 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Collapse in Machine Translation Through the Lens of Angular Dispersion
Feb 19, 2026Modern neural translation models based on the Transformer architecture are known for their high performance, particularly when trained on high-resource datasets. A standard next-token prediction training strategy, while widely adopted in practice, may lead to overlooked artifacts such as representation collapse. Previous works have shown that this problem is especially pronounced in the representation of the deeper Transformer layers, where it often fails to efficiently utilize the geometric space. Representation collapse is even more evident in end-to-end training of continuous-output neural machine translation, where the trivial solution would be to set all vectors to the same value. In this work, we analyze the dynamics of representation collapse at different levels of discrete and continuous NMT transformers throughout training. We incorporate an existing regularization method based on angular dispersion and demonstrate empirically that it not only mitigates collapse but also improves translation quality. Furthermore, we show that quantized models exhibit similar collapse behavior and that the benefits of regularization are preserved even after quantization.
ARM: Efficient Guided Decoding with Autoregressive Reward Models
Jul 05, 2024



Language models trained on large amounts of data require careful tuning to be safely deployed in real world. We revisit the guided decoding paradigm, where the goal is to augment the logits of the base language model using the scores from a task-specific reward model. We propose a simple but efficient parameterization of the autoregressive reward model enabling fast and effective guided decoding. On detoxification and sentiment control tasks, we show that our efficient parameterization performs on par with RAD, a strong but less efficient guided decoding approach.
CodeBPE: Investigating Subtokenization Options for Large Language Model Pretraining on Source Code
Aug 01, 2023



Recent works have widely adopted large language model pretraining for source code, suggested source code-specific pretraining objectives and investigated the applicability of various Transformer-based language model architectures for source code. This work investigates another important aspect of such models, namely the effect of different subtokenization options, and aims at identifying most effective and length-efficient subtokenizations, taking into account code specifics. We propose subtokenziation that reduces average length by 17% without downstream performance drop, and show that a carefully chosen subtokenization may improve quality by 0.5-2%, possibly with some length increase.
SantaCoder: don't reach for the stars!
Jan 09, 2023



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
Probing Pretrained Models of Source Code
Feb 16, 2022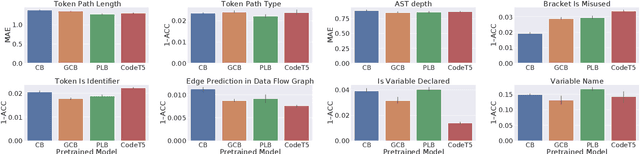
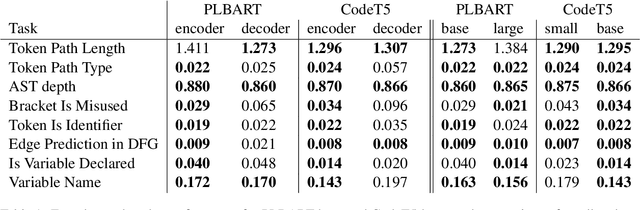
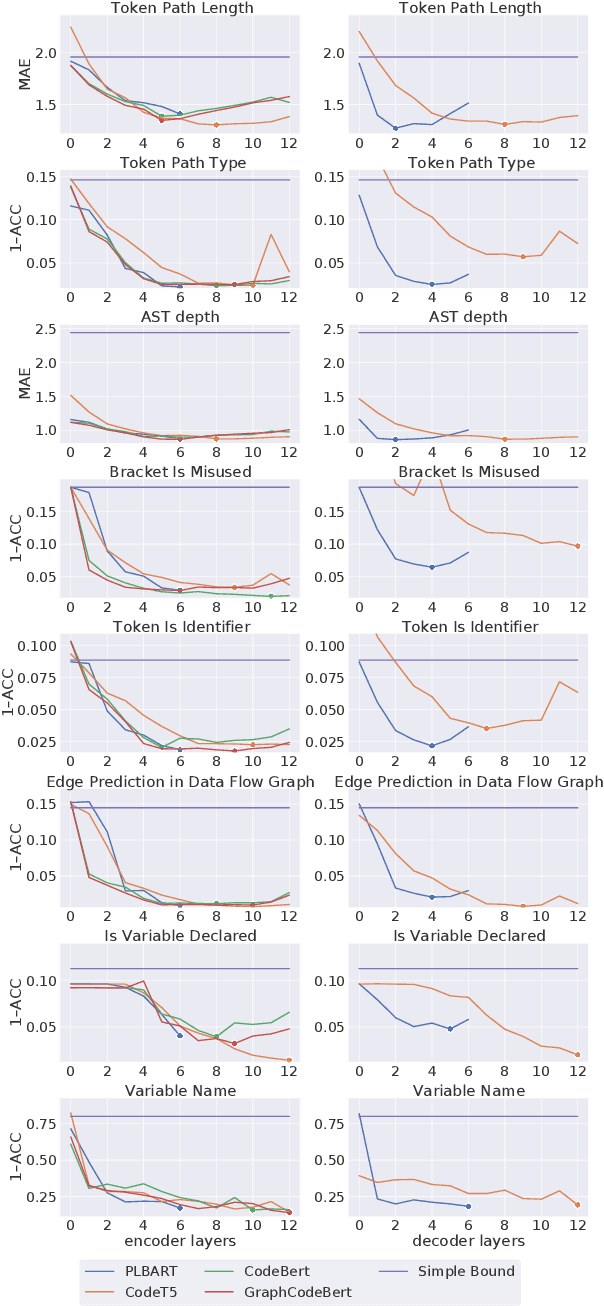
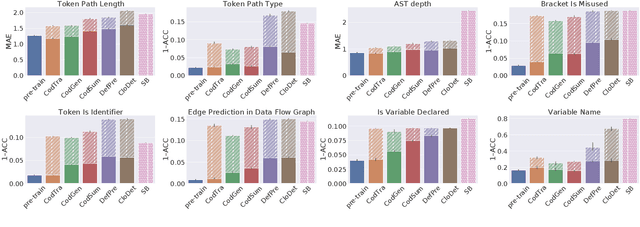
Deep learning models are widely used for solving challenging code processing tasks, such as code generation or code summarization. Traditionally, a specific model architecture was carefully built to solve a particular code processing task. However, recently general pretrained models such as CodeBERT or CodeT5 have been shown to outperform task-specific models in many applications. While pretrained models are known to learn complex patterns from data, they may fail to understand some properties of source code. To test diverse aspects of code understanding, we introduce a set of diagnosting probing tasks. We show that pretrained models of code indeed contain information about code syntactic structure and correctness, the notions of identifiers, data flow and namespaces, and natural language naming. We also investigate how probing results are affected by using code-specific pretraining objectives, varying the model size, or finetuning.
Machine Learning Methods for Spectral Efficiency Prediction in Massive MIMO Systems
Dec 29, 2021

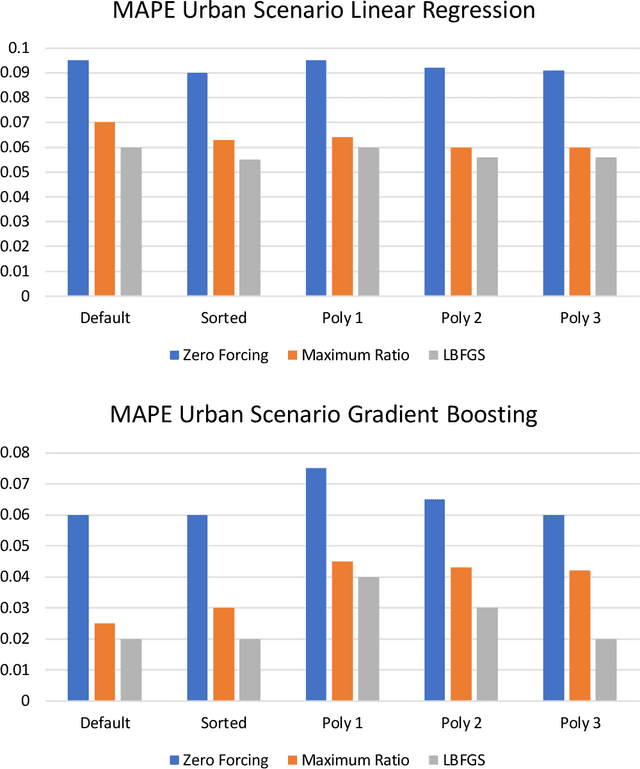
Channel decoding, channel detection, channel assessment, and resource management for wireless multiple-input multiple-output (MIMO) systems are all examples of problems where machine learning (ML) can be successfully applied. In this paper, we study several ML approaches to solve the problem of estimating the spectral efficiency (SE) value for a certain precoding scheme, preferably in the shortest possible time. The best results in terms of mean average percentage error (MAPE) are obtained with gradient boosting over sorted features, while linear models demonstrate worse prediction quality. Neural networks perform similarly to gradient boosting, but they are more resource- and time-consuming because of hyperparameter tuning and frequent retraining. We investigate the practical applicability of the proposed algorithms in a wide range of scenarios generated by the Quadriga simulator. In almost all scenarios, the MAPE achieved using gradient boosting and neural networks is less than 10\%.
A Simple Approach for Handling Out-of-Vocabulary Identifiers in Deep Learning for Source Code
Oct 23, 2020
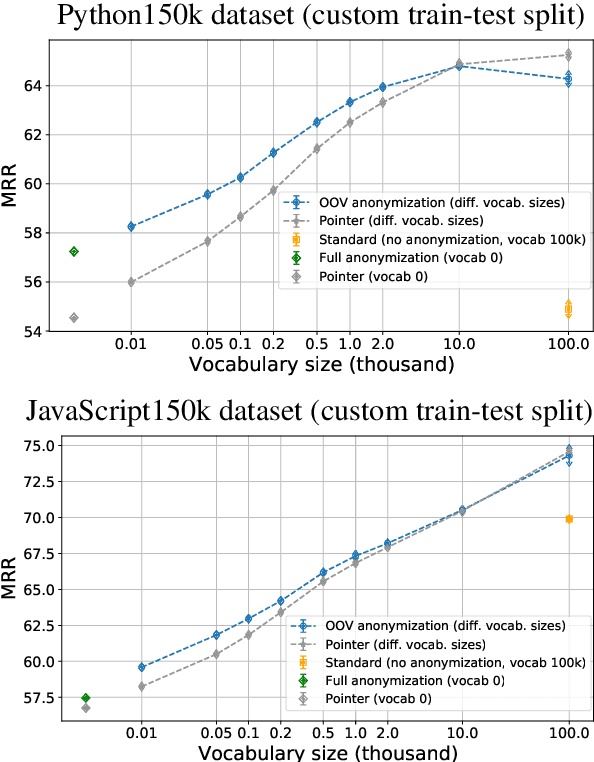
There is an emerging interest in the application of deep learning models to source code processing tasks. One of the major problems in applying deep learning to software engineering is that source code often contains a lot of rare identifiers resulting in huge vocabularies. We propose a simple yet effective method based on identifier anonymization to handle out-of-vocabulary (OOV) identifiers. Our method can be treated as a preprocessing step and therefore allows an easy implementation. We show that the proposed OOV anonymization method significantly improves the performance of the Transformer in two code processing tasks: code completion and bug fixing.
Empirical Study of Transformers for Source Code
Oct 15, 2020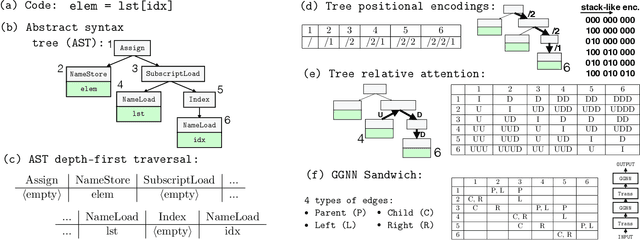


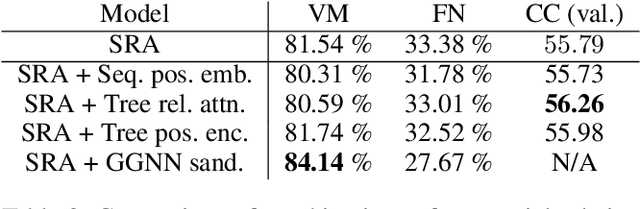
Initially developed for natural language processing (NLP), Transformers are now widely used for source code processing, due to the format similarity between source code and text. In contrast to natural language, source code is strictly structured, i. e. follows the syntax of the programming language. Several recent works develop Transformer modifications for capturing syntactic information in source code. The drawback of these works is that they do not compare to each other and all consider different tasks. In this work, we conduct a thorough empirical study of the capabilities of Transformers to utilize syntactic information in different tasks. We consider three tasks (code completion, function naming and bug fixing) and re-implement different syntax-capturing modifications in a unified framework. We show that Transformers are able to make meaningful predictions based purely on syntactic information and underline the best practices of taking the syntactic information into account for improving the performance of the model.