 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Anisotropy in Language Transformers: The Geometry of Learning Dynamics
Apr 09, 2026Since their introduction, Transformer architectures have dominated Natural Language Processing (NLP). However, recent research has highlighted an inherent anisotropy phenomenon in these models, presenting a significant challenge to their geometric interpretation. Previous theoretical studies on this phenomenon are rarely grounded in the underlying representation geometry. In this paper, we extend them by deriving geometric arguments for how frequency-biased sampling attenuates curvature visibility and why training preferentially amplify tangent directions. Empirically, we then use concept-based mechanistic interpretability during training, rather than only post hoc, to fit activation-derived low-rank tangent proxies and test them against ordinary backpropagated true gradients. Across encoder-style and decoder-style language models, we find that these activation-derived directions capture both unusually large gradient energy and a substantially larger share of gradient anisotropy than matched-rank normal controls, providing strong empirical support for a tangent-aligned account of anisotropy.
Interpreto: An Explainability Library for Transformers
Dec 10, 2025Interpreto is a Python library for post-hoc explainability of text HuggingFace models, from early BERT variants to LLMs. It provides two complementary families of methods: attributions and concept-based explanations. The library connects recent research to practical tooling for data scientists, aiming to make explanations accessible to end users. It includes documentation, examples, and tutorials. Interpreto supports both classification and generation models through a unified API. A key differentiator is its concept-based functionality, which goes beyond feature-level attributions and is uncommon in existing libraries. The library is open source; install via pip install interpreto. Code and documentation are available at https://github.com/FOR-sight-ai/interpreto.
FairTranslate: An English-French Dataset for Gender Bias Evaluation in Machine Translation by Overcoming Gender Binarity
Apr 22, 2025Large Language Models (LLMs) are increasingly leveraged for translation tasks but often fall short when translating inclusive language -- such as texts containing the singular 'they' pronoun or otherwise reflecting fair linguistic protocols. Because these challenges span both computational and societal domains, it is imperative to critically evaluate how well LLMs handle inclusive translation with a well-founded framework. This paper presents FairTranslate, a novel, fully human-annotated dataset designed to evaluate non-binary gender biases in machine translation systems from English to French. FairTranslate includes 2418 English-French sentence pairs related to occupations, annotated with rich metadata such as the stereotypical alignment of the occupation, grammatical gender indicator ambiguity, and the ground-truth gender label (male, female, or inclusive). We evaluate four leading LLMs (Gemma2-2B, Mistral-7B, Llama3.1-8B, Llama3.3-70B) on this dataset under different prompting procedures. Our results reveal substantial biases in gender representation across LLMs, highlighting persistent challenges in achieving equitable outcomes in machine translation. These findings underscore the need for focused strategies and interventions aimed at ensuring fair and inclusive language usage in LLM-based translation systems. We make the FairTranslate dataset publicly available on Hugging Face, and disclose the code for all experiments on GitHub.
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
ConSim: Measuring Concept-Based Explanations' Effectiveness with Automated Simulatability
Jan 13, 2025



Concept-based explanations work by mapping complex model computations to human-understandable concepts. Evaluating such explanations is very difficult, as it includes not only the quality of the induced space of possible concepts but also how effectively the chosen concepts are communicated to users. Existing evaluation metrics often focus solely on the former, neglecting the latter. We introduce an evaluation framework for measuring concept explanations via automated simulatability: a simulator's ability to predict the explained model's outputs based on the provided explanations. This approach accounts for both the concept space and its interpretation in an end-to-end evaluation. Human studies for simulatability are notoriously difficult to enact, particularly at the scale of a wide, comprehensive empirical evaluation (which is the subject of this work). We propose using large language models (LLMs) as simulators to approximate the evaluation and report various analyses to make such approximations reliable. Our method allows for scalable and consistent evaluation across various models and datasets. We report a comprehensive empirical evaluation using this framework and show that LLMs provide consistent rankings of explanation methods. Code available at https://github.com/AnonymousConSim/ConSim.
Advancing Fairness in Natural Language Processing: From Traditional Methods to Explainability
Oct 16, 2024

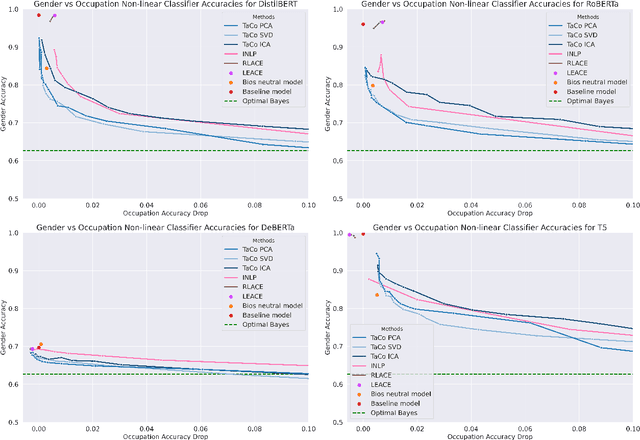
The burgeoning field of Natural Language Processing (NLP) stands at a critical juncture where the integration of fairness within its frameworks has become an imperative. This PhD thesis addresses the need for equity and transparency in NLP systems, recognizing that fairness in NLP is not merely a technical challenge but a moral and ethical necessity, requiring a rigorous examination of how these technologies interact with and impact diverse human populations. Through this lens, this thesis undertakes a thorough investigation into the development of equitable NLP methodologies and the evaluation of biases that prevail in current systems. First, it introduces an innovative algorithm to mitigate biases in multi-class classifiers, tailored for high-risk NLP applications, surpassing traditional methods in both bias mitigation and prediction accuracy. Then, an analysis of the Bios dataset reveals the impact of dataset size on discriminatory biases and the limitations of standard fairness metrics. This awareness has led to explorations in the field of explainable AI, aiming for a more complete understanding of biases where traditional metrics are limited. Consequently, the thesis presents COCKATIEL, a model-agnostic explainability method that identifies and ranks concepts in Transformer models, outperforming previous approaches in sentiment analysis tasks. Finally, the thesis contributes to bridging the gap between fairness and explainability by introducing TaCo, a novel method to neutralize bias in Transformer model embeddings. In conclusion, this thesis constitutes a significant interdisciplinary endeavor that intertwines explicability and fairness to challenge and reshape current NLP paradigms. The methodologies and critiques presented contribute to the ongoing discourse on fairness in machine learning, offering actionable solutions for more equitable and responsible AI systems.
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Dec 11, 2023
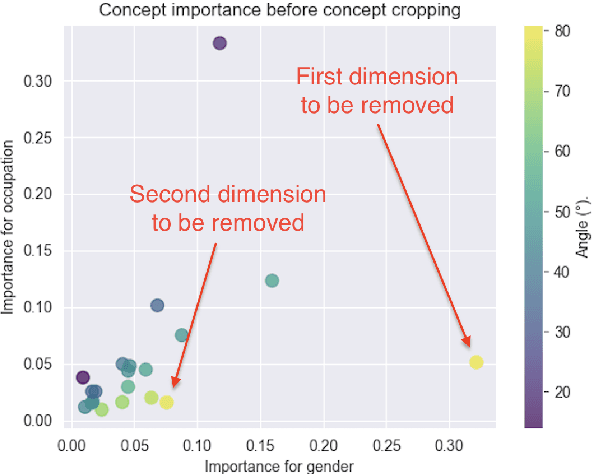
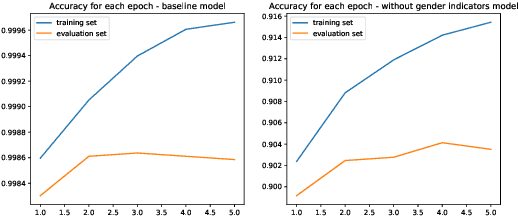
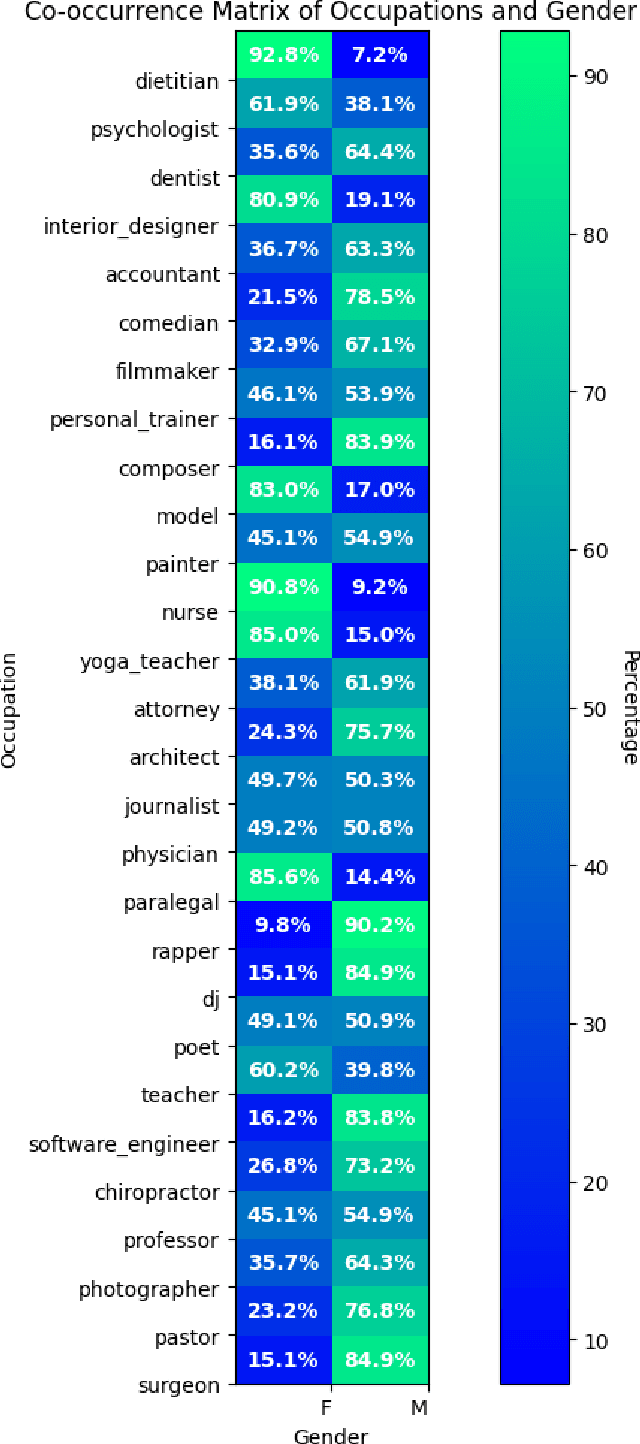
The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo
Are fairness metric scores enough to assess discrimination biases in machine learning?
Jun 08, 2023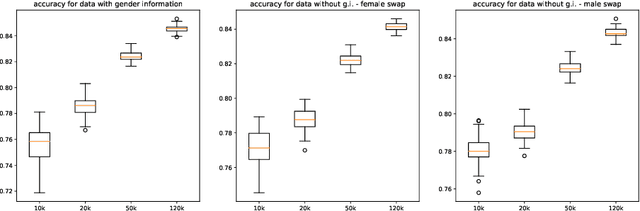
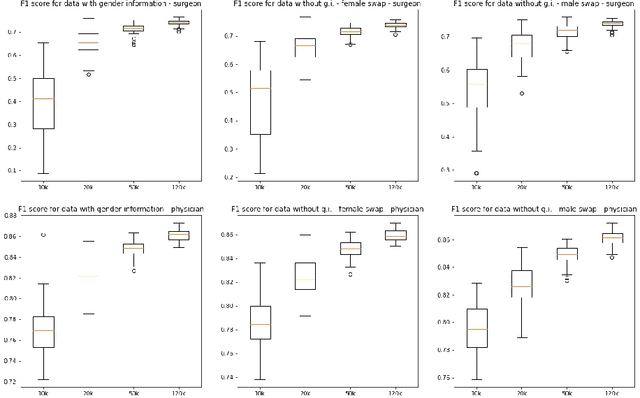
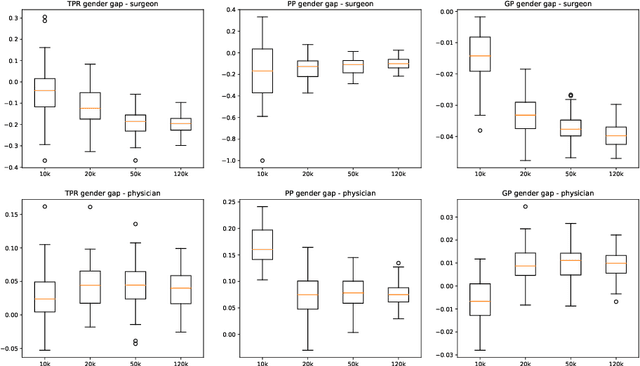
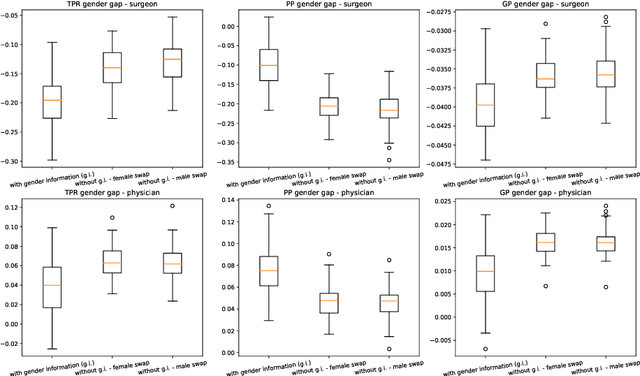
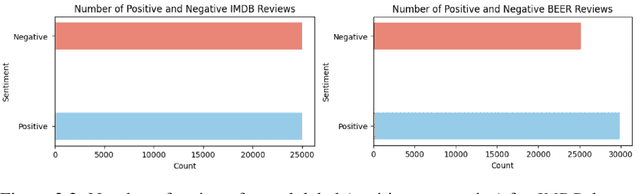
This paper presents novel experiments shedding light on the shortcomings of current metrics for assessing biases of gender discrimination made by machine learning algorithms on textual data. We focus on the Bios dataset, and our learning task is to predict the occupation of individuals, based on their biography. Such prediction tasks are common in commercial Natural Language Processing (NLP) applications such as automatic job recommendations. We address an important limitation of theoretical discussions dealing with group-wise fairness metrics: they focus on large datasets, although the norm in many industrial NLP applications is to use small to reasonably large linguistic datasets for which the main practical constraint is to get a good prediction accuracy. We then question how reliable are different popular measures of bias when the size of the training set is simply sufficient to learn reasonably accurate predictions. Our experiments sample the Bios dataset and learn more than 200 models on different sample sizes. This allows us to statistically study our results and to confirm that common gender bias indices provide diverging and sometimes unreliable results when applied to relatively small training and test samples. This highlights the crucial importance of variance calculations for providing sound results in this field.
COCKATIEL: COntinuous Concept ranKed ATtribution with Interpretable ELements for explaining neural net classifiers on NLP tasks
May 14, 2023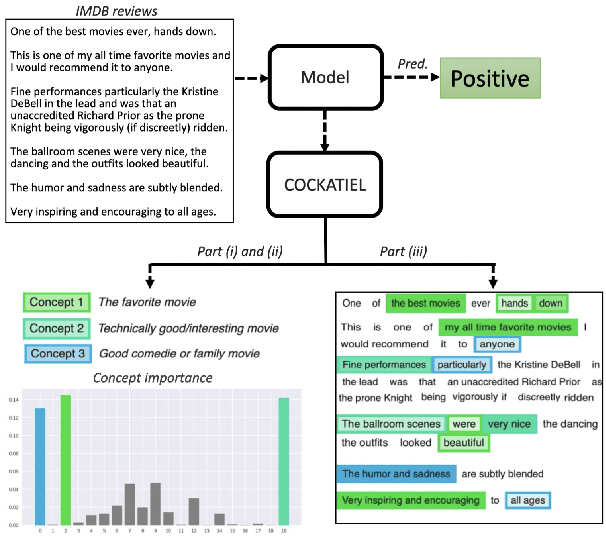
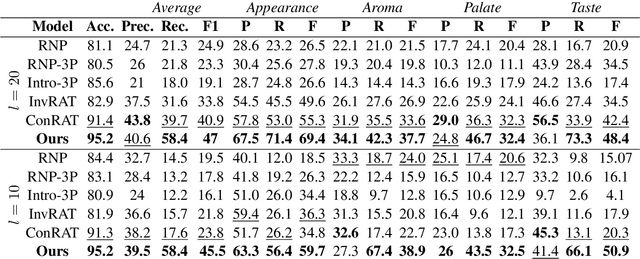
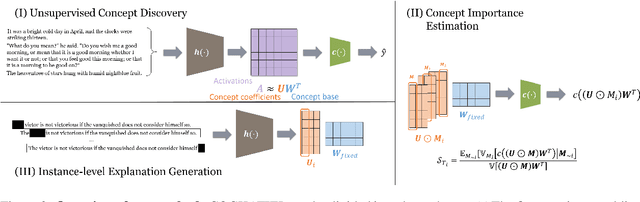
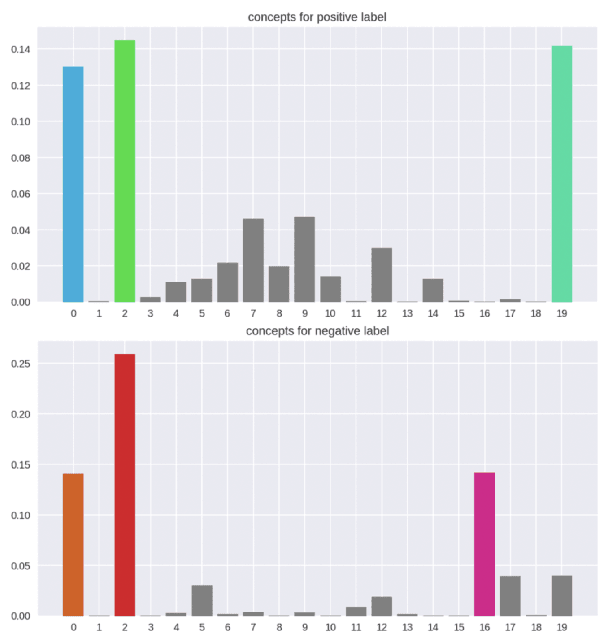
Transformer architectures are complex and their use in NLP, while it has engendered many successes, makes their interpretability or explainability challenging. Recent debates have shown that attention maps and attribution methods are unreliable (Pruthi et al., 2019; Brunner et al., 2019). In this paper, we present some of their limitations and introduce COCKATIEL, which successfully addresses some of them. COCKATIEL is a novel, post-hoc, concept-based, model-agnostic XAI technique that generates meaningful explanations from the last layer of a neural net model trained on an NLP classification task by using Non-Negative Matrix Factorization (NMF) to discover the concepts the model leverages to make predictions and by exploiting a Sensitivity Analysis to estimate accurately the importance of each of these concepts for the model. It does so without compromising the accuracy of the underlying model or requiring a new one to be trained. We conduct experiments in single and multi-aspect sentiment analysis tasks and we show COCKATIEL's superior ability to discover concepts that align with humans' on Transformer models without any supervision, we objectively verify the faithfulness of its explanations through fidelity metrics, and we showcase its ability to provide meaningful explanations in two different datasets.
How optimal transport can tackle gender biases in multi-class neural-network classifiers for job recommendations?
Feb 27, 2023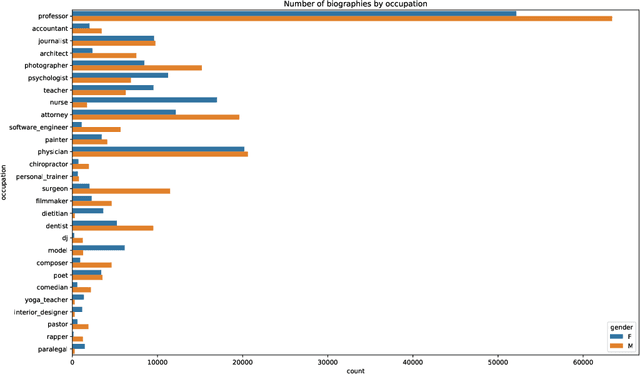
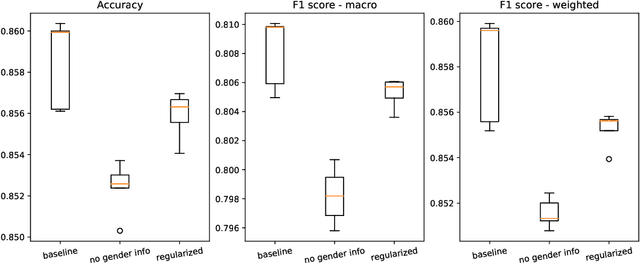
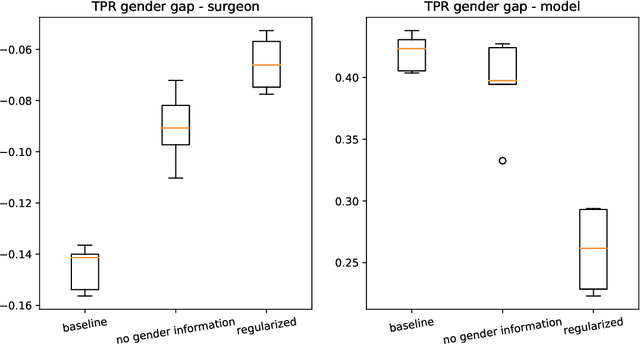
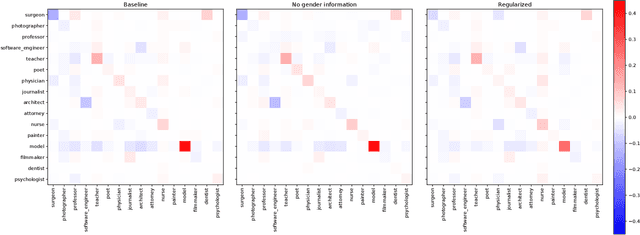
Automatic recommendation systems based on deep neural networks have become extremely popular during the last decade. Some of these systems can however be used for applications which are ranked as High Risk by the European Commission in the A.I. act, as for instance for online job candidate recommendation. When used in the European Union, commercial AI systems for this purpose will then be required to have to proper statistical properties with regard to potential discrimination they could engender. This motivated our contribution, where we present a novel optimal transport strategy to mitigate undesirable algorithmic biases in multi-class neural-network classification. Our stratey is model agnostic and can be used on any multi-class classification neural-network model. To anticipate the certification of recommendation systems using textual data, we then used it on the Bios dataset, for which the learning task consists in predicting the occupation of female and male individuals, based on their LinkedIn biography. Results show that it can reduce undesired algorithmic biases in this context to lower levels than a standard strategy.