 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
EuroLLM-9B: Technical Report
Jun 04, 2025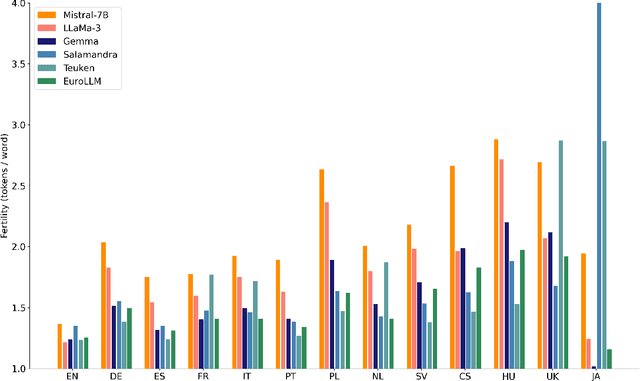
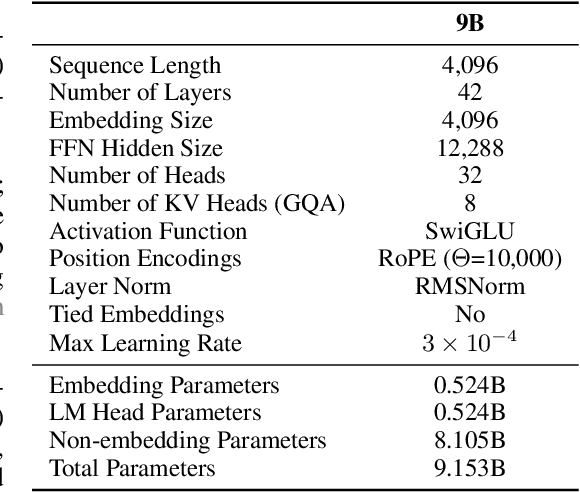
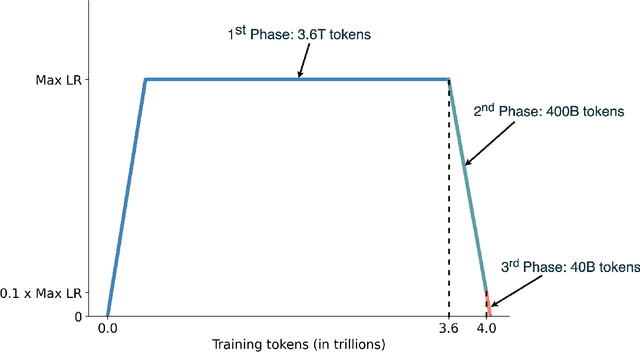
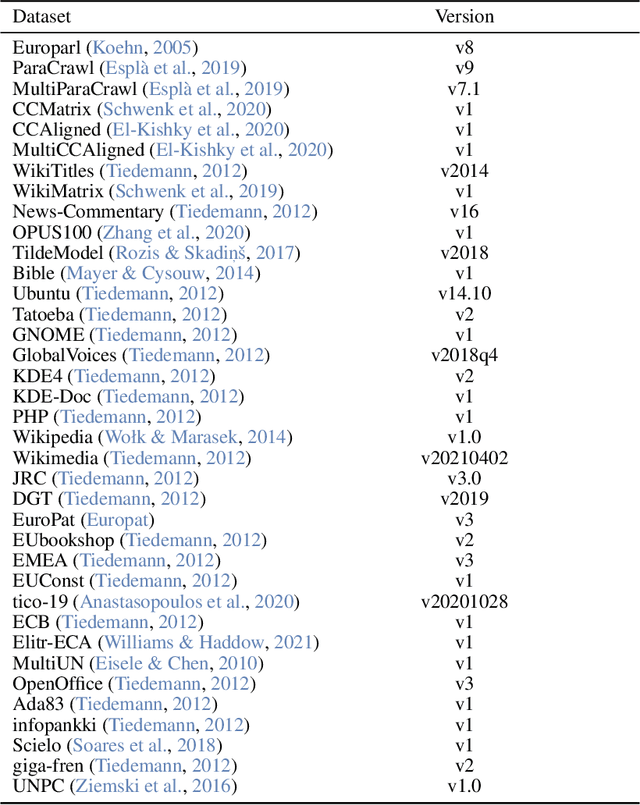
This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
Multilingual Contextualization of Large Language Models for Document-Level Machine Translation
Apr 16, 2025

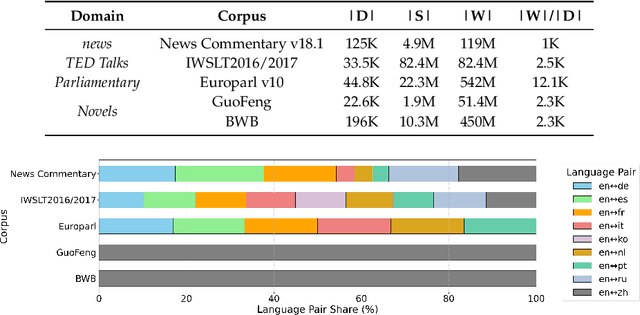
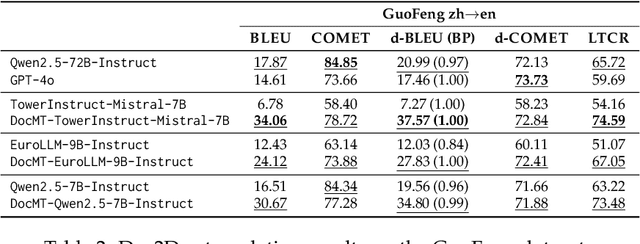
Large language models (LLMs) have demonstrated strong performance in sentence-level machine translation, but scaling to document-level translation remains challenging, particularly in modeling long-range dependencies and discourse phenomena across sentences and paragraphs. In this work, we propose a method to improve LLM-based long-document translation through targeted fine-tuning on high-quality document-level data, which we curate and introduce as DocBlocks. Our approach supports multiple translation paradigms, including direct document-to-document and chunk-level translation, by integrating instructions both with and without surrounding context. This enables models to better capture cross-sentence dependencies while maintaining strong sentence-level translation performance. Experimental results show that incorporating multiple translation paradigms improves document-level translation quality and inference speed compared to prompting and agent-based methods.
Do LLMs Understand Your Translations? Evaluating Paragraph-level MT with Question Answering
Apr 10, 2025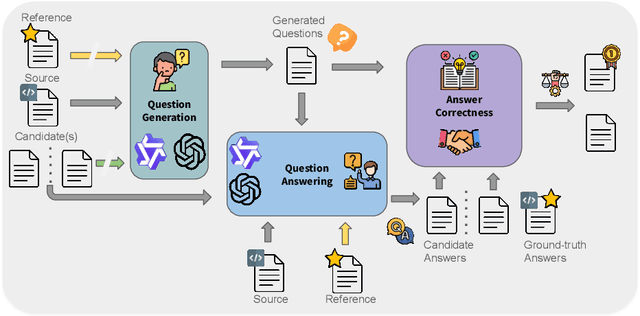
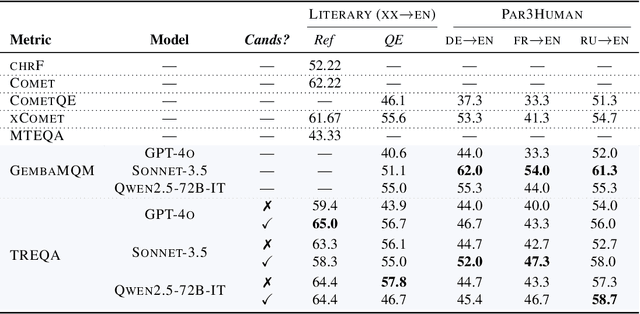

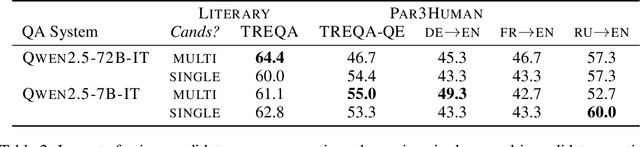
Despite the steady progress in machine translation evaluation, existing automatic metrics struggle to capture how well meaning is preserved beyond sentence boundaries. We posit that reliance on a single intrinsic quality score, trained to mimic human judgments, might be insufficient for evaluating translations of long, complex passages, and a more ``pragmatic'' approach that assesses how accurately key information is conveyed by a translation in context is needed. We introduce TREQA (Translation Evaluation via Question-Answering), a framework that extrinsically evaluates translation quality by assessing how accurately candidate translations answer reading comprehension questions that target key information in the original source or reference texts. In challenging domains that require long-range understanding, such as literary texts, we show that TREQA is competitive with and, in some cases, outperforms state-of-the-art neural and LLM-based metrics in ranking alternative paragraph-level translations, despite never being explicitly optimized to correlate with human judgments. Furthermore, the generated questions and answers offer interpretability: empirical analysis shows that they effectively target translation errors identified by experts in evaluated datasets. Our code is available at https://github.com/deep-spin/treqa
M-Prometheus: A Suite of Open Multilingual LLM Judges
Apr 07, 2025The use of language models for automatically evaluating long-form text (LLM-as-a-judge) is becoming increasingly common, yet most LLM judges are optimized exclusively for English, with strategies for enhancing their multilingual evaluation capabilities remaining largely unexplored in the current literature. This has created a disparity in the quality of automatic evaluation methods for non-English languages, ultimately hindering the development of models with better multilingual capabilities. To bridge this gap, we introduce M-Prometheus, a suite of open-weight LLM judges ranging from 3B to 14B parameters that can provide both direct assessment and pairwise comparison feedback on multilingual outputs. M-Prometheus models outperform state-of-the-art open LLM judges on multilingual reward benchmarks spanning more than 20 languages, as well as on literary machine translation (MT) evaluation covering 4 language pairs. Furthermore, M-Prometheus models can be leveraged at decoding time to significantly improve generated outputs across all 3 tested languages, showcasing their utility for the development of better multilingual models. Lastly, through extensive ablations, we identify the key factors for obtaining an effective multilingual judge, including backbone model selection and training on natively multilingual feedback data instead of translated data. We release our models, training dataset, and code.
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025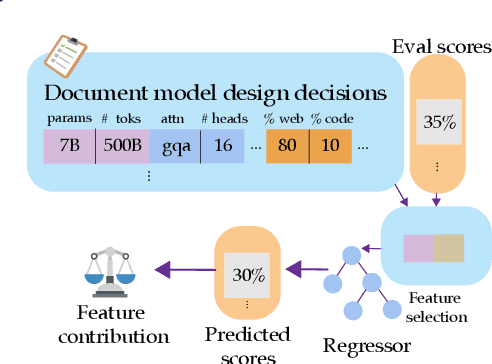
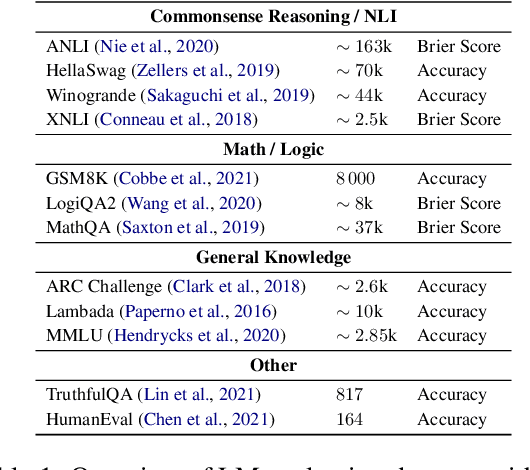
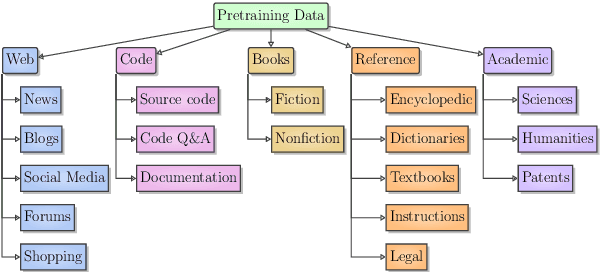
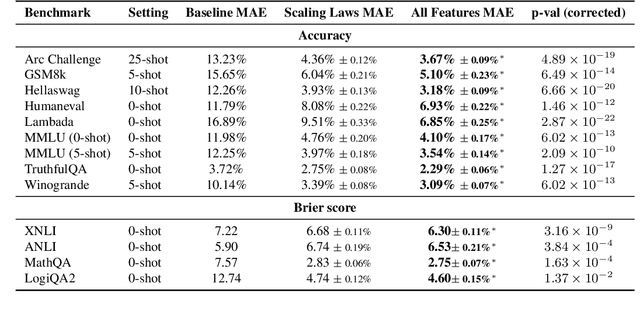
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
A Context-aware Framework for Translation-mediated Conversations
Dec 05, 2024Effective communication is fundamental to any interaction, yet challenges arise when participants do not share a common language. Automatic translation systems offer a powerful solution to bridge language barriers in such scenarios, but they introduce errors that can lead to misunderstandings and conversation breakdown. A key issue is that current systems fail to incorporate the rich contextual information necessary to resolve ambiguities and omitted details, resulting in literal, inappropriate, or misaligned translations. In this work, we present a framework to improve large language model-based translation systems by incorporating contextual information in bilingual conversational settings. During training, we leverage context-augmented parallel data, which allows the model to generate translations sensitive to conversational history. During inference, we perform quality-aware decoding with context-aware metrics to select the optimal translation from a pool of candidates. We validate both components of our framework on two task-oriented domains: customer chat and user-assistant interaction. Across both settings, our framework consistently results in better translations than state-of-the-art systems like GPT-4o and TowerInstruct, as measured by multiple automatic translation quality metrics on several language pairs. We also show that the resulting model leverages context in an intended and interpretable way, improving consistency between the conveyed message and the generated translations.
Fine-Grained Reward Optimization for Machine Translation using Error Severity Mappings
Nov 08, 2024
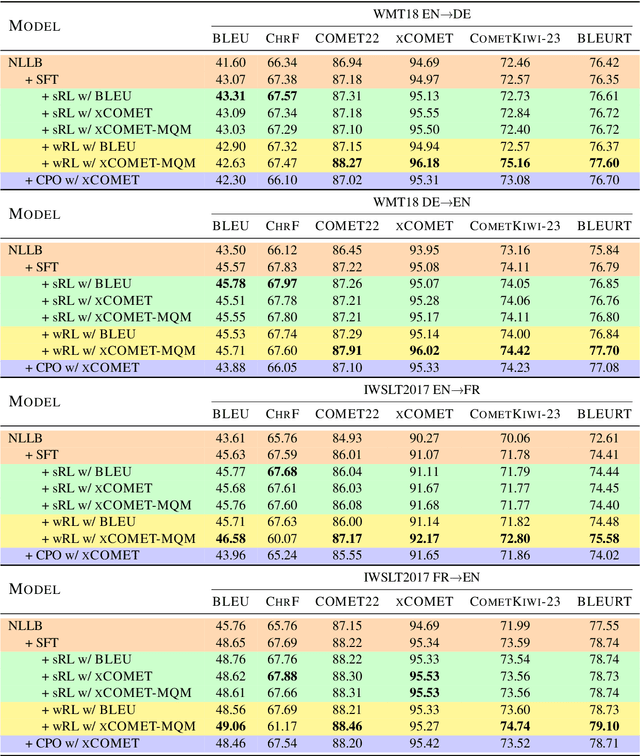
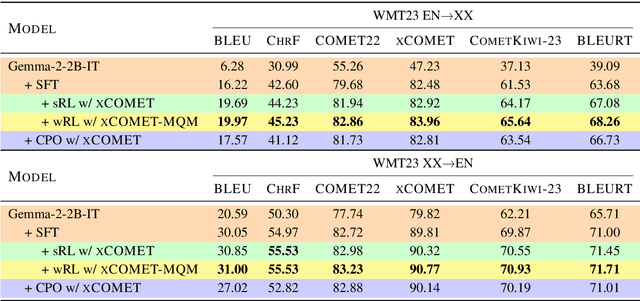
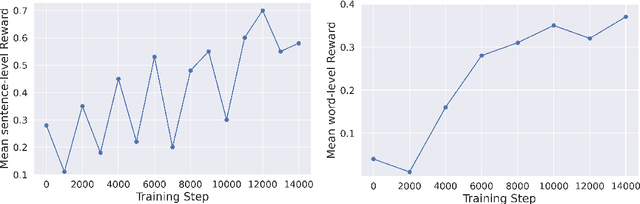
Reinforcement learning (RL) has been proven to be an effective and robust method for training neural machine translation systems, especially when paired with powerful reward models that accurately assess translation quality. However, most research has focused on RL methods that use sentence-level feedback, which leads to inefficient learning signals due to the reward sparsity problem -- the model receives a single score for the entire sentence. To address this, we introduce a novel approach that leverages fine-grained token-level reward mechanisms with RL methods. We use xCOMET, a state-of-the-art quality estimation system as our token-level reward model. xCOMET provides detailed feedback by predicting fine-grained error spans and their severity given source-translation pairs. We conduct experiments on small and large translation datasets to compare the impact of sentence-level versus fine-grained reward signals on translation quality. Our results show that training with token-level rewards improves translation quality across language pairs over baselines according to automatic and human evaluation. Furthermore, token-level reward optimization also improves training stability, evidenced by a steady increase in mean rewards over training epochs.
Modeling User Preferences with Automatic Metrics: Creating a High-Quality Preference Dataset for Machine Translation
Oct 10, 2024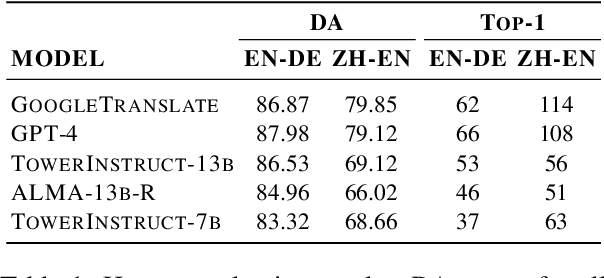

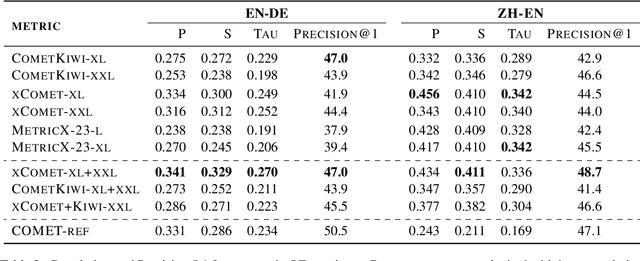
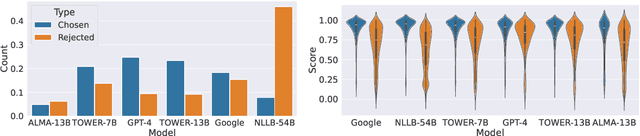
Alignment with human preferences is an important step in developing accurate and safe large language models. This is no exception in machine translation (MT), where better handling of language nuances and context-specific variations leads to improved quality. However, preference data based on human feedback can be very expensive to obtain and curate at a large scale. Automatic metrics, on the other hand, can induce preferences, but they might not match human expectations perfectly. In this paper, we propose an approach that leverages the best of both worlds. We first collect sentence-level quality assessments from professional linguists on translations generated by multiple high-quality MT systems and evaluate the ability of current automatic metrics to recover these preferences. We then use this analysis to curate a new dataset, MT-Pref (metric induced translation preference) dataset, which comprises 18k instances covering 18 language directions, using texts sourced from multiple domains post-2022. We show that aligning TOWER models on MT-Pref significantly improves translation quality on WMT23 and FLORES benchmarks.