 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrillion 7B Technical Report
Apr 21, 2025We introduce Trillion-7B, the most token-efficient Korean-centric multilingual LLM available. Our novel Cross-lingual Document Attention (XLDA) mechanism enables highly efficient and effective knowledge transfer from English to target languages like Korean and Japanese. Combined with optimized data mixtures, language-specific filtering, and tailored tokenizer construction, Trillion-7B achieves competitive performance while dedicating only 10\% of its 2T training tokens to multilingual data and requiring just 59.4K H100 GPU hours (\$148K) for full training. Comprehensive evaluations across 27 benchmarks in four languages demonstrate Trillion-7B's robust multilingual performance and exceptional cross-lingual consistency.
LLM-AS-AN-INTERVIEWER: Beyond Static Testing Through Dynamic LLM Evaluation
Dec 10, 2024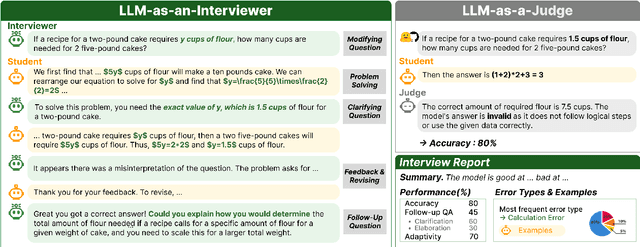
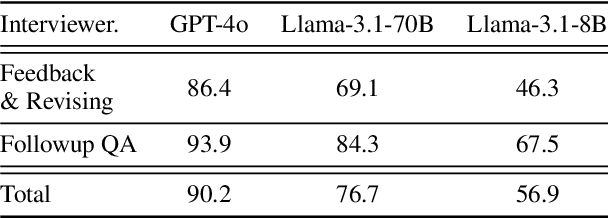
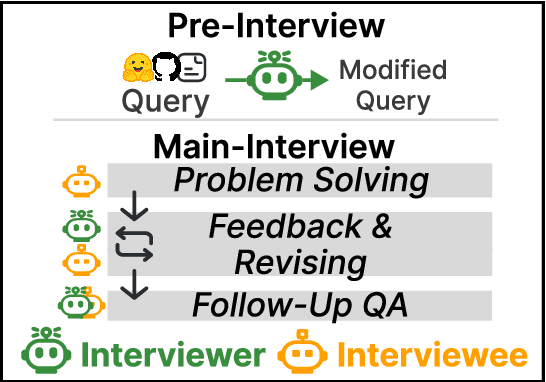
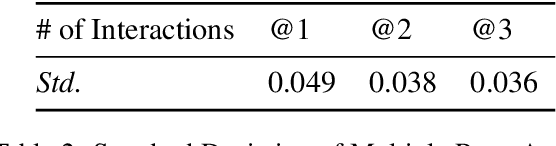
We introduce a novel evaluation paradigm for large language models (LLMs), LLM-as-an-Interviewer. This approach consists of a two stage process designed to assess the true capabilities of LLMs: first, modifying benchmark datasets to generate initial queries, and second, interacting with the LLM through feedback and follow up questions. Compared to existing evaluation methods such as LLM as a Judge, our framework addresses several limitations, including data contamination, verbosity bias, and self enhancement bias. Additionally, we show that our multi turn evaluation process provides valuable insights into the LLM's performance in real-world scenarios, including its adaptability to feedback and its ability to handle follow up questions, including clarification or requests for additional knowledge. Finally, we propose the Interview Report, which offers a comprehensive reflection of an LLM's strengths and weaknesses, illustrated with specific examples from the interview process. This report delivers a snapshot of the LLM's capabilities, providing a detailed picture of its practical performance.
Evaluating Language Models as Synthetic Data Generators
Dec 04, 2024



Given the increasing use of synthetic data in language model (LM) post-training, an LM's ability to generate high-quality data has become nearly as crucial as its ability to solve problems directly. While prior works have focused on developing effective data generation methods, they lack systematic comparison of different LMs as data generators in a unified setting. To address this gap, we propose AgoraBench, a benchmark that provides standardized settings and metrics to evaluate LMs' data generation abilities. Through synthesizing 1.26 million training instances using 6 LMs and training 99 student models, we uncover key insights about LMs' data generation capabilities. First, we observe that LMs exhibit distinct strengths. For instance, GPT-4o excels at generating new problems, while Claude-3.5-Sonnet performs better at enhancing existing ones. Furthermore, our analysis reveals that an LM's data generation ability doesn't necessarily correlate with its problem-solving ability. Instead, multiple intrinsic features of data quality-including response quality, perplexity, and instruction difficulty-collectively serve as better indicators. Finally, we demonstrate that strategic choices in output format and cost-conscious model selection significantly impact data generation effectiveness.
MM-Eval: A Multilingual Meta-Evaluation Benchmark for LLM-as-a-Judge and Reward Models
Oct 23, 2024



Large language models (LLMs) are commonly used as evaluators in tasks (e.g., reward modeling, LLM-as-a-judge), where they act as proxies for human preferences or judgments. This leads to the need for meta-evaluation: evaluating the credibility of LLMs as evaluators. However, existing benchmarks primarily focus on English, offering limited insight into LLMs' effectiveness as evaluators in non-English contexts. To address this, we introduce MM-Eval, a multilingual meta-evaluation benchmark that covers 18 languages across six categories. MM-Eval evaluates various dimensions, including language-specific challenges like linguistics and language hallucinations. Evaluation results show that both proprietary and open-source language models have considerable room for improvement. Further analysis reveals a tendency for these models to assign middle-ground scores to low-resource languages. We publicly release our benchmark and code.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
May 02, 2024
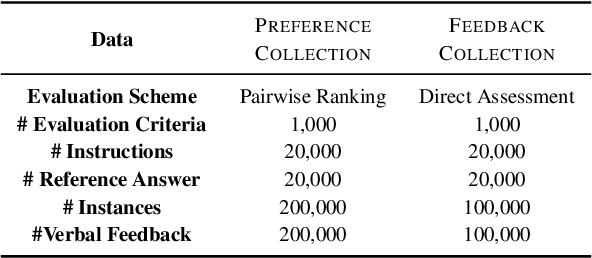


Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
CLIcK: A Benchmark Dataset of Cultural and Linguistic Intelligence in Korean
Mar 15, 2024Despite the rapid development of large language models (LLMs) for the Korean language, there remains an obvious lack of benchmark datasets that test the requisite Korean cultural and linguistic knowledge. Because many existing Korean benchmark datasets are derived from the English counterparts through translation, they often overlook the different cultural contexts. For the few benchmark datasets that are sourced from Korean data capturing cultural knowledge, only narrow tasks such as bias and hate speech detection are offered. To address this gap, we introduce a benchmark of Cultural and Linguistic Intelligence in Korean (CLIcK), a dataset comprising 1,995 QA pairs. CLIcK sources its data from official Korean exams and textbooks, partitioning the questions into eleven categories under the two main categories of language and culture. For each instance in CLIcK, we provide fine-grained annotation of which cultural and linguistic knowledge is required to answer the question correctly. Using CLIcK, we test 13 language models to assess their performance. Our evaluation uncovers insights into their performances across the categories, as well as the diverse factors affecting their comprehension. CLIcK offers the first large-scale comprehensive Korean-centric analysis of LLMs' proficiency in Korean culture and language.