 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Lexicography: Generating and Evaluating Definitions for Learner's Dictionaries
Jan 05, 2026We study dictionary definition generation (DDG), i.e., the generation of non-contextualized definitions for given headwords. Dictionary definitions are an essential resource for learning word senses, but manually creating them is costly, which motivates us to automate the process. Specifically, we address learner's dictionary definition generation (LDDG), where definitions should consist of simple words. First, we introduce a reliable evaluation approach for DDG, based on our new evaluation criteria and powered by an LLM-as-a-judge. To provide reference definitions for the evaluation, we also construct a Japanese dataset in collaboration with a professional lexicographer. Validation results demonstrate that our evaluation approach agrees reasonably well with human annotators. Second, we propose an LDDG approach via iterative simplification with an LLM. Experimental results indicate that definitions generated by our approach achieve high scores on our criteria while maintaining lexical simplicity.
CoAM: Corpus of All-Type Multiword Expressions
Dec 24, 2024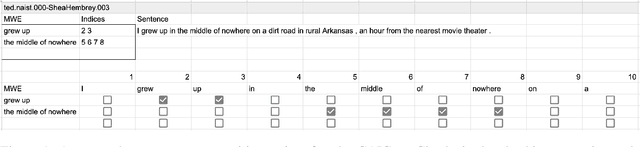
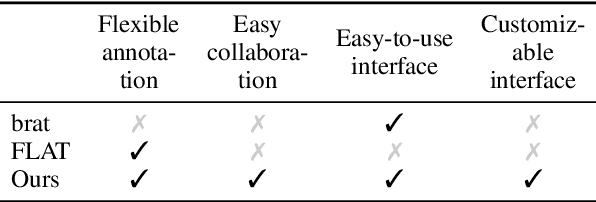


Multiword expressions (MWEs) refer to idiomatic sequences of multiple words. MWE identification, i.e., detecting MWEs in text, can play a key role in downstream tasks such as machine translation. Existing datasets for MWE identification are inconsistently annotated, limited to a single type of MWE, or limited in size. To enable reliable and comprehensive evaluation, we created CoAM: Corpus of All-Type Multiword Expressions, a dataset of 1.3K sentences constructed through a multi-step process to enhance data quality consisting of human annotation, human review, and automated consistency checking. MWEs in CoAM are tagged with MWE types, such as Noun and Verb, to enable fine-grained error analysis. Annotations for CoAM were collected using a new interface created with our interface generator, which allows easy and flexible annotation of MWEs in any form, including discontinuous ones. Through experiments using CoAM, we find that a fine-tuned large language model outperforms the current state-of-the-art approach for MWE identification. Furthermore, analysis using our MWE type tagged data reveals that Verb MWEs are easier than Noun MWEs to identify across approaches.
Context-Informed Machine Translation of Manga using Multimodal Large Language Models
Nov 04, 2024
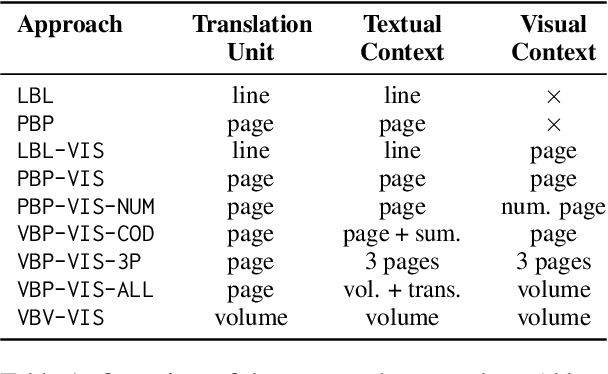

Due to the significant time and effort required for handcrafting translations, most manga never leave the domestic Japanese market. Automatic manga translation is a promising potential solution. However, it is a budding and underdeveloped field and presents complexities even greater than those found in standard translation due to the need to effectively incorporate visual elements into the translation process to resolve ambiguities. In this work, we investigate to what extent multimodal large language models (LLMs) can provide effective manga translation, thereby assisting manga authors and publishers in reaching wider audiences. Specifically, we propose a methodology that leverages the vision component of multimodal LLMs to improve translation quality and evaluate the impact of translation unit size, context length, and propose a token efficient approach for manga translation. Moreover, we introduce a new evaluation dataset -- the first parallel Japanese-Polish manga translation dataset -- as part of a benchmark to be used in future research. Finally, we contribute an open-source software suite, enabling others to benchmark LLMs for manga translation. Our findings demonstrate that our proposed methods achieve state-of-the-art results for Japanese-English translation and set a new standard for Japanese-Polish.
Project MOSLA: Recording Every Moment of Second Language Acquisition
Mar 26, 2024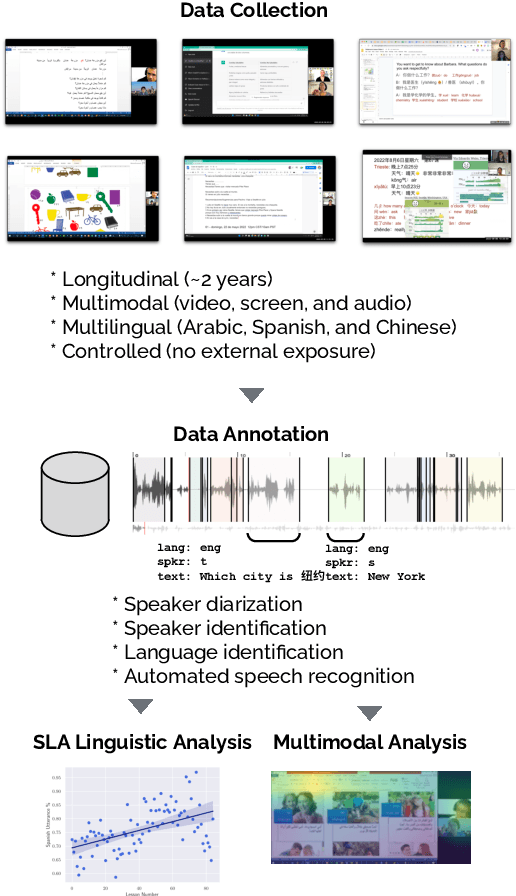
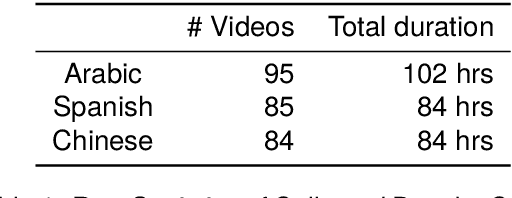


Second language acquisition (SLA) is a complex and dynamic process. Many SLA studies that have attempted to record and analyze this process have typically focused on a single modality (e.g., textual output of learners), covered only a short period of time, and/or lacked control (e.g., failed to capture every aspect of the learning process). In Project MOSLA (Moments of Second Language Acquisition), we have created a longitudinal, multimodal, multilingual, and controlled dataset by inviting participants to learn one of three target languages (Arabic, Spanish, and Chinese) from scratch over a span of two years, exclusively through online instruction, and recording every lesson using Zoom. The dataset is semi-automatically annotated with speaker/language IDs and transcripts by both human annotators and fine-tuned state-of-the-art speech models. Our experiments reveal linguistic insights into learners' proficiency development over time, as well as the potential for automatically detecting the areas of focus on the screen purely from the unannotated multimodal data. Our dataset is freely available for research purposes and can serve as a valuable resource for a wide range of applications, including but not limited to SLA, proficiency assessment, language and speech processing, pedagogy, and multimodal learning analytics.
MWE as WSD: Solving Multiword Expression Identification with Word Sense Disambiguation
Mar 12, 2023Recent work in word sense disambiguation (WSD) utilizes encodings of the sense gloss (definition text), in addition to the input words and context, to improve performance. In this work we demonstrate that this approach can be adapted for use in multiword expression (MWE) identification by training a Bi-encoder model which uses gloss and context information to filter MWE candidates produced from a simple rule-based extraction pipeline. We achieve state-of-the-art results in MWE identification on the DiMSUM dataset, and competitive results on the PARSEME 1.1 English dataset using this method. Our model also retains most of its ability to perform WSD, demonstrating that a single model can successfully be applied to both of these tasks. Additionally, we experiment with applying Poly-encoder models to MWE identification and WSD, introducing a modified Poly-encoder architecture which outperforms the standard Poly-encoder on these tasks.
GrammarTagger: A Multilingual, Minimally-Supervised Grammar Profiler for Language Education
Apr 07, 2021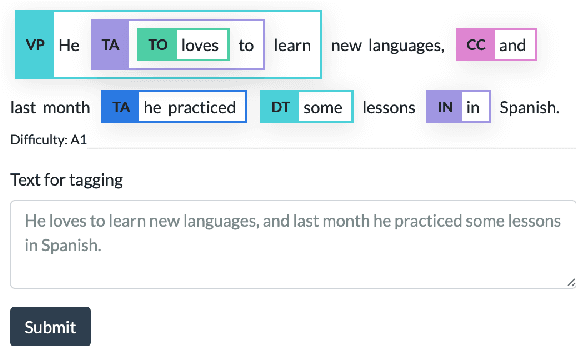


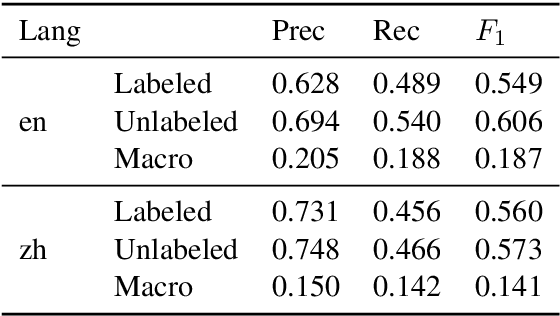
We present GrammarTagger, an open-source grammar profiler which, given an input text, identifies grammatical features useful for language education. The model architecture enables it to learn from a small amount of texts annotated with spans and their labels, which 1) enables easier and more intuitive annotation, 2) supports overlapping spans, and 3) is less prone to error propagation, compared to complex hand-crafted rules defined on constituency/dependency parses. We show that we can bootstrap a grammar profiler model with $F_1 \approx 0.6$ from only a couple hundred sentences both in English and Chinese, which can be further boosted via learning a multilingual model. With GrammarTagger, we also build Octanove Learn, a search engine of language learning materials indexed by their reading difficulty and grammatical features. The code and pretrained models are publicly available at \url{https://github.com/octanove/grammartagger}.