 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Language Models Judge Action Quality? An Empirical Evaluation
Apr 09, 2026Action Quality Assessment (AQA) has broad applications in physical therapy, sports coaching, and competitive judging. Although Vision Language Models (VLMs) hold considerable promise for AQA, their actual performance in this domain remains largely uncharacterised. We present a comprehensive evaluation of state-of-the-art VLMs across activity domains (e.g. fitness, figure skating, diving), tasks, representations, and prompting strategies. Baseline results reveal that Gemini 3.1 Pro, Qwen3-VL and InternVL3.5 models perform only marginally above random chance, and although strategies such as incorporation of skeleton information, grounding instructions, reasoning structures and in-context learning lead to isolated gains, none is consistently effective. Analysis of prediction distributions uncovers two systematic biases: a tendency to predict correct execution regardless of visual evidence, and a sensitivity to superficial linguistic framing. Reformulating tasks contrastively to mitigate these biases yields minimal improvement, suggesting that the models' limitations go beyond these biases, pointing to a fundamental difficulty with fine-grained movement quality assessment. Our findings establish a rigorous baseline for future VLM-based AQA research and provide an actionable outline for failure modes requiring mitigation prior to reliable real-world deployment.
EuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
MindGuard: Guardrail Classifiers for Multi-Turn Mental Health Support
Feb 01, 2026Large language models are increasingly used for mental health support, yet their conversational coherence alone does not ensure clinical appropriateness. Existing general-purpose safeguards often fail to distinguish between therapeutic disclosures and genuine clinical crises, leading to safety failures. To address this gap, we introduce a clinically grounded risk taxonomy, developed in collaboration with PhD-level psychologists, that identifies actionable harm (e.g., self-harm and harm to others) while preserving space for safe, non-crisis therapeutic content. We release MindGuard-testset, a dataset of real-world multi-turn conversations annotated at the turn level by clinical experts. Using synthetic dialogues generated via a controlled two-agent setup, we train MindGuard, a family of lightweight safety classifiers (with 4B and 8B parameters). Our classifiers reduce false positives at high-recall operating points and, when paired with clinician language models, help achieve lower attack success and harmful engagement rates in adversarial multi-turn interactions compared to general-purpose safeguards. We release all models and human evaluation data.
EuroLLM-9B: Technical Report
Jun 04, 2025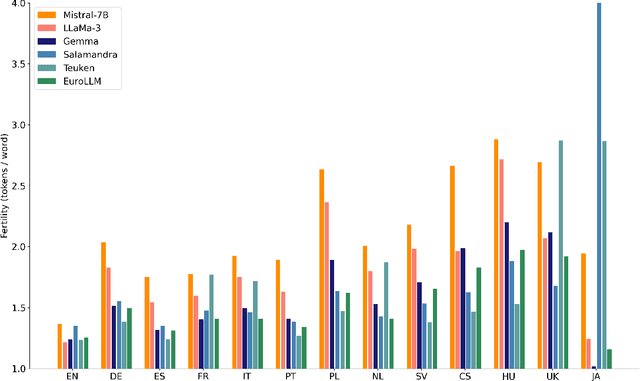
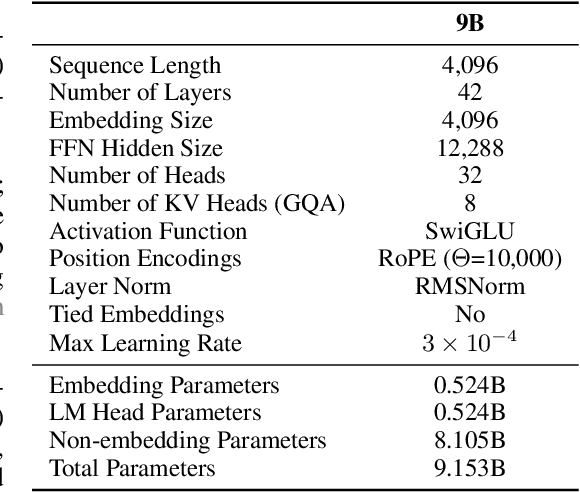
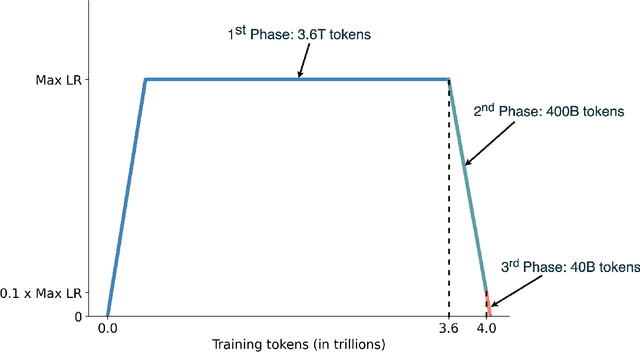
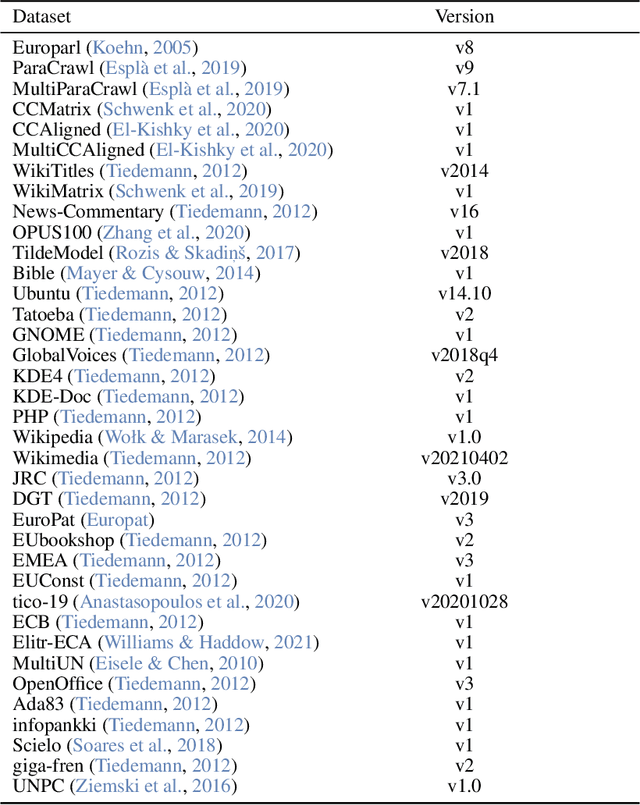
This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
EuroLLM: Multilingual Language Models for Europe
Sep 24, 2024The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English. In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages. We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations. Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct and report their performance on multilingual general benchmarks and machine translation.
Bridging the Gap: A Survey on Integrating Feedback for Natural Language Generation
May 01, 2023


Many recent advances in natural language generation have been fueled by training large language models on internet-scale data. However, this paradigm can lead to models that generate toxic, inaccurate, and unhelpful content, and automatic evaluation metrics often fail to identify these behaviors. As models become more capable, human feedback is an invaluable signal for evaluating and improving models. This survey aims to provide an overview of the recent research that has leveraged human feedback to improve natural language generation. First, we introduce an encompassing formalization of feedback, and identify and organize existing research into a taxonomy following this formalization. Next, we discuss how feedback can be described by its format and objective, and cover the two approaches proposed to use feedback (either for training or decoding): directly using the feedback or training feedback models. We also discuss existing datasets for human-feedback data collection, and concerns surrounding feedback collection. Finally, we provide an overview of the nascent field of AI feedback, which exploits large language models to make judgments based on a set of principles and minimize the need for human intervention.
Chunk-based Nearest Neighbor Machine Translation
May 24, 2022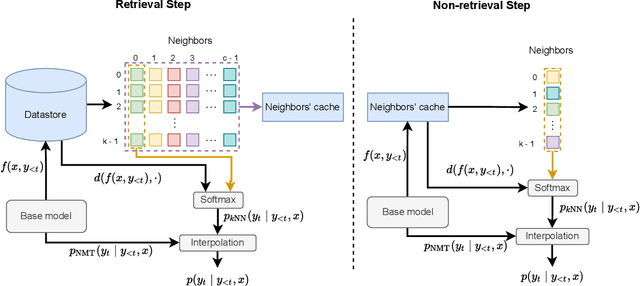
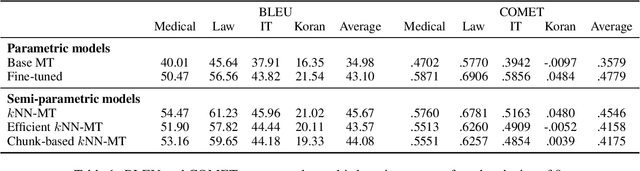
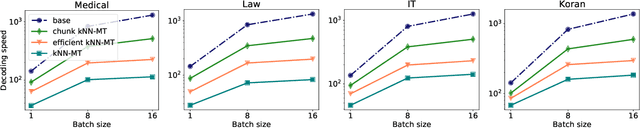
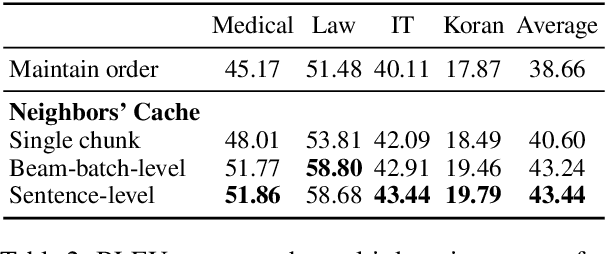
Semi-parametric models, which augment generation with retrieval, have led to impressive results in language modeling and machine translation, due to their ability to leverage information retrieved from a datastore of examples. One of the most prominent approaches, $k$NN-MT, has an outstanding performance on domain adaptation by retrieving tokens from a domain-specific datastore \citep{khandelwal2020nearest}. However, $k$NN-MT requires retrieval for every single generated token, leading to a very low decoding speed (around 8 times slower than a parametric model). In this paper, we introduce a \textit{chunk-based} $k$NN-MT model which retrieves chunks of tokens from the datastore, instead of a single token. We propose several strategies for incorporating the retrieved chunks into the generation process, and for selecting the steps at which the model needs to search for neighbors in the datastore. Experiments on machine translation in two settings, static domain adaptation and ``on-the-fly'' adaptation, show that the chunk-based $k$NN-MT model leads to a significant speed-up (up to 4 times) with only a small drop in translation quality.
Efficient Machine Translation Domain Adaptation
Apr 26, 2022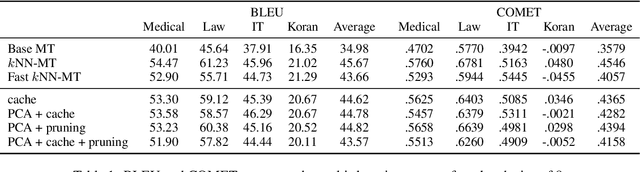
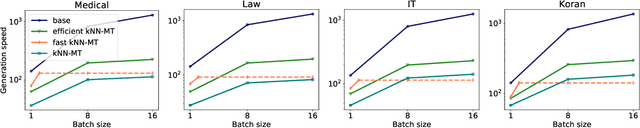
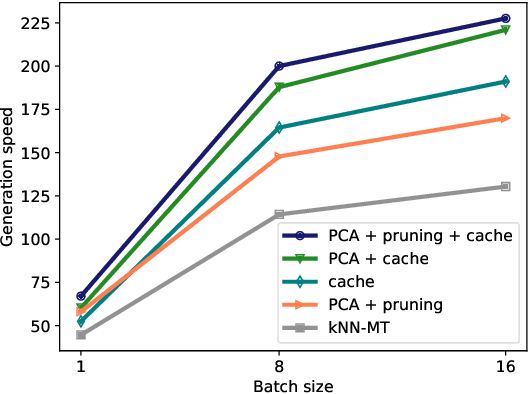
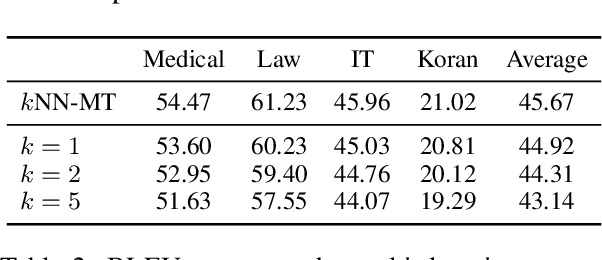
Machine translation models struggle when translating out-of-domain text, which makes domain adaptation a topic of critical importance. However, most domain adaptation methods focus on fine-tuning or training the entire or part of the model on every new domain, which can be costly. On the other hand, semi-parametric models have been shown to successfully perform domain adaptation by retrieving examples from an in-domain datastore (Khandelwal et al., 2021). A drawback of these retrieval-augmented models, however, is that they tend to be substantially slower. In this paper, we explore several approaches to speed up nearest neighbor machine translation. We adapt the methods recently proposed by He et al. (2021) for language modeling, and introduce a simple but effective caching strategy that avoids performing retrieval when similar contexts have been seen before. Translation quality and runtimes for several domains show the effectiveness of the proposed solutions.
$\infty$-former: Infinite Memory Transformer
Sep 15, 2021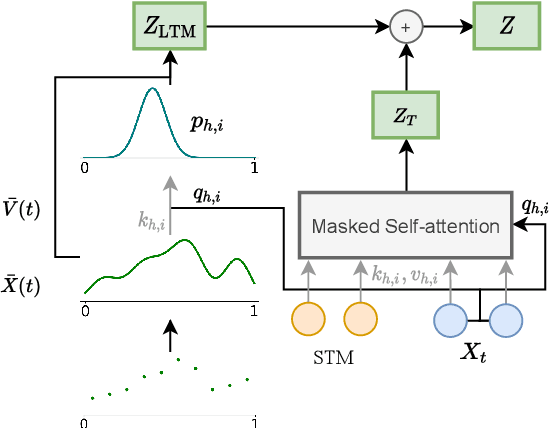

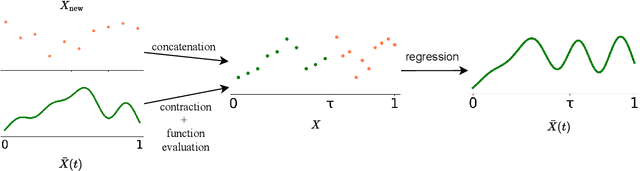

Transformers struggle when attending to long contexts, since the amount of computation grows with the context length, and therefore they cannot model long-term memories effectively. Several variations have been proposed to alleviate this problem, but they all have a finite memory capacity, being forced to drop old information. In this paper, we propose the $\infty$-former, which extends the vanilla transformer with an unbounded long-term memory. By making use of a continuous-space attention mechanism to attend over the long-term memory, the $\infty$-former's attention complexity becomes independent of the context length. Thus, it is able to model arbitrarily long contexts and maintain "sticky memories" while keeping a fixed computation budget. Experiments on a synthetic sorting task demonstrate the ability of the $\infty$-former to retain information from long sequences. We also perform experiments on language modeling, by training a model from scratch and by fine-tuning a pre-trained language model, which show benefits of unbounded long-term memories.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021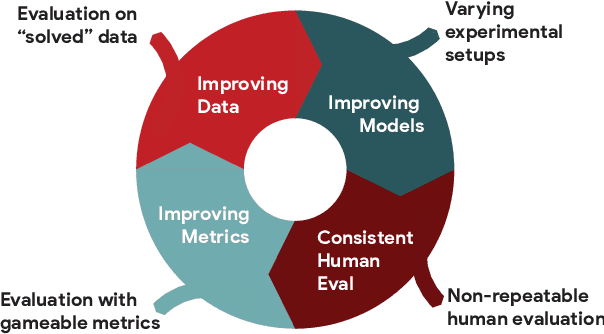
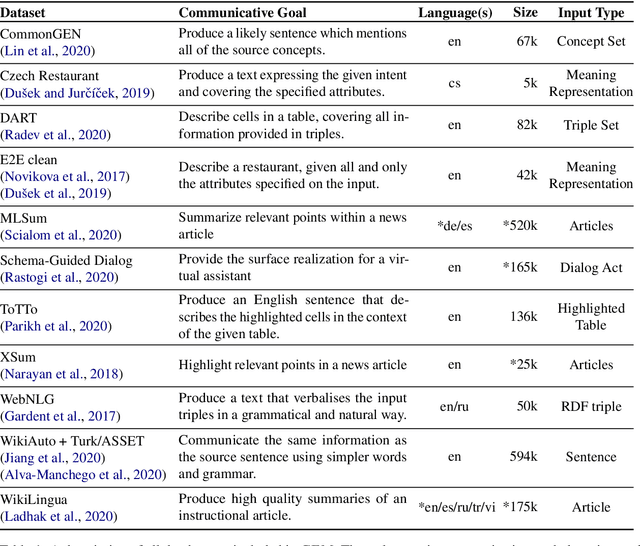
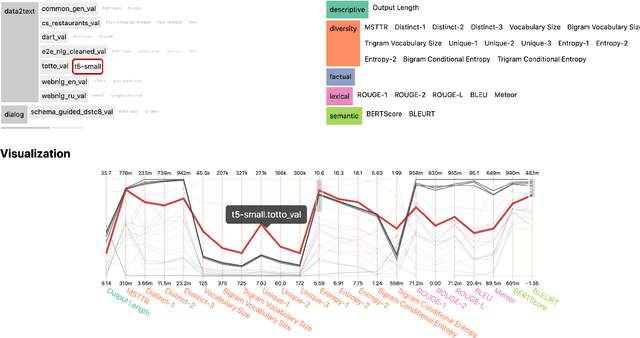
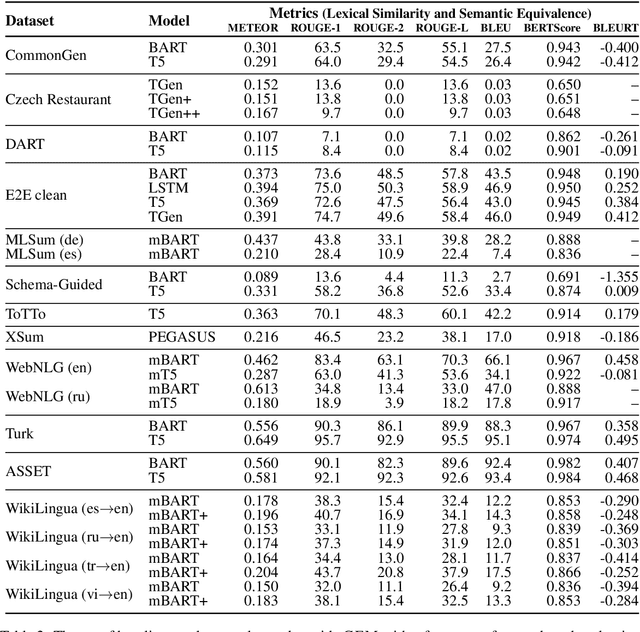
We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.