Objectives with AI-driven Prices in Deep Reinforcement Learning Multi-agent Markets
Jun 10, 2021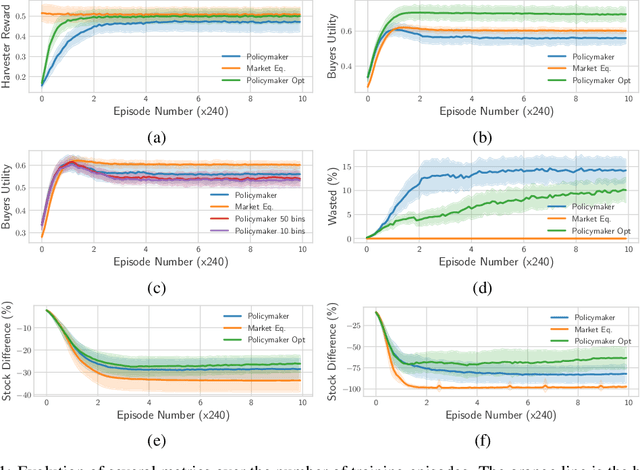
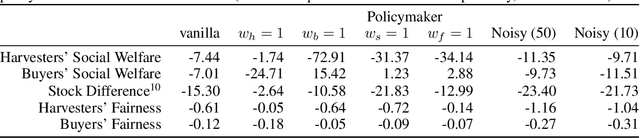

We propose a practical approach to computing market prices and allocations via a deep reinforcement learning policymaker agent, operating in an environment of other learning agents. Compared to the idealized market equilibrium outcome -- which we use as a benchmark -- our policymaker is much more flexible, allowing us to tune the prices with regard to diverse objectives such as sustainability and resource wastefulness, fairness, buyers' and sellers' welfare, etc. To evaluate our approach, we design a realistic market with multiple and diverse buyers and sellers. Additionally, the sellers, which are deep learning agents themselves, compete for resources in a common-pool appropriation environment based on bio-economic models of commercial fisheries. We demonstrate that: (a) The introduced policymaker is able to achieve comparable performance to the market equilibrium, showcasing the potential of such approaches in markets where the equilibrium prices can not be efficiently computed. (b) Our policymaker can notably outperform the equilibrium solution on certain metrics, while at the same time maintaining comparable performance for the remaining ones. (c) As a highlight of our findings, our policymaker is significantly more successful in maintaining resource sustainability, compared to the market outcome, in scarce resource environments.
Improving Multi-agent Coordination by Learning to Estimate Contention
May 09, 2021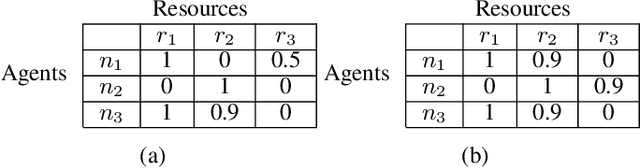
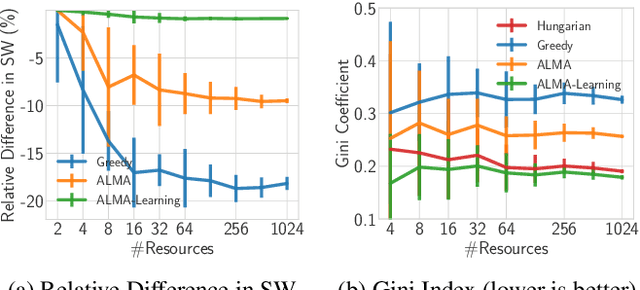
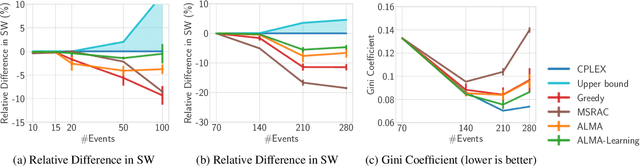

We present a multi-agent learning algorithm, ALMA-Learning, for efficient and fair allocations in large-scale systems. We circumvent the traditional pitfalls of multi-agent learning (e.g., the moving target problem, the curse of dimensionality, or the need for mutually consistent actions) by relying on the ALMA heuristic as a coordination mechanism for each stage game. ALMA-Learning is decentralized, observes only own action/reward pairs, requires no inter-agent communication, and achieves near-optimal (<5% loss) and fair coordination in a variety of synthetic scenarios and a real-world meeting scheduling problem. The lightweight nature and fast learning constitute ALMA-Learning ideal for on-device deployment.
Improved Cooperation by Exploiting a Common Signal
Feb 03, 2021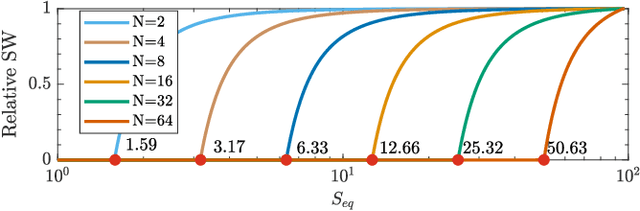

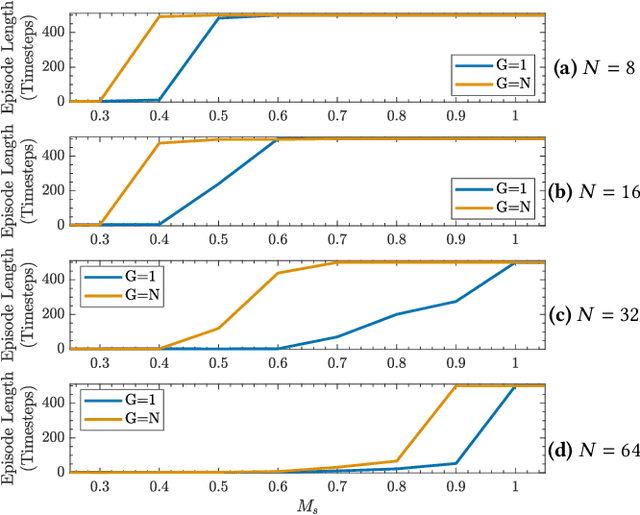
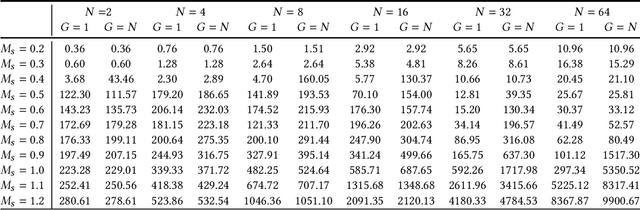
Can artificial agents benefit from human conventions? Human societies manage to successfully self-organize and resolve the tragedy of the commons in common-pool resources, in spite of the bleak prediction of non-cooperative game theory. On top of that, real-world problems are inherently large-scale and of low observability. One key concept that facilitates human coordination in such settings is the use of conventions. Inspired by human behavior, we investigate the learning dynamics and emergence of temporal conventions, focusing on common-pool resources. Extra emphasis was given in designing a realistic evaluation setting: (a) environment dynamics are modeled on real-world fisheries, (b) we assume decentralized learning, where agents can observe only their own history, and (c) we run large-scale simulations (up to 64 agents). Uncoupled policies and low observability make cooperation hard to achieve; as the number of agents grow, the probability of taking a correct gradient direction decreases exponentially. By introducing an arbitrary common signal (e.g., date, time, or any periodic set of numbers) as a means to couple the learning process, we show that temporal conventions can emerge and agents reach sustainable harvesting strategies. The introduction of the signal consistently improves the social welfare (by 258% on average, up to 3306%), the range of environmental parameters where sustainability can be achieved (by 46% on average, up to 300%), and the convergence speed in low abundance settings (by 13% on average, up to 53%).
Differential Privacy Meets Maximum-weight Matching
Nov 16, 2020
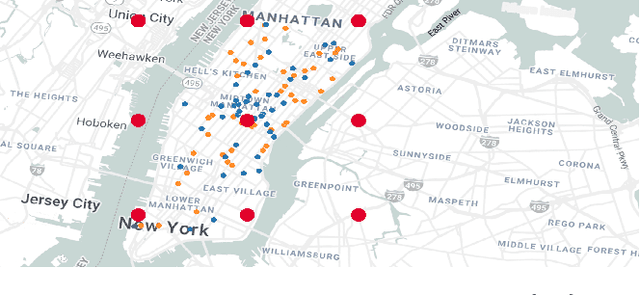
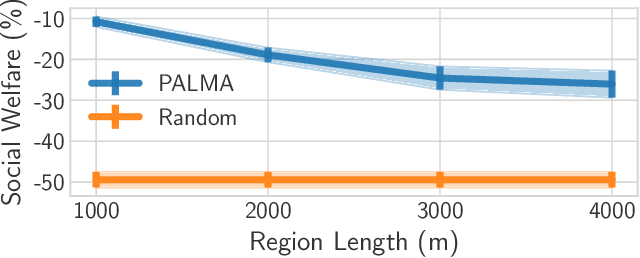
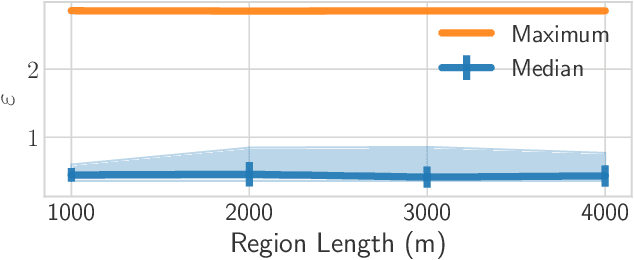
When it comes to large-scale multi-agent systems with a diverse set of agents, traditional differential privacy (DP) mechanisms are ill-matched because they consider a very broad class of adversaries, and they protect all users, independent of their characteristics, by the same guarantee. Achieving a meaningful privacy leads to pronounced reduction in solution quality. Such assumptions are unnecessary in many real-world applications for three key reasons: (i) users might be willing to disclose less sensitive information (e.g., city of residence, but not exact location), (ii) the attacker might posses auxiliary information (e.g., city of residence in a mobility-on-demand system, or reviewer expertise in a paper assignment problem), and (iii) domain characteristics might exclude a subset of solutions (an expert on auctions would not be assigned to review a robotics paper, thus there is no need for indistinguishably between reviewers on different fields). We introduce Piecewise Local Differential Privacy (PLDP), a privacy model designed to protect the utility function in applications where the attacker possesses additional information on the characteristics of the utility space. PLDP enables a high degree of privacy, while being applicable to real-world, unboundedly large settings. Moreover, we propose PALMA, a privacy-preserving heuristic for maximum-weight matching. We evaluate PALMA in a vehicle-passenger matching scenario using real data and demonstrate that it provides strong privacy, $\varepsilon \leq 3$ and a median of $\varepsilon = 0.44$, and high quality matchings ($10.8\%$ worse than the non-private optimal).
Putting Ridesharing to the Test: Efficient and Scalable Solutions and the Power of Dynamic Vehicle Relocation
Feb 12, 2020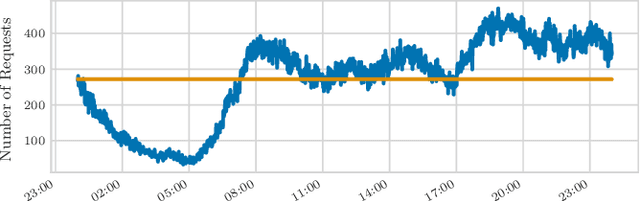
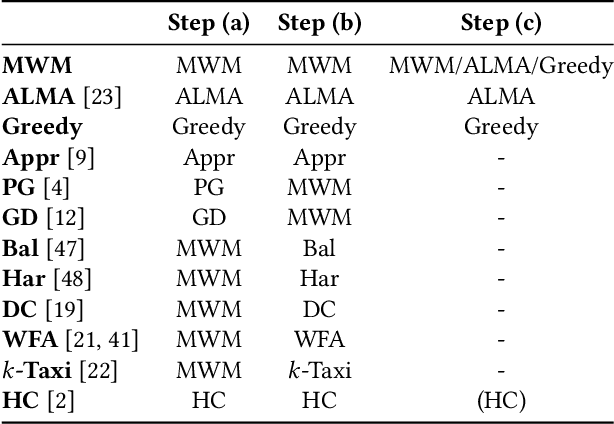
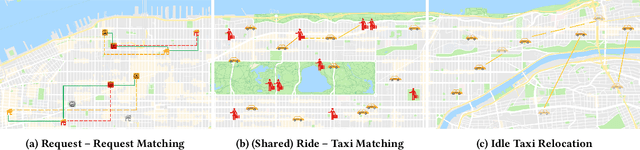
We perform a systematic evaluation of a diverse set of algorithms for the ridesharing problem which is, to the best of our knowledge, one of the largest and most comprehensive to date. In particular, we evaluate 12 different algorithms over 12 metrics related to global efficiency, complexity, passenger, driver, and platform incentives. Our evaluation setting is specifically designed to resemble reality as closely as possible. We achieve this by (a) using actual data from the NYC's yellow taxi trip records, both for modeling customer requests, and taxis (b) following closely the pricing model employed by ridesharing platforms and (c) running our simulations to the scale of the actual problem faced by the ridesharing platforms. Our results provide a clear-cut recommendation to ridesharing platforms on which solutions can be employed in practice and demonstrate the large potential for efficiency gains. Moreover, we show that simple, lightweight relocation schemes -- which can be used as independent components to any ridesharing algorithm -- can significantly improve Quality of Service metrics by up to 50%. As a highlight of our findings, we identify a scalable, on-device heuristic that offers an efficient, end-to-end solution for the Dynamic Ridesharing and Fleet Relocation problem.
Anytime Heuristic for Weighted Matching Through Altruism-Inspired Behavior
Feb 25, 2019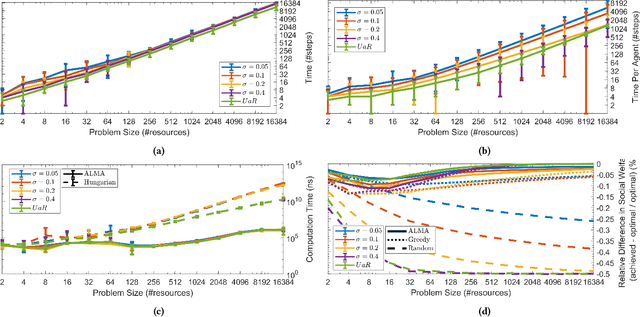

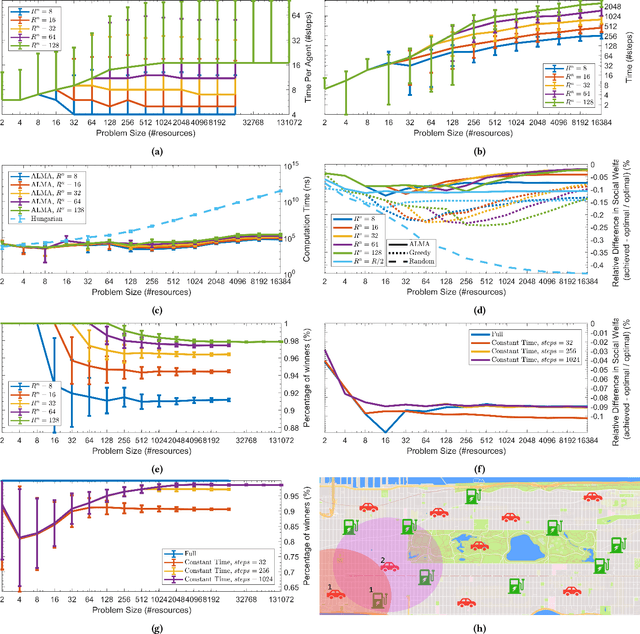
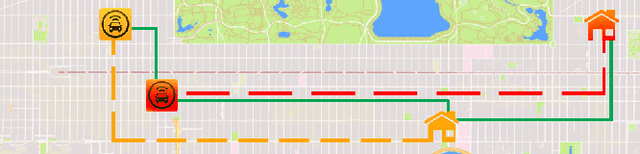
We present a novel anytime heuristic (ALMA), inspired by the human principle of altruism, for solving the assignment problem. ALMA is decentralized, completely uncoupled, and requires no communication between the participants. We prove an upper bound on the convergence speed that is polynomial in the desired number of resources and competing agents per resource; crucially, in the realistic case where the aforementioned quantities are bounded independently of the total number of agents/resources, the convergence time remains constant as the total problem size increases. We have evaluated ALMA under three test cases: (i) an anti-coordination scenario where agents with similar preferences compete over the same set of actions, (ii) a resource allocation scenario in an urban environment, under a constant-time constraint, and finally, (iii) an on-line matching scenario using real passenger-taxi data. In all of the cases, ALMA was able to reach high social welfare, while being orders of magnitude faster than the centralized, optimal algorithm. The latter allows our algorithm to scale to realistic scenarios with hundreds of thousands of agents, e.g., vehicle coordination in urban environments.