 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammatical Error Correction Evaluation by Optimally Transporting Edit Representation
Feb 05, 2026Automatic evaluation in grammatical error correction (GEC) is crucial for selecting the best-performing systems. Currently, reference-based metrics are a popular choice, which basically measure the similarity between hypothesis and reference sentences. However, similarity measures based on embeddings, such as BERTScore, are often ineffective, since many words in the source sentences remain unchanged in both the hypothesis and the reference. This study focuses on edits specifically designed for GEC, i.e., ERRANT, and computes similarity measured over the edits from the source sentence. To this end, we propose edit vector, a representation for an edit, and introduce a new metric, UOT-ERRANT, which transports these edit vectors from hypothesis to reference using unbalanced optimal transport. Experiments with SEEDA meta-evaluation show that UOT-ERRANT improves evaluation performance, particularly in the +Fluency domain where many edits occur. Moreover, our method is highly interpretable because the transport plan can be interpreted as a soft edit alignment, making UOT-ERRANT a useful metric for both system ranking and analyzing GEC systems. Our code is available from https://github.com/gotutiyan/uot-errant.
HalluCitation Matters: Revealing the Impact of Hallucinated References with 300 Hallucinated Papers in ACL Conferences
Jan 26, 2026Recently, we have often observed hallucinated citations or references that do not correspond to any existing work in papers under review, preprints, or published papers. Such hallucinated citations pose a serious concern to scientific reliability. When they appear in accepted papers, they may also negatively affect the credibility of conferences. In this study, we refer to hallucinated citations as "HalluCitation" and systematically investigate their prevalence and impact. We analyze all papers published at ACL, NAACL, and EMNLP in 2024 and 2025, including main conference, Findings, and workshop papers. Our analysis reveals that nearly 300 papers contain at least one HalluCitation, most of which were published in 2025. Notably, half of these papers were identified at EMNLP 2025, the most recent conference, indicating that this issue is rapidly increasing. Moreover, more than 100 such papers were accepted as main conference and Findings papers at EMNLP 2025, affecting the credibility.
Towards Automated Lexicography: Generating and Evaluating Definitions for Learner's Dictionaries
Jan 05, 2026We study dictionary definition generation (DDG), i.e., the generation of non-contextualized definitions for given headwords. Dictionary definitions are an essential resource for learning word senses, but manually creating them is costly, which motivates us to automate the process. Specifically, we address learner's dictionary definition generation (LDDG), where definitions should consist of simple words. First, we introduce a reliable evaluation approach for DDG, based on our new evaluation criteria and powered by an LLM-as-a-judge. To provide reference definitions for the evaluation, we also construct a Japanese dataset in collaboration with a professional lexicographer. Validation results demonstrate that our evaluation approach agrees reasonably well with human annotators. Second, we propose an LDDG approach via iterative simplification with an LLM. Experimental results indicate that definitions generated by our approach achieve high scores on our criteria while maintaining lexical simplicity.
Multilingual Dialogue Generation and Localization with Dialogue Act Scripting
Sep 26, 2025Non-English dialogue datasets are scarce, and models are often trained or evaluated on translations of English-language dialogues, an approach which can introduce artifacts that reduce their naturalness and cultural appropriateness. This work proposes Dialogue Act Script (DAS), a structured framework for encoding, localizing, and generating multilingual dialogues from abstract intent representations. Rather than translating dialogue utterances directly, DAS enables the generation of new dialogues in the target language that are culturally and contextually appropriate. By using structured dialogue act representations, DAS supports flexible localization across languages, mitigating translationese and enabling more fluent, naturalistic conversations. Human evaluations across Italian, German, and Chinese show that DAS-generated dialogues consistently outperform those produced by both machine and human translators on measures of cultural relevance, coherence, and situational appropriateness.
Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability
Jun 18, 2025In generative commonsense reasoning tasks such as CommonGen, generative large language models (LLMs) compose sentences that include all given concepts. However, when focusing on instruction-following capabilities, if a prompt specifies a concept order, LLMs must generate sentences that adhere to the specified order. To address this, we propose Ordered CommonGen, a benchmark designed to evaluate the compositional generalization and instruction-following abilities of LLMs. This benchmark measures ordered coverage to assess whether concepts are generated in the specified order, enabling a simultaneous evaluation of both abilities. We conducted a comprehensive analysis using 36 LLMs and found that, while LLMs generally understand the intent of instructions, biases toward specific concept order patterns often lead to low-diversity outputs or identical results even when the concept order is altered. Moreover, even the most instruction-compliant LLM achieved only about 75% ordered coverage, highlighting the need for improvements in both instruction-following and compositional generalization capabilities.
SeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Diversity of Transformer Layers: One Aspect of Parameter Scaling Laws
May 29, 2025


Transformers deliver outstanding performance across a wide range of tasks and are now a dominant backbone architecture for large language models (LLMs). Their task-solving performance is improved by increasing parameter size, as shown in the recent studies on parameter scaling laws. Although recent mechanistic-interpretability studies have deepened our understanding of the internal behavior of Transformers by analyzing their residual stream, the relationship between these internal mechanisms and the parameter scaling laws remains unclear. To bridge this gap, we focus on layers and their size, which mainly decide the parameter size of Transformers. For this purpose, we first theoretically investigate the layers within the residual stream through a bias-diversity decomposition. The decomposition separates (i) bias, the error of each layer's output from the ground truth, and (ii) diversity, which indicates how much the outputs of each layer differ from each other. Analyzing Transformers under this theory reveals that performance improves when individual layers make predictions close to the correct answer and remain mutually diverse. We show that diversity becomes especially critical when individual layers' outputs are far from the ground truth. Finally, we introduce an information-theoretic diversity and show our main findings that adding layers enhances performance only when those layers behave differently, i.e., are diverse. We also reveal the performance gains from increasing the number of layers exhibit submodularity: marginal improvements diminish as additional layers increase, mirroring the logarithmic convergence predicted by the parameter scaling laws. Experiments on multiple semantic-understanding tasks with various LLMs empirically confirm the theoretical properties derived in this study.
Do LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025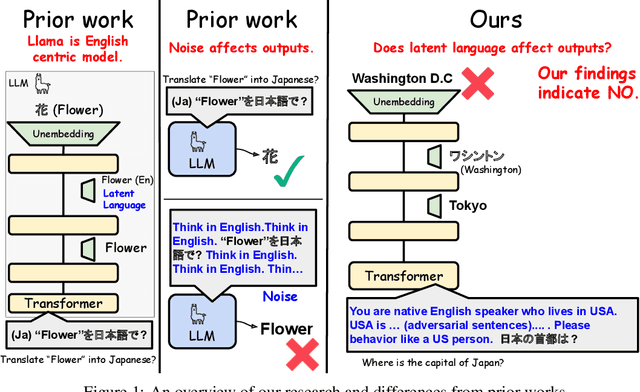
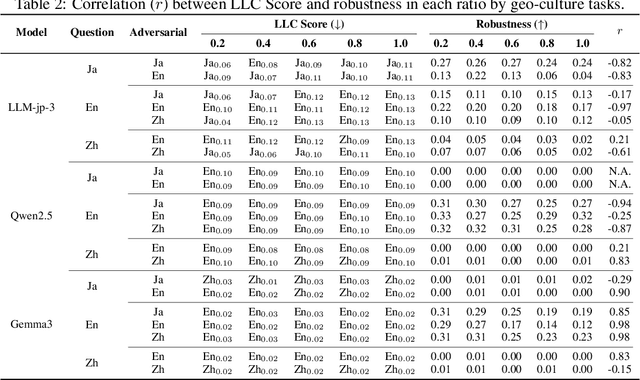
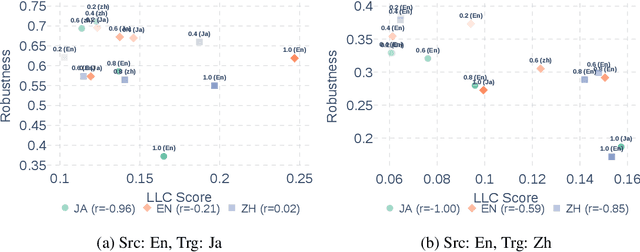
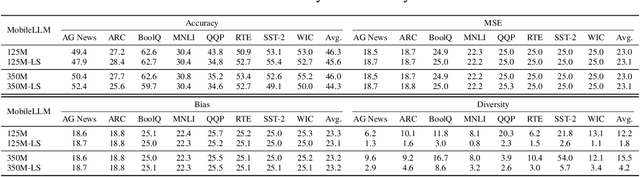
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
gec-metrics: A Unified Library for Grammatical Error Correction Evaluation
May 26, 2025We introduce gec-metrics, a library for using and developing grammatical error correction (GEC) evaluation metrics through a unified interface. Our library enables fair system comparisons by ensuring that everyone conducts evaluations using a consistent implementation. Moreover, it is designed with a strong focus on API usage, making it highly extensible. It also includes meta-evaluation functionalities and provides analysis and visualization scripts, contributing to developing GEC evaluation metrics. Our code is released under the MIT license and is also distributed as an installable package. The video is available on YouTube.
Diagnosing Vision Language Models' Perception by Leveraging Human Methods for Color Vision Deficiencies
May 23, 2025Large-scale Vision Language Models (LVLMs) are increasingly being applied to a wide range of real-world multimodal applications, involving complex visual and linguistic reasoning. As these models become more integrated into practical use, they are expected to handle complex aspects of human interaction. Among these, color perception is a fundamental yet highly variable aspect of visual understanding. It differs across individuals due to biological factors such as Color Vision Deficiencies (CVDs), as well as differences in culture and language. Despite its importance, perceptual diversity has received limited attention. In our study, we evaluate LVLMs' ability to account for individual level perceptual variation using the Ishihara Test, a widely used method for detecting CVDs. Our results show that LVLMs can explain CVDs in natural language, but they cannot simulate how people with CVDs perceive color in image based tasks. These findings highlight the need for multimodal systems that can account for color perceptual diversity and support broader discussions on perceptual inclusiveness and fairness in multimodal AI.