 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChecklists Are Better Than Reward Models For Aligning Language Models
Jul 24, 2025



Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this -- typically using fixed criteria such as "helpfulness" and "harmfulness". In our work, we instead propose using flexible, instruction-specific criteria as a means of broadening the impact that reinforcement learning can have in eliciting instruction following. We propose "Reinforcement Learning from Checklist Feedback" (RLCF). From instructions, we extract checklists and evaluate how well responses satisfy each item - using both AI judges and specialized verifier programs - then combine these scores to compute rewards for RL. We compare RLCF with other alignment methods applied to a strong instruction following model (Qwen2.5-7B-Instruct) on five widely-studied benchmarks -- RLCF is the only method to improve performance on every benchmark, including a 4-point boost in hard satisfaction rate on FollowBench, a 6-point increase on InFoBench, and a 3-point rise in win rate on Arena-Hard. These results establish checklist feedback as a key tool for improving language models' support of queries that express a multitude of needs.
Evaluating Language Models as Synthetic Data Generators
Dec 04, 2024



Given the increasing use of synthetic data in language model (LM) post-training, an LM's ability to generate high-quality data has become nearly as crucial as its ability to solve problems directly. While prior works have focused on developing effective data generation methods, they lack systematic comparison of different LMs as data generators in a unified setting. To address this gap, we propose AgoraBench, a benchmark that provides standardized settings and metrics to evaluate LMs' data generation abilities. Through synthesizing 1.26 million training instances using 6 LMs and training 99 student models, we uncover key insights about LMs' data generation capabilities. First, we observe that LMs exhibit distinct strengths. For instance, GPT-4o excels at generating new problems, while Claude-3.5-Sonnet performs better at enhancing existing ones. Furthermore, our analysis reveals that an LM's data generation ability doesn't necessarily correlate with its problem-solving ability. Instead, multiple intrinsic features of data quality-including response quality, perplexity, and instruction difficulty-collectively serve as better indicators. Finally, we demonstrate that strategic choices in output format and cost-conscious model selection significantly impact data generation effectiveness.
ALR$^2$: A Retrieve-then-Reason Framework for Long-context Question Answering
Oct 04, 2024



The context window of large language models (LLMs) has been extended significantly in recent years. However, while the context length that the LLM can process has grown, the capability of the model to accurately reason over that context degrades noticeably. This occurs because modern LLMs often become overwhelmed by the vast amount of information in the context; when answering questions, the model must identify and reason over relevant evidence sparsely distributed throughout the text. To alleviate the challenge of long-context reasoning, we develop a retrieve-then-reason framework, enabling LLMs to reason over relevant evidence collected during an intermediate retrieval step. We find that modern LLMs struggle to accurately retrieve relevant facts and instead, often hallucinate "retrieved facts", resulting in flawed reasoning and the production of incorrect answers. To address these issues, we introduce ALR$^2$, a method that augments the long-context reasoning capability of LLMs via an explicit two-stage procedure, i.e., aligning LLMs with the objectives of both retrieval and reasoning. We demonstrate the efficacy of ALR$^2$ for mitigating performance degradation in long-context reasoning tasks. Through extensive experiments on long-context QA benchmarks, we find our method to outperform competitive baselines by large margins, achieving at least 8.4 and 7.9 EM gains on the long-context versions of HotpotQA and SQuAD datasets, respectively.
SELF-GUIDE: Better Task-Specific Instruction Following via Self-Synthetic Finetuning
Jul 16, 2024



Large language models (LLMs) hold the promise of solving diverse tasks when provided with appropriate natural language prompts. However, prompting often leads models to make predictions with lower accuracy compared to finetuning a model with ample training data. On the other hand, while finetuning LLMs on task-specific data generally improves their performance, abundant annotated datasets are not available for all tasks. Previous work has explored generating task-specific data from state-of-the-art LLMs and using this data to finetune smaller models, but this approach requires access to a language model other than the one being trained, which introduces cost, scalability challenges, and legal hurdles associated with continuously relying on more powerful LLMs. In response to these, we propose SELF-GUIDE, a multi-stage mechanism in which we synthesize task-specific input-output pairs from the student LLM, then use these input-output pairs to finetune the student LLM itself. In our empirical evaluation of the Natural Instructions V2 benchmark, we find that SELF-GUIDE improves the performance of LLM by a substantial margin. Specifically, we report an absolute improvement of approximately 15% for classification tasks and 18% for generation tasks in the benchmark's metrics. This sheds light on the promise of self-synthesized data guiding LLMs towards becoming task-specific experts without any external learning signals.
Training Task Experts through Retrieval Based Distillation
Jul 07, 2024



One of the most reliable ways to create deployable models for specialized tasks is to obtain an adequate amount of high-quality task-specific data. However, for specialized tasks, often such datasets do not exist. Existing methods address this by creating such data from large language models (LLMs) and then distilling such knowledge into smaller models. However, these methods are limited by the quality of the LLMs output, and tend to generate repetitive or incorrect data. In this work, we present Retrieval Based Distillation (ReBase), a method that first retrieves data from rich online sources and then transforms them into domain-specific data. This method greatly enhances data diversity. Moreover, ReBase generates Chain-of-Thought reasoning and distills the reasoning capacity of LLMs. We test our method on 4 benchmarks and results show that our method significantly improves performance by up to 7.8% on SQuAD, 1.37% on MNLI, and 1.94% on BigBench-Hard.
Synthetic Multimodal Question Generation
Jul 02, 2024



Multimodal Retrieval Augmented Generation (MMRAG) is a powerful approach to question-answering over multimodal documents. A key challenge with evaluating MMRAG is the paucity of high-quality datasets matching the question styles and modalities of interest. In light of this, we propose SMMQG, a synthetic data generation framework. SMMQG leverages interplay between a retriever, large language model (LLM) and large multimodal model (LMM) to generate question and answer pairs directly from multimodal documents, with the questions conforming to specified styles and modalities. We use SMMQG to generate an MMRAG dataset of 1024 questions over Wikipedia documents and evaluate state-of-the-art models using it, revealing insights into model performance that are attainable only through style- and modality-specific evaluation data. Next, we measure the quality of data produced by SMMQG via a human study. We find that the quality of our synthetic data is on par with the quality of the crowdsourced benchmark MMQA and that downstream evaluation results using both datasets strongly concur.
Better Synthetic Data by Retrieving and Transforming Existing Datasets
Apr 26, 2024



Despite recent advances in large language models, building dependable and deployable NLP models typically requires abundant, high-quality training data. However, task-specific data is not available for many use cases, and manually curating task-specific data is labor-intensive. Recent work has studied prompt-driven synthetic data generation using large language models, but these generated datasets tend to lack complexity and diversity. To address these limitations, we introduce a method, DataTune, to make better use of existing, publicly available datasets to improve automatic dataset generation. DataTune performs dataset transformation, enabling the repurposing of publicly available datasets into a format that is directly aligned with the specific requirements of target tasks. On a diverse set of language-based tasks from the BIG-Bench benchmark, we find that finetuning language models via DataTune improves over a few-shot prompting baseline by 49% and improves over existing methods that use synthetic or retrieved training data by 34%. We find that dataset transformation significantly increases the diversity and difficulty of generated data on many tasks. We integrate DataTune into an open-source repository to make this method accessible to the community: https://github.com/neulab/prompt2model.
Measuring Adversarial Datasets
Nov 06, 2023



In the era of widespread public use of AI systems across various domains, ensuring adversarial robustness has become increasingly vital to maintain safety and prevent undesirable errors. Researchers have curated various adversarial datasets (through perturbations) for capturing model deficiencies that cannot be revealed in standard benchmark datasets. However, little is known about how these adversarial examples differ from the original data points, and there is still no methodology to measure the intended and unintended consequences of those adversarial transformations. In this research, we conducted a systematic survey of existing quantifiable metrics that describe text instances in NLP tasks, among dimensions of difficulty, diversity, and disagreement. We selected several current adversarial effect datasets and compared the distributions between the original and their adversarial counterparts. The results provide valuable insights into what makes these datasets more challenging from a metrics perspective and whether they align with underlying assumptions.
Prompt2Model: Generating Deployable Models from Natural Language Instructions
Aug 23, 2023
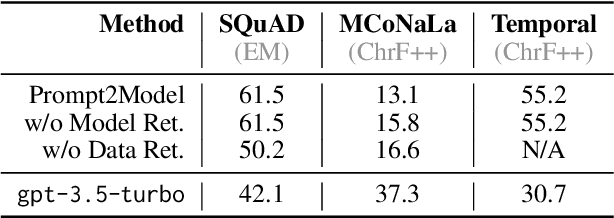
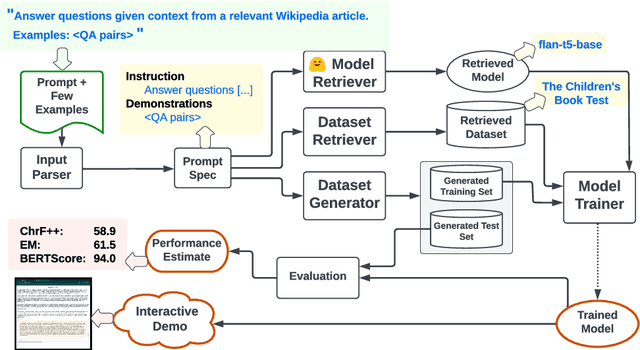

Large language models (LLMs) enable system builders today to create competent NLP systems through prompting, where they only need to describe the task in natural language and provide a few examples. However, in other ways, LLMs are a step backward from traditional special-purpose NLP models; they require extensive computational resources for deployment and can be gated behind APIs. In this paper, we propose Prompt2Model, a general-purpose method that takes a natural language task description like the prompts provided to LLMs, and uses it to train a special-purpose model that is conducive to deployment. This is done through a multi-step process of retrieval of existing datasets and pretrained models, dataset generation using LLMs, and supervised fine-tuning on these retrieved and generated datasets. Over three tasks, we demonstrate that given the same few-shot prompt as input, Prompt2Model trains models that outperform the results of a strong LLM, gpt-3.5-turbo, by an average of 20% while being up to 700 times smaller. We also show that this data can be used to obtain reliable performance estimates of model performance, enabling model developers to assess model reliability before deployment. Prompt2Model is available open-source at https://github.com/neulab/prompt2model.
Large Language Models Enable Few-Shot Clustering
Jul 02, 2023Unlike traditional unsupervised clustering, semi-supervised clustering allows users to provide meaningful structure to the data, which helps the clustering algorithm to match the user's intent. Existing approaches to semi-supervised clustering require a significant amount of feedback from an expert to improve the clusters. In this paper, we ask whether a large language model can amplify an expert's guidance to enable query-efficient, few-shot semi-supervised text clustering. We show that LLMs are surprisingly effective at improving clustering. We explore three stages where LLMs can be incorporated into clustering: before clustering (improving input features), during clustering (by providing constraints to the clusterer), and after clustering (using LLMs post-correction). We find incorporating LLMs in the first two stages can routinely provide significant improvements in cluster quality, and that LLMs enable a user to make trade-offs between cost and accuracy to produce desired clusters. We release our code and LLM prompts for the public to use.