 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.
FlexOlmo: Open Language Models for Flexible Data Use
Jul 09, 2025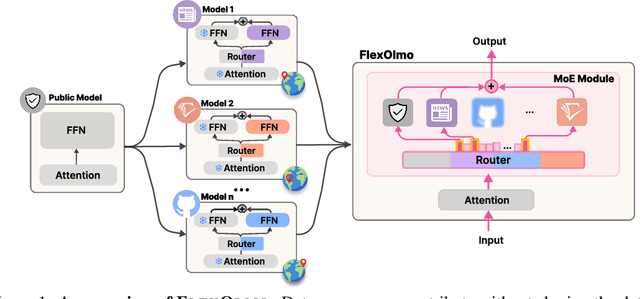
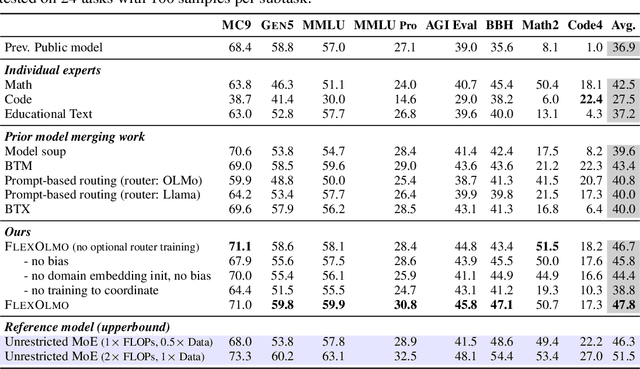
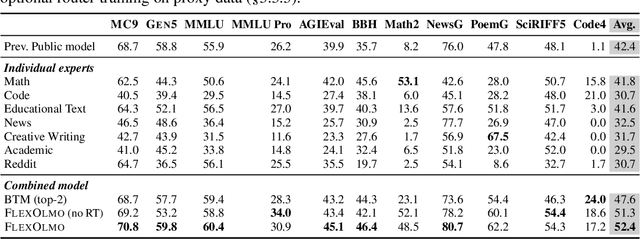
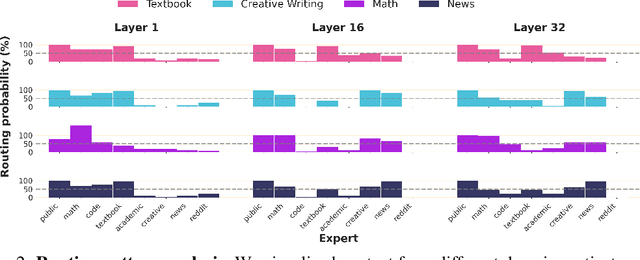
We introduce FlexOlmo, a new class of language models (LMs) that supports (1) distributed training without data sharing, where different model parameters are independently trained on closed datasets, and (2) data-flexible inference, where these parameters along with their associated data can be flexibly included or excluded from model inferences with no further training. FlexOlmo employs a mixture-of-experts (MoE) architecture where each expert is trained independently on closed datasets and later integrated through a new domain-informed routing without any joint training. FlexOlmo is trained on FlexMix, a corpus we curate comprising publicly available datasets alongside seven domain-specific sets, representing realistic approximations of closed sets. We evaluate models with up to 37 billion parameters (20 billion active) on 31 diverse downstream tasks. We show that a general expert trained on public data can be effectively combined with independently trained experts from other data owners, leading to an average 41% relative improvement while allowing users to opt out of certain data based on data licensing or permission requirements. Our approach also outperforms prior model merging methods by 10.1% on average and surpasses the standard MoE trained without data restrictions using the same training FLOPs. Altogether, this research presents a solution for both data owners and researchers in regulated industries with sensitive or protected data. FlexOlmo enables benefiting from closed data while respecting data owners' preferences by keeping their data local and supporting fine-grained control of data access during inference.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Crosslingual Reasoning through Test-Time Scaling
May 08, 2025Reasoning capabilities of large language models are primarily studied for English, even when pretrained models are multilingual. In this work, we investigate to what extent English reasoning finetuning with long chain-of-thoughts (CoTs) can generalize across languages. First, we find that scaling up inference compute for English-centric reasoning language models (RLMs) improves multilingual mathematical reasoning across many languages including low-resource languages, to an extent where they outperform models twice their size. Second, we reveal that while English-centric RLM's CoTs are naturally predominantly English, they consistently follow a quote-and-think pattern to reason about quoted non-English inputs. Third, we discover an effective strategy to control the language of long CoT reasoning, and we observe that models reason better and more efficiently in high-resource languages. Finally, we observe poor out-of-domain reasoning generalization, in particular from STEM to cultural commonsense knowledge, even for English. Overall, we demonstrate the potentials, study the mechanisms and outline the limitations of crosslingual generalization of English reasoning test-time scaling. We conclude that practitioners should let English-centric RLMs reason in high-resource languages, while further work is needed to improve reasoning in low-resource languages and out-of-domain contexts.
ReasonIR: Training Retrievers for Reasoning Tasks
Apr 29, 2025We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.
MIEB: Massive Image Embedding Benchmark
Apr 14, 2025Image representations are often evaluated through disjointed, task-specific protocols, leading to a fragmented understanding of model capabilities. For instance, it is unclear whether an image embedding model adept at clustering images is equally good at retrieving relevant images given a piece of text. We introduce the Massive Image Embedding Benchmark (MIEB) to evaluate the performance of image and image-text embedding models across the broadest spectrum to date. MIEB spans 38 languages across 130 individual tasks, which we group into 8 high-level categories. We benchmark 50 models across our benchmark, finding that no single method dominates across all task categories. We reveal hidden capabilities in advanced vision models such as their accurate visual representation of texts, and their yet limited capabilities in interleaved encodings and matching images and texts in the presence of confounders. We also show that the performance of vision encoders on MIEB correlates highly with their performance when used in multimodal large language models. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.
Retro-Search: Exploring Untaken Paths for Deeper and Efficient Reasoning
Apr 06, 2025



Large reasoning models exhibit remarkable reasoning capabilities via long, elaborate reasoning trajectories. Supervised fine-tuning on such reasoning traces, also known as distillation, can be a cost-effective way to boost reasoning capabilities of student models. However, empirical observations reveal that these reasoning trajectories are often suboptimal, switching excessively between different lines of thought, resulting in under-thinking, over-thinking, and even degenerate responses. We introduce Retro-Search, an MCTS-inspired search algorithm, for distilling higher quality reasoning paths from large reasoning models. Retro-Search retrospectively revises reasoning paths to discover better, yet shorter traces, which can then lead to student models with enhanced reasoning capabilities with shorter, thus faster inference. Our approach can enable two use cases: self-improvement, where models are fine-tuned on their own Retro-Search-ed thought traces, and weak-to-strong improvement, where a weaker model revises stronger model's thought traces via Retro-Search. For self-improving, R1-distill-7B, fine-tuned on its own Retro-Search-ed traces, reduces the average reasoning length by 31.2% while improving performance by 7.7% across seven math benchmarks. For weak-to-strong improvement, we retrospectively revise R1-671B's traces from the OpenThoughts dataset using R1-distill-32B as the Retro-Search-er, a model 20x smaller. Qwen2.5-32B, fine-tuned on this refined data, achieves performance comparable to R1-distill-32B, yielding an 11.3% reduction in reasoning length and a 2.4% performance improvement compared to fine-tuning on the original OpenThoughts data. Our work counters recently emergent viewpoints that question the relevance of search algorithms in the era of large reasoning models, by demonstrating that there are still opportunities for algorithmic advancements, even for frontier models.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
s1: Simple test-time scaling
Jan 31, 2025



Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts. We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end. This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised finetuning the Qwen2.5-32B-Instruct language model on s1K and equipping it with budget forcing, our model s1 exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24). Further, scaling s1 with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24. Our model, data, and code are open-source at https://github.com/simplescaling/s1.