 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Collapse in Machine Translation Through the Lens of Angular Dispersion
Feb 19, 2026Modern neural translation models based on the Transformer architecture are known for their high performance, particularly when trained on high-resource datasets. A standard next-token prediction training strategy, while widely adopted in practice, may lead to overlooked artifacts such as representation collapse. Previous works have shown that this problem is especially pronounced in the representation of the deeper Transformer layers, where it often fails to efficiently utilize the geometric space. Representation collapse is even more evident in end-to-end training of continuous-output neural machine translation, where the trivial solution would be to set all vectors to the same value. In this work, we analyze the dynamics of representation collapse at different levels of discrete and continuous NMT transformers throughout training. We incorporate an existing regularization method based on angular dispersion and demonstrate empirically that it not only mitigates collapse but also improves translation quality. Furthermore, we show that quantized models exhibit similar collapse behavior and that the benefits of regularization are preserved even after quantization.
Unlocking Latent Discourse Translation in LLMs Through Quality-Aware Decoding
Oct 08, 2025Large language models (LLMs) have emerged as strong contenders in machine translation.Yet, they still struggle to adequately handle discourse phenomena, such as pronoun resolution and lexical cohesion at the document level. In this study, we thoroughly investigate the discourse phenomena performance of LLMs in context-aware translation. We demonstrate that discourse knowledge is encoded within LLMs and propose the use of quality-aware decoding (QAD) to effectively extract this knowledge, showcasing its superiority over other decoding approaches through comprehensive analysis. Furthermore, we illustrate that QAD enhances the semantic richness of translations and aligns them more closely with human preferences.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Keep your distance: learning dispersed embeddings on $\mathbb{S}_d$
Feb 12, 2025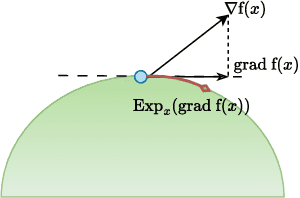

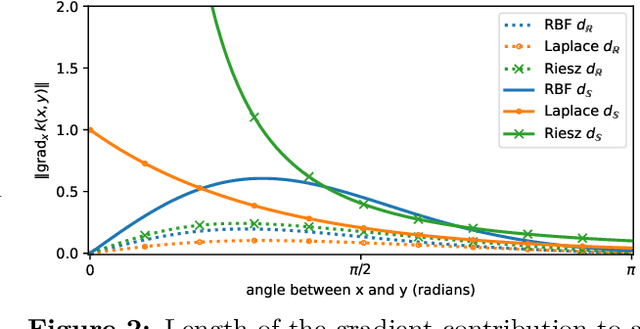
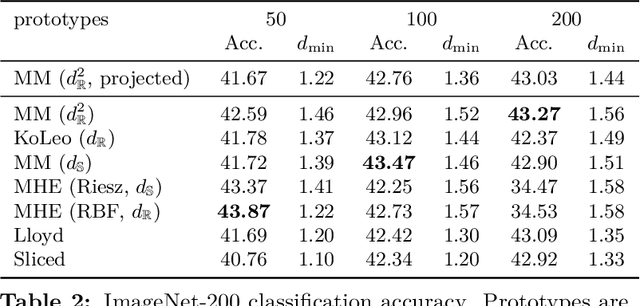
Learning well-separated features in high-dimensional spaces, such as text or image embeddings, is crucial for many machine learning applications. Achieving such separation can be effectively accomplished through the dispersion of embeddings, where unrelated vectors are pushed apart as much as possible. By constraining features to be on a hypersphere, we can connect dispersion to well-studied problems in mathematics and physics, where optimal solutions are known for limited low-dimensional cases. However, in representation learning we typically deal with a large number of features in high-dimensional space, and moreover, dispersion is usually traded off with some other task-oriented training objective, making existing theoretical and numerical solutions inapplicable. Therefore, it is common to rely on gradient-based methods to encourage dispersion, usually by minimizing some function of the pairwise distances. In this work, we first give an overview of existing methods from disconnected literature, making new connections and highlighting similarities. Next, we introduce some new angles. We propose to reinterpret pairwise dispersion using a maximum mean discrepancy (MMD) motivation. We then propose an online variant of the celebrated Lloyd's algorithm, of K-Means fame, as an effective alternative regularizer for dispersion on generic domains. Finally, we derive a novel dispersion method that directly exploits properties of the hypersphere. Our experiments show the importance of dispersion in image classification and natural language processing tasks, and how algorithms exhibit different trade-offs in different regimes.
Hopfield-Fenchel-Young Networks: A Unified Framework for Associative Memory Retrieval
Nov 13, 2024



Associative memory models, such as Hopfield networks and their modern variants, have garnered renewed interest due to advancements in memory capacity and connections with self-attention in transformers. In this work, we introduce a unified framework-Hopfield-Fenchel-Young networks-which generalizes these models to a broader family of energy functions. Our energies are formulated as the difference between two Fenchel-Young losses: one, parameterized by a generalized entropy, defines the Hopfield scoring mechanism, while the other applies a post-transformation to the Hopfield output. By utilizing Tsallis and norm entropies, we derive end-to-end differentiable update rules that enable sparse transformations, uncovering new connections between loss margins, sparsity, and exact retrieval of single memory patterns. We further extend this framework to structured Hopfield networks using the SparseMAP transformation, allowing the retrieval of pattern associations rather than a single pattern. Our framework unifies and extends traditional and modern Hopfield networks and provides an energy minimization perspective for widely used post-transformations like $\ell_2$-normalization and layer normalization-all through suitable choices of Fenchel-Young losses and by using convex analysis as a building block. Finally, we validate our Hopfield-Fenchel-Young networks on diverse memory recall tasks, including free and sequential recall. Experiments on simulated data, image retrieval, multiple instance learning, and text rationalization demonstrate the effectiveness of our approach.
We Augmented Whisper With kNN and You Won't Believe What Came Next
Oct 24, 2024



Speech recognition performance varies by language, domain, and speaker characteristics such as accent, and fine-tuning a model on any of these categories may lead to catastrophic forgetting. $k$ nearest neighbor search ($k$NN), first proposed for neural sequence decoders for natural language generation (NLG) and machine translation (MT), is a non-parametric method that can instead adapt by building an external datastore that can then be searched during inference time, without training the underlying model. We show that Whisper, a transformer end-to-end speech model, benefits from $k$NN. We investigate the differences between the speech and text setups. We discuss implications for speaker adaptation, and analyze improvements by gender, accent, and age.
Analyzing Context Utilization of LLMs in Document-Level Translation
Oct 18, 2024

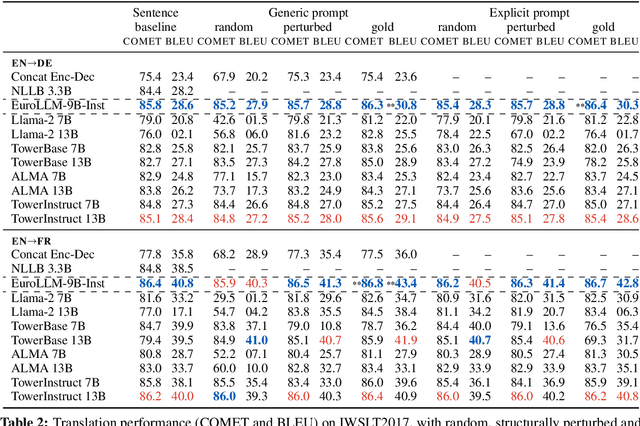
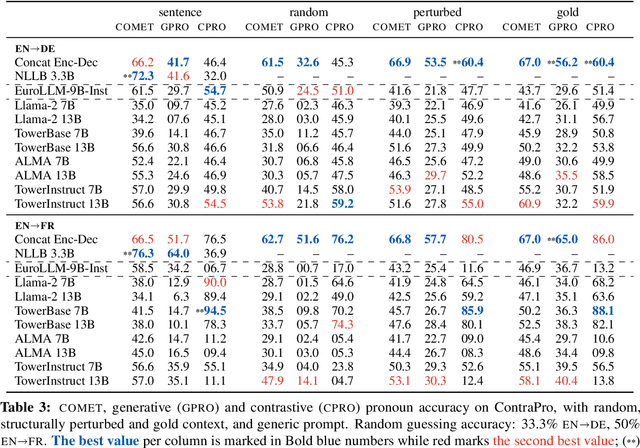
Large language models (LLM) are increasingly strong contenders in machine translation. We study document-level translation, where some words cannot be translated without context from outside the sentence. We investigate the ability of prominent LLMs to utilize context by analyzing models' robustness to perturbed and randomized document context. We find that LLMs' improved document-translation performance is not always reflected in pronoun translation performance. We highlight the need for context-aware finetuning of LLMs with a focus on relevant parts of the context to improve their reliability for document-level translation.
ARM: Efficient Guided Decoding with Autoregressive Reward Models
Jul 05, 2024



Language models trained on large amounts of data require careful tuning to be safely deployed in real world. We revisit the guided decoding paradigm, where the goal is to augment the logits of the base language model using the scores from a task-specific reward model. We propose a simple but efficient parameterization of the autoregressive reward model enabling fast and effective guided decoding. On detoxification and sentiment control tasks, we show that our efficient parameterization performs on par with RAD, a strong but less efficient guided decoding approach.
Sparse and Structured Hopfield Networks
Feb 21, 2024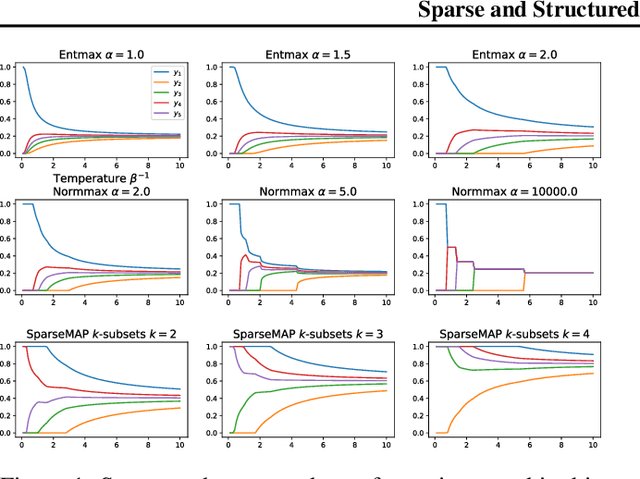
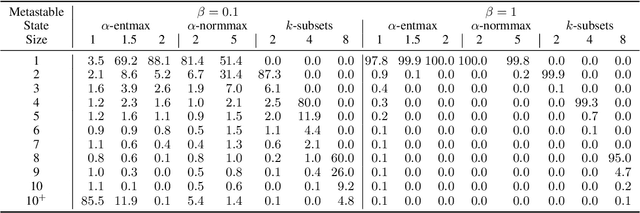
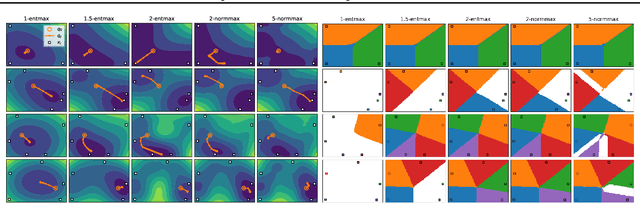
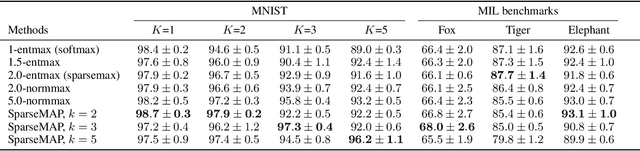
Modern Hopfield networks have enjoyed recent interest due to their connection to attention in transformers. Our paper provides a unified framework for sparse Hopfield networks by establishing a link with Fenchel-Young losses. The result is a new family of Hopfield-Fenchel-Young energies whose update rules are end-to-end differentiable sparse transformations. We reveal a connection between loss margins, sparsity, and exact memory retrieval. We further extend this framework to structured Hopfield networks via the SparseMAP transformation, which can retrieve pattern associations instead of a single pattern. Experiments on multiple instance learning and text rationalization demonstrate the usefulness of our approach.
On Measuring Context Utilization in Document-Level MT Systems
Feb 02, 2024

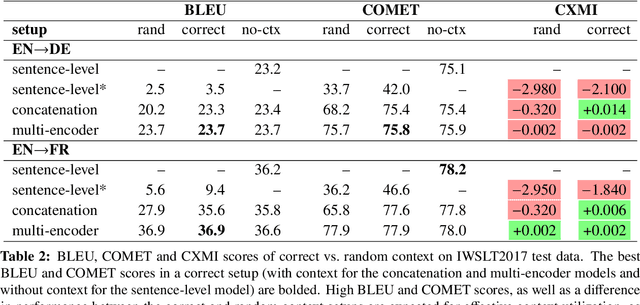

Document-level translation models are usually evaluated using general metrics such as BLEU, which are not informative about the benefits of context. Current work on context-aware evaluation, such as contrastive methods, only measure translation accuracy on words that need context for disambiguation. Such measures cannot reveal whether the translation model uses the correct supporting context. We propose to complement accuracy-based evaluation with measures of context utilization. We find that perturbation-based analysis (comparing models' performance when provided with correct versus random context) is an effective measure of overall context utilization. For a finer-grained phenomenon-specific evaluation, we propose to measure how much the supporting context contributes to handling context-dependent discourse phenomena. We show that automatically-annotated supporting context gives similar conclusions to human-annotated context and can be used as alternative for cases where human annotations are not available. Finally, we highlight the importance of using discourse-rich datasets when assessing context utilization.