 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Informed Machine Translation of Manga using Multimodal Large Language Models
Nov 04, 2024
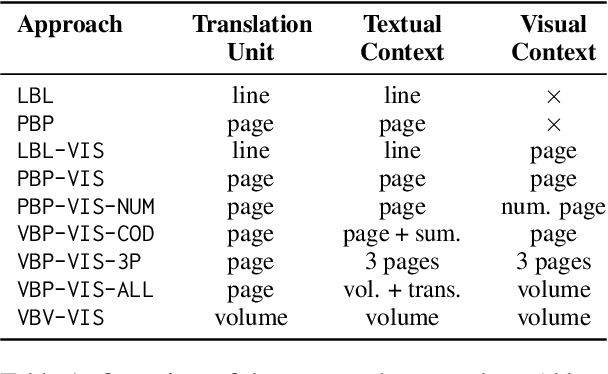

Due to the significant time and effort required for handcrafting translations, most manga never leave the domestic Japanese market. Automatic manga translation is a promising potential solution. However, it is a budding and underdeveloped field and presents complexities even greater than those found in standard translation due to the need to effectively incorporate visual elements into the translation process to resolve ambiguities. In this work, we investigate to what extent multimodal large language models (LLMs) can provide effective manga translation, thereby assisting manga authors and publishers in reaching wider audiences. Specifically, we propose a methodology that leverages the vision component of multimodal LLMs to improve translation quality and evaluate the impact of translation unit size, context length, and propose a token efficient approach for manga translation. Moreover, we introduce a new evaluation dataset -- the first parallel Japanese-Polish manga translation dataset -- as part of a benchmark to be used in future research. Finally, we contribute an open-source software suite, enabling others to benchmark LLMs for manga translation. Our findings demonstrate that our proposed methods achieve state-of-the-art results for Japanese-English translation and set a new standard for Japanese-Polish.
Red Teaming for Large Language Models At Scale: Tackling Hallucinations on Mathematics Tasks
Dec 30, 2023We consider the problem of red teaming LLMs on elementary calculations and algebraic tasks to evaluate how various prompting techniques affect the quality of outputs. We present a framework to procedurally generate numerical questions and puzzles, and compare the results with and without the application of several red teaming techniques. Our findings suggest that even though structured reasoning and providing worked-out examples slow down the deterioration of the quality of answers, the gpt-3.5-turbo and gpt-4 models are not well suited for elementary calculations and reasoning tasks, also when being red teamed.