 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction
Mar 07, 2023



Large language models (LLMs) show great potential for synthetic data generation. This work shows that useful data can be synthetically generated even for tasks that cannot be solved directly by the LLM: we show that, for problems with structured outputs, it is possible to prompt an LLM to perform the task in the opposite direction, to generate plausible text for the target structure. Leveraging the asymmetry in task difficulty makes it possible to produce large-scale, high-quality data for complex tasks. We demonstrate the effectiveness of this approach on closed information extraction, where collecting ground-truth data is challenging, and no satisfactory dataset exists to date. We synthetically generate a dataset of 1.8M data points, demonstrate its superior quality compared to existing datasets in a human evaluation and use it to finetune small models (220M and 770M parameters). The models we introduce, SynthIE, outperform existing baselines of comparable size with a substantial gap of 57 and 79 absolute points in micro and macro F1, respectively. Code, data, and models are available at https://github.com/epfl-dlab/SynthIE.
Descartes: Generating Short Descriptions of Wikipedia Articles
May 20, 2022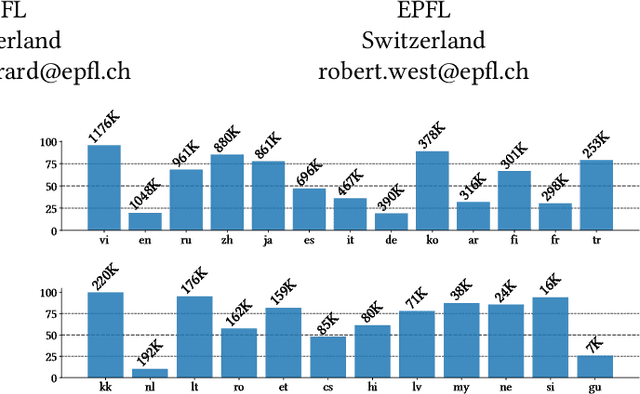
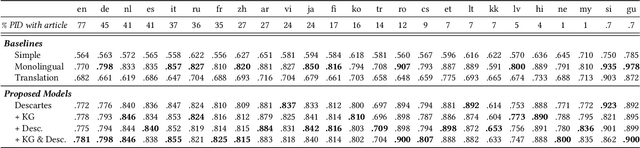
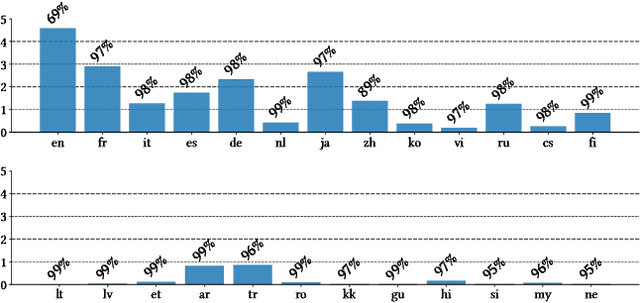
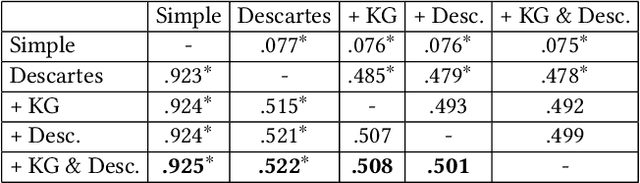
We introduce and tackle the problem of automatically generating short descriptions of Wikipedia articles (e.g., Belgium has a short description Country in Western Europe). We introduce Descartes, a model that can generate descriptions performing on par with human editors. Our human evaluation results indicate that Descartes is preferred over editor-written descriptions about 50% of time. Further manual analysis show that Descartes generates descriptions considered as "valid" for 91.3% of articles, this is the as same editor-written descriptions. Such performances are made possible by integrating other signals naturally existing in Wikipedia: (i) articles about the same entity in different languages, (ii) existing short descriptions in other languages, and (iii) structural information from Wikidata. Our work has direct practical applications in helping Wikipedia editors to provide short descriptions for the more than 9 million articles still missing one. Finally, our proposed architecture can easily be re-purposed to address other information gaps in Wikipedia.
Putting Ridesharing to the Test: Efficient and Scalable Solutions and the Power of Dynamic Vehicle Relocation
Feb 12, 2020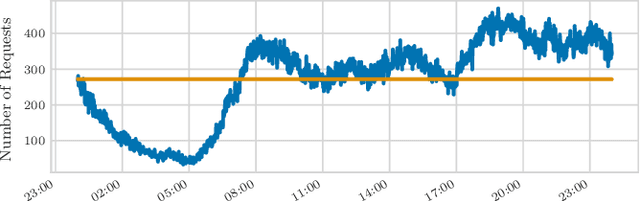
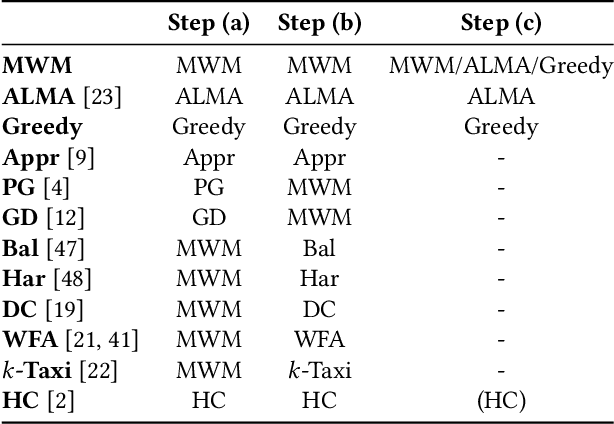
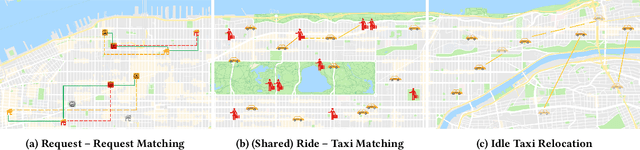
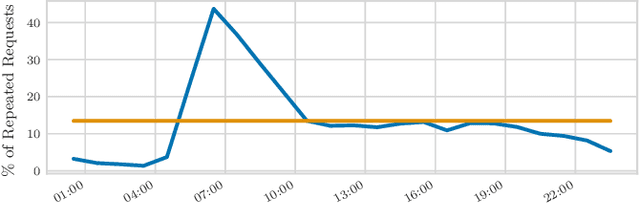
We perform a systematic evaluation of a diverse set of algorithms for the ridesharing problem which is, to the best of our knowledge, one of the largest and most comprehensive to date. In particular, we evaluate 12 different algorithms over 12 metrics related to global efficiency, complexity, passenger, driver, and platform incentives. Our evaluation setting is specifically designed to resemble reality as closely as possible. We achieve this by (a) using actual data from the NYC's yellow taxi trip records, both for modeling customer requests, and taxis (b) following closely the pricing model employed by ridesharing platforms and (c) running our simulations to the scale of the actual problem faced by the ridesharing platforms. Our results provide a clear-cut recommendation to ridesharing platforms on which solutions can be employed in practice and demonstrate the large potential for efficiency gains. Moreover, we show that simple, lightweight relocation schemes -- which can be used as independent components to any ridesharing algorithm -- can significantly improve Quality of Service metrics by up to 50%. As a highlight of our findings, we identify a scalable, on-device heuristic that offers an efficient, end-to-end solution for the Dynamic Ridesharing and Fleet Relocation problem.