 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters to an LLM? Behavioral and Computational Evidences from Summarization
Jan 31, 2026Large Language Models (LLMs) are now state-of-the-art at summarization, yet the internal notion of importance that drives their information selections remains hidden. We propose to investigate this by combining behavioral and computational analyses. Behaviorally, we generate a series of length-controlled summaries for each document and derive empirical importance distributions based on how often each information unit is selected. These reveal that LLMs converge on consistent importance patterns, sharply different from pre-LLM baselines, and that LLMs cluster more by family than by size. Computationally, we identify that certain attention heads align well with empirical importance distributions, and that middle-to-late layers are strongly predictive of importance. Together, these results provide initial insights into what LLMs prioritize in summarization and how this priority is internally represented, opening a path toward interpreting and ultimately controlling information selection in these models.
Pantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
The Dead Salmons of AI Interpretability
Dec 21, 2025In a striking neuroscience study, the authors placed a dead salmon in an MRI scanner and showed it images of humans in social situations. Astonishingly, standard analyses of the time reported brain regions predictive of social emotions. The explanation, of course, was not supernatural cognition but a cautionary tale about misapplied statistical inference. In AI interpretability, reports of similar ''dead salmon'' artifacts abound: feature attribution, probing, sparse auto-encoding, and even causal analyses can produce plausible-looking explanations for randomly initialized neural networks. In this work, we examine this phenomenon and argue for a pragmatic statistical-causal reframing: explanations of computational systems should be treated as parameters of a (statistical) model, inferred from computational traces. This perspective goes beyond simply measuring statistical variability of explanations due to finite sampling of input data; interpretability methods become statistical estimators, and findings should be tested against explicit and meaningful alternative computational hypotheses, with uncertainty quantified with respect to the postulated statistical model. It also highlights important theoretical issues, such as the identifiability of common interpretability queries, which we argue is critical to understand the field's susceptibility to false discoveries, poor generalizability, and high variance. More broadly, situating interpretability within the standard toolkit of statistical inference opens promising avenues for future work aimed at turning AI interpretability into a pragmatic and rigorous science.
Mechanistic Interpretability as Statistical Estimation: A Variance Analysis of EAP-IG
Oct 02, 2025The development of trustworthy artificial intelligence requires moving beyond black-box performance metrics toward an understanding of models' internal computations. Mechanistic Interpretability (MI) aims to meet this need by identifying the algorithmic mechanisms underlying model behaviors. Yet, the scientific rigor of MI critically depends on the reliability of its findings. In this work, we argue that interpretability methods, such as circuit discovery, should be viewed as statistical estimators, subject to questions of variance and robustness. To illustrate this statistical framing, we present a systematic stability analysis of a state-of-the-art circuit discovery method: EAP-IG. We evaluate its variance and robustness through a comprehensive suite of controlled perturbations, including input resampling, prompt paraphrasing, hyperparameter variation, and injected noise within the causal analysis itself. Across a diverse set of models and tasks, our results demonstrate that EAP-IG exhibits high structural variance and sensitivity to hyperparameters, questioning the stability of its findings. Based on these results, we offer a set of best-practice recommendations for the field, advocating for the routine reporting of stability metrics to promote a more rigorous and statistically grounded science of interpretability.
Interactive Evaluation of Large Language Models for Multi-Requirement Software Engineering Tasks
Aug 26, 2025Standard single-turn, static benchmarks fall short in evaluating the nuanced capabilities of Large Language Models (LLMs) on complex tasks such as software engineering. In this work, we propose a novel interactive evaluation framework that assesses LLMs on multi-requirement programming tasks through structured, feedback-driven dialogue. Each task is modeled as a requirement dependency graph, and an ``interviewer'' LLM, aware of the ground-truth solution, provides minimal, targeted hints to an ``interviewee'' model to help correct errors and fulfill target constraints. This dynamic protocol enables fine-grained diagnostic insights into model behavior, uncovering strengths and systematic weaknesses that static benchmarks fail to measure. We build on DevAI, a benchmark of 55 curated programming tasks, by adding ground-truth solutions and evaluating the relevance and utility of interviewer hints through expert annotation. Our results highlight the importance of dynamic evaluation in advancing the development of collaborative code-generating agents.
Date Fragments: A Hidden Bottleneck of Tokenization for Temporal Reasoning
May 22, 2025


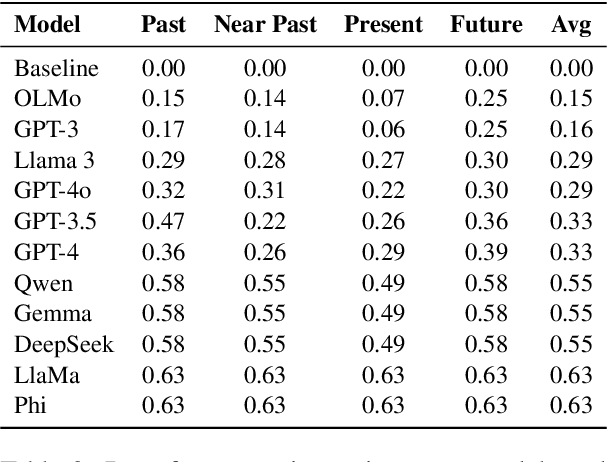
Modern BPE tokenizers often split calendar dates into meaningless fragments, e.g., 20250312 $\rightarrow$ 202, 503, 12, inflating token counts and obscuring the inherent structure needed for robust temporal reasoning. In this work, we (1) introduce a simple yet interpretable metric, termed date fragmentation ratio, that measures how faithfully a tokenizer preserves multi-digit date components; (2) release DateAugBench, a suite of 6500 examples spanning three temporal reasoning tasks: context-based date resolution, format-invariance puzzles, and date arithmetic across historical, contemporary, and future regimes; and (3) through layer-wise probing and causal attention-hop analyses, uncover an emergent date-abstraction mechanism whereby large language models stitch together the fragments of month, day, and year components for temporal reasoning. Our experiments show that excessive fragmentation correlates with accuracy drops of up to 10 points on uncommon dates like historical and futuristic dates. Further, we find that the larger the model, the faster the emergent date abstraction that heals date fragments is accomplished. Lastly, we observe a reasoning path that LLMs follow to assemble date fragments, typically differing from human interpretation (year $\rightarrow$ month $\rightarrow$ day).
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
Everything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable?
Feb 28, 2025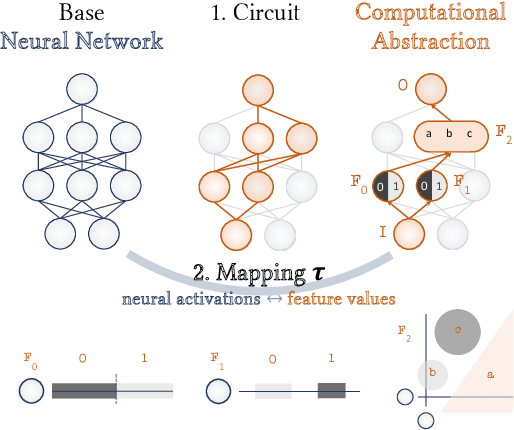
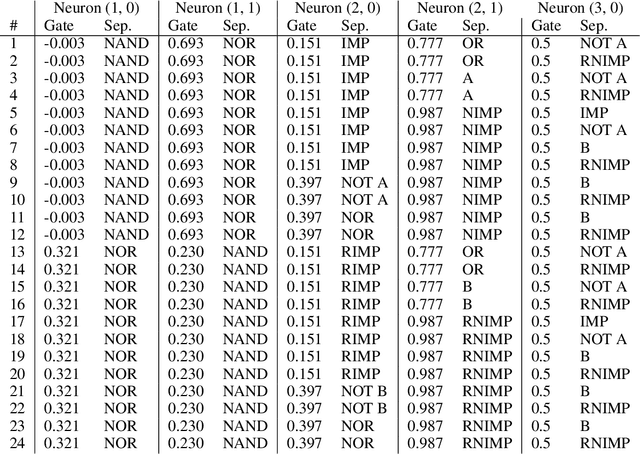
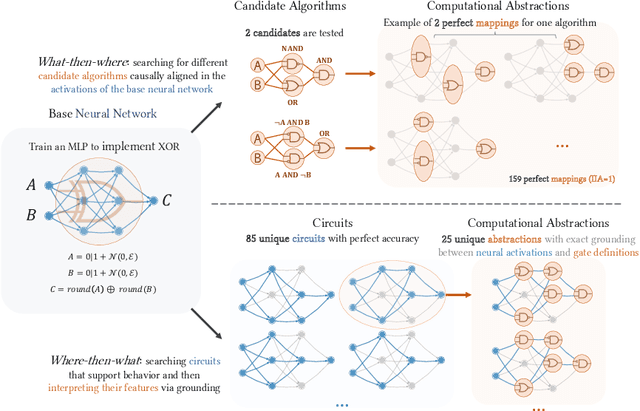

As AI systems are used in high-stakes applications, ensuring interpretability is crucial. Mechanistic Interpretability (MI) aims to reverse-engineer neural networks by extracting human-understandable algorithms to explain their behavior. This work examines a key question: for a given behavior, and under MI's criteria, does a unique explanation exist? Drawing on identifiability in statistics, where parameters are uniquely inferred under specific assumptions, we explore the identifiability of MI explanations. We identify two main MI strategies: (1) "where-then-what," which isolates a circuit replicating model behavior before interpreting it, and (2) "what-then-where," which starts with candidate algorithms and searches for neural activation subspaces implementing them, using causal alignment. We test both strategies on Boolean functions and small multi-layer perceptrons, fully enumerating candidate explanations. Our experiments reveal systematic non-identifiability: multiple circuits can replicate behavior, a circuit can have multiple interpretations, several algorithms can align with the network, and one algorithm can align with different subspaces. Is uniqueness necessary? A pragmatic approach may require only predictive and manipulability standards. If uniqueness is essential for understanding, stricter criteria may be needed. We also reference the inner interpretability framework, which validates explanations through multiple criteria. This work contributes to defining explanation standards in AI.
Meta-Statistical Learning: Supervised Learning of Statistical Inference
Feb 19, 2025



This work demonstrates that the tools and principles driving the success of large language models (LLMs) can be repurposed to tackle distribution-level tasks, where the goal is to predict properties of the data-generating distribution rather than labels for individual datapoints. These tasks encompass statistical inference problems such as parameter estimation, hypothesis testing, or mutual information estimation. Framing these tasks within traditional machine learning pipelines is challenging, as supervision is typically tied to individual datapoint. We propose meta-statistical learning, a framework inspired by multi-instance learning that reformulates statistical inference tasks as supervised learning problems. In this approach, entire datasets are treated as single inputs to neural networks, which predict distribution-level parameters. Transformer-based architectures, without positional encoding, provide a natural fit due to their permutation-invariance properties. By training on large-scale synthetic datasets, meta-statistical models can leverage the scalability and optimization infrastructure of Transformer-based LLMs. We demonstrate the framework's versatility with applications in hypothesis testing and mutual information estimation, showing strong performance, particularly for small datasets where traditional neural methods struggle.
The Era of Semantic Decoding
Mar 21, 2024


Recent work demonstrated great promise in the idea of orchestrating collaborations between LLMs, human input, and various tools to address the inherent limitations of LLMs. We propose a novel perspective called semantic decoding, which frames these collaborative processes as optimization procedures in semantic space. Specifically, we conceptualize LLMs as semantic processors that manipulate meaningful pieces of information that we call semantic tokens (known thoughts). LLMs are among a large pool of other semantic processors, including humans and tools, such as search engines or code executors. Collectively, semantic processors engage in dynamic exchanges of semantic tokens to progressively construct high-utility outputs. We refer to these orchestrated interactions among semantic processors, optimizing and searching in semantic space, as semantic decoding algorithms. This concept draws a direct parallel to the well-studied problem of syntactic decoding, which involves crafting algorithms to best exploit auto-regressive language models for extracting high-utility sequences of syntactic tokens. By focusing on the semantic level and disregarding syntactic details, we gain a fresh perspective on the engineering of AI systems, enabling us to imagine systems with much greater complexity and capabilities. In this position paper, we formalize the transition from syntactic to semantic tokens as well as the analogy between syntactic and semantic decoding. Subsequently, we explore the possibilities of optimizing within the space of semantic tokens via semantic decoding algorithms. We conclude with a list of research opportunities and questions arising from this fresh perspective. The semantic decoding perspective offers a powerful abstraction for search and optimization directly in the space of meaningful concepts, with semantic tokens as the fundamental units of a new type of computation.