 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Pretrained Models of Source Code
Paper and Code
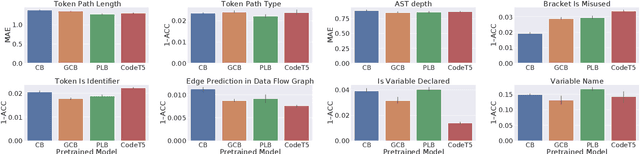
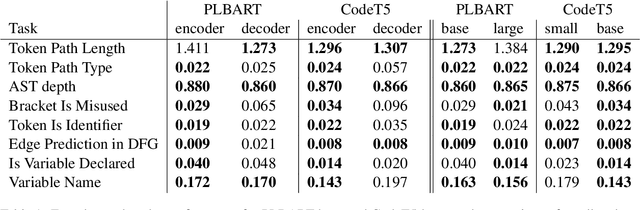
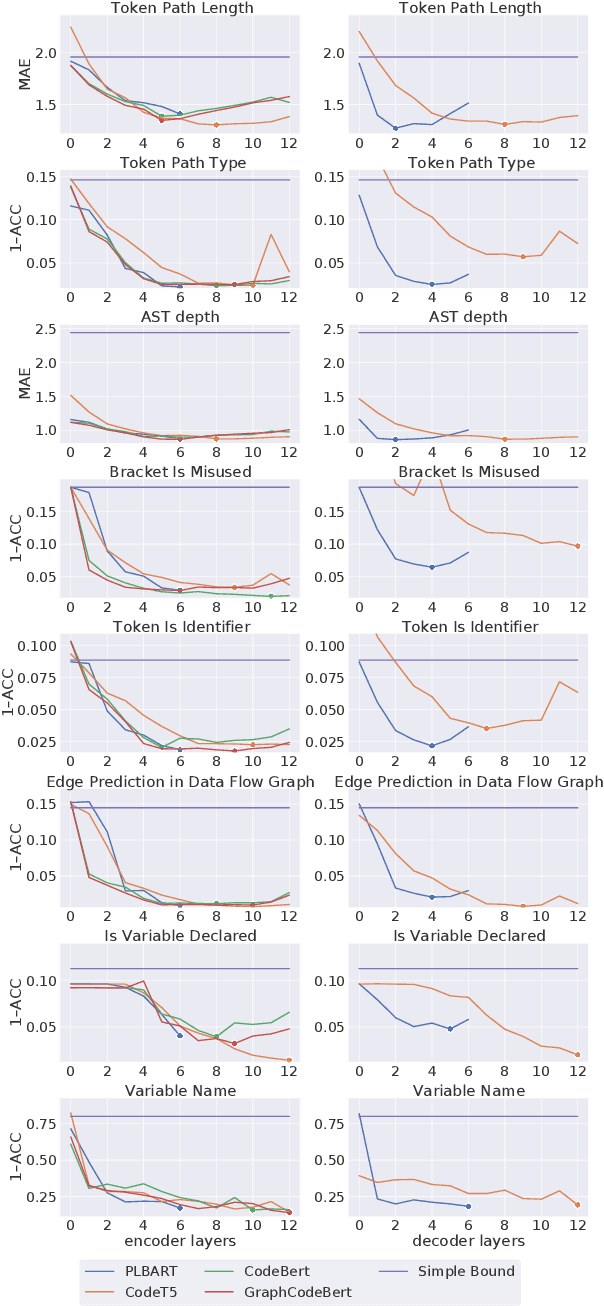
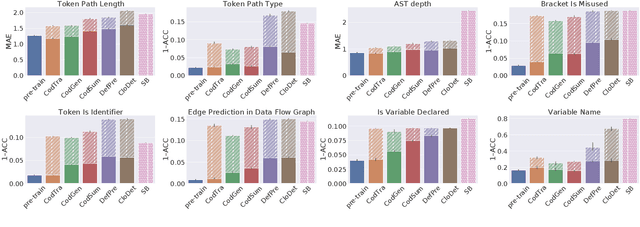
Deep learning models are widely used for solving challenging code processing tasks, such as code generation or code summarization. Traditionally, a specific model architecture was carefully built to solve a particular code processing task. However, recently general pretrained models such as CodeBERT or CodeT5 have been shown to outperform task-specific models in many applications. While pretrained models are known to learn complex patterns from data, they may fail to understand some properties of source code. To test diverse aspects of code understanding, we introduce a set of diagnosting probing tasks. We show that pretrained models of code indeed contain information about code syntactic structure and correctness, the notions of identifiers, data flow and namespaces, and natural language naming. We also investigate how probing results are affected by using code-specific pretraining objectives, varying the model size, or finetuning.