 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation
Apr 10, 2026Accurate evaluation is central to the large language model (LLM) ecosystem, guiding model selection and downstream adoption across diverse use cases. In practice, however, evaluating generative outputs typically relies on rigid lexical methods to extract and assess answers, which can conflate a model's true problem-solving ability with its compliance with predefined formatting guidelines. While recent LLM-as-a-Judge approaches mitigate this issue by assessing semantic correctness rather than strict structural conformity, they also introduce substantial computational overhead, making evaluation costly. In this work, we first systematically investigate the limitations of lexical evaluation through a large-scale empirical study spanning 36 models and 15 downstream tasks, demonstrating that such methods correlate poorly with human judgments. To address this limitation, we introduce BERT-as-a-Judge, an encoder-driven approach for assessing answer correctness in reference-based generative settings, robust to variations in output phrasing, and requiring only lightweight training on synthetically annotated question-candidate-reference triplets. We show that it consistently outperforms the lexical baseline while matching the performance of much larger LLM judges, providing a compelling tradeoff between the two and enabling reliable, scalable evaluation. Finally, through extensive experimentation, we provide detailed insights into BERT-as-a-Judge's performance to offer practical guidance for practitioners, and release all project artifacts to foster downstream adoption.
BidirLM: From Text to Omnimodal Bidirectional Encoders by Adapting and Composing Causal LLMs
Apr 02, 2026Transforming causal generative language models into bidirectional encoders offers a powerful alternative to BERT-style architectures. However, current approaches remain limited: they lack consensus on optimal training objectives, suffer from catastrophic forgetting at scale, and fail to flexibly integrate the vast ecosystem of specialized generative models. In this work, through systematic ablations on the Gemma3 and Qwen3 families, we identify the key factors driving successful adaptation, highlighting the critical role of an often-omitted prior masking phase. To scale this process without original pre-training data, we introduce a dual strategy combining linear weight merging with a lightweight multi-domain data mixture that mitigates catastrophic forgetting. Finally, we augment our encoders by merging them with specialized causal models, seamlessly transferring modality- and domain-specific capabilities. This open-source recipe, designed for any causal decoder LLM, yields BidirLM, a family of five encoders that outperform alternatives on text, vision, and audio representation benchmarks.
EuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
When Does Reasoning Matter? A Controlled Study of Reasoning's Contribution to Model Performance
Sep 26, 2025Large Language Models (LLMs) with reasoning capabilities have achieved state-of-the-art performance on a wide range of tasks. Despite its empirical success, the tasks and model scales at which reasoning becomes effective, as well as its training and inference costs, remain underexplored. In this work, we rely on a synthetic data distillation framework to conduct a large-scale supervised study. We compare Instruction Fine-Tuning (IFT) and reasoning models of varying sizes, on a wide range of math-centric and general-purpose tasks, evaluating both multiple-choice and open-ended formats. Our analysis reveals that reasoning consistently improves model performance, often matching or surpassing significantly larger IFT systems. Notably, while IFT remains Pareto-optimal in training and inference costs, reasoning models become increasingly valuable as model size scales, overcoming IFT performance limits on reasoning-intensive and open-ended tasks.
Should We Still Pretrain Encoders with Masked Language Modeling?
Jul 01, 2025Learning high-quality text representations is fundamental to a wide range of NLP tasks. While encoder pretraining has traditionally relied on Masked Language Modeling (MLM), recent evidence suggests that decoder models pretrained with Causal Language Modeling (CLM) can be effectively repurposed as encoders, often surpassing traditional encoders on text representation benchmarks. However, it remains unclear whether these gains reflect an inherent advantage of the CLM objective or arise from confounding factors such as model and data scale. In this paper, we address this question through a series of large-scale, carefully controlled pretraining ablations, training a total of 30 models ranging from 210 million to 1 billion parameters, and conducting over 15,000 fine-tuning and evaluation runs. We find that while training with MLM generally yields better performance across text representation tasks, CLM-trained models are more data-efficient and demonstrate improved fine-tuning stability. Building on these findings, we experimentally show that a biphasic training strategy that sequentially applies CLM and then MLM, achieves optimal performance under a fixed computational training budget. Moreover, we demonstrate that this strategy becomes more appealing when initializing from readily available pretrained CLM models (from the existing LLM ecosystem), reducing the computational burden needed to train best-in-class encoder models. We release all project artifacts at https://hf.co/MLMvsCLM to foster further research.
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs
Feb 20, 2024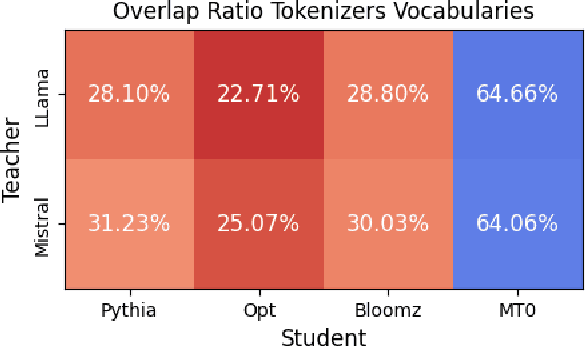

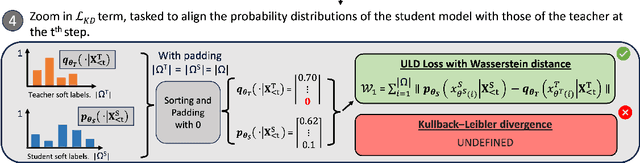
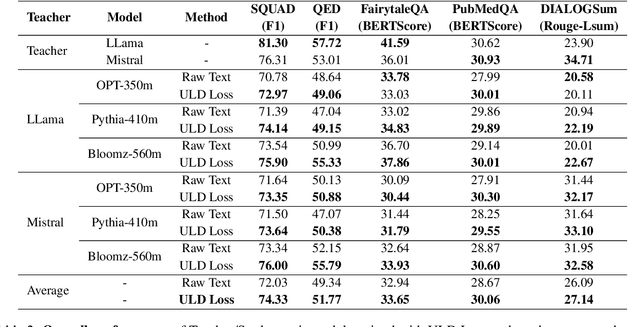
Deploying large language models (LLMs) of several billion parameters can be impractical in most industrial use cases due to constraints such as cost, latency limitations, and hardware accessibility. Knowledge distillation (KD) offers a solution by compressing knowledge from resource-intensive large models to smaller ones. Various strategies exist, some relying on the text generated by the teacher model and optionally utilizing his logits to enhance learning. However, these methods based on logits often require both teacher and student models to share the same tokenizer, limiting their applicability across different LLM families. In this paper, we introduce Universal Logit Distillation (ULD) loss, grounded in optimal transport, to address this limitation. Our experimental results demonstrate the effectiveness of ULD loss in enabling distillation across models with different architectures and tokenizers, paving the way to a more widespread use of distillation techniques.
CroissantLLM: A Truly Bilingual French-English Language Model
Feb 02, 2024



We introduce CroissantLLM, a 1.3B language model pretrained on a set of 3T English and French tokens, to bring to the research and industrial community a high-performance, fully open-sourced bilingual model that runs swiftly on consumer-grade local hardware. To that end, we pioneer the approach of training an intrinsically bilingual model with a 1:1 English-to-French pretraining data ratio, a custom tokenizer, and bilingual finetuning datasets. We release the training dataset, notably containing a French split with manually curated, high-quality, and varied data sources. To assess performance outside of English, we craft a novel benchmark, FrenchBench, consisting of an array of classification and generation tasks, covering various orthogonal aspects of model performance in the French Language. Additionally, rooted in transparency and to foster further Large Language Model research, we release codebases, and dozens of checkpoints across various model sizes, training data distributions, and training steps, as well as fine-tuned Chat models, and strong translation models. We evaluate our model through the FMTI framework, and validate 81 % of the transparency criteria, far beyond the scores of even most open initiatives. This work enriches the NLP landscape, breaking away from previous English-centric work in order to strengthen our understanding of multilinguality in language models.
Deep learning-based stereo camera multi-video synchronization
Mar 22, 2023Stereo vision is essential for many applications. Currently, the synchronization of the streams coming from two cameras is done using mostly hardware. A software-based synchronization method would reduce the cost, weight and size of the entire system and allow for more flexibility when building such systems. With this goal in mind, we present here a comparison of different deep learning-based systems and prove that some are efficient and generalizable enough for such a task. This study paves the way to a production ready software-based video synchronization system.