 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Informed Machine Translation of Manga using Multimodal Large Language Models
Nov 04, 2024
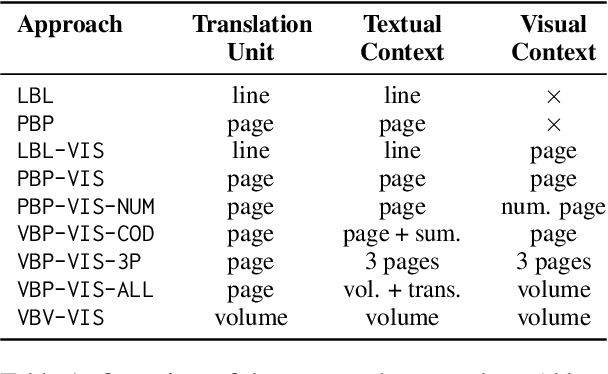

Due to the significant time and effort required for handcrafting translations, most manga never leave the domestic Japanese market. Automatic manga translation is a promising potential solution. However, it is a budding and underdeveloped field and presents complexities even greater than those found in standard translation due to the need to effectively incorporate visual elements into the translation process to resolve ambiguities. In this work, we investigate to what extent multimodal large language models (LLMs) can provide effective manga translation, thereby assisting manga authors and publishers in reaching wider audiences. Specifically, we propose a methodology that leverages the vision component of multimodal LLMs to improve translation quality and evaluate the impact of translation unit size, context length, and propose a token efficient approach for manga translation. Moreover, we introduce a new evaluation dataset -- the first parallel Japanese-Polish manga translation dataset -- as part of a benchmark to be used in future research. Finally, we contribute an open-source software suite, enabling others to benchmark LLMs for manga translation. Our findings demonstrate that our proposed methods achieve state-of-the-art results for Japanese-English translation and set a new standard for Japanese-Polish.
Painting Style-Aware Manga Colorization Based on Generative Adversarial Networks
Jul 16, 2021
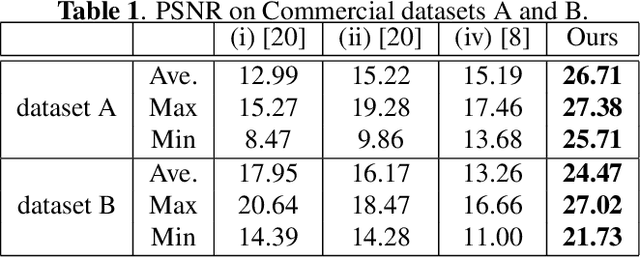
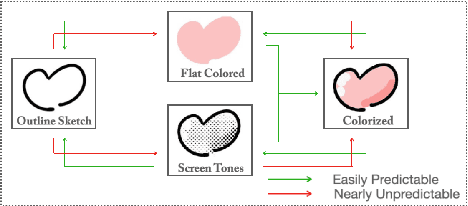
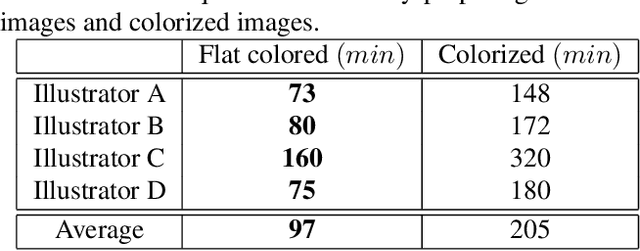
Japanese comics (called manga) are traditionally created in monochrome format. In recent years, in addition to monochrome comics, full color comics, a more attractive medium, have appeared. Unfortunately, color comics require manual colorization, which incurs high labor costs. Although automatic colorization methods have been recently proposed, most of them are designed for illustrations, not for comics. Unlike illustrations, since comics are composed of many consecutive images, the painting style must be consistent. To realize consistent colorization, we propose here a semi-automatic colorization method based on generative adversarial networks (GAN); the method learns the painting style of a specific comic from small amount of training data. The proposed method takes a pair of a screen tone image and a flat colored image as input, and outputs a colorized image. Experiments show that the proposed method achieves better performance than the existing alternatives.
Towards Fully Automated Manga Translation
Jan 09, 2021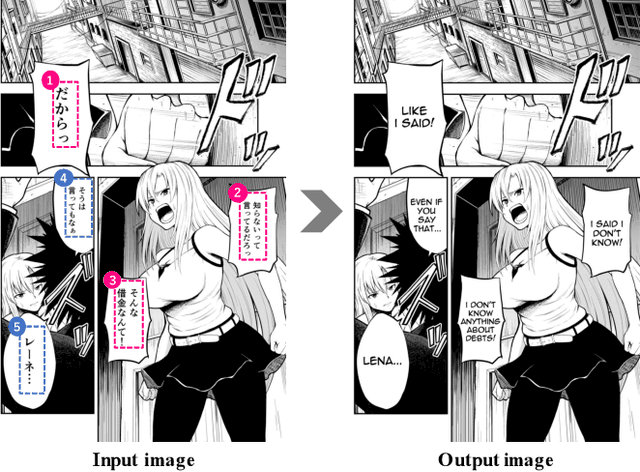
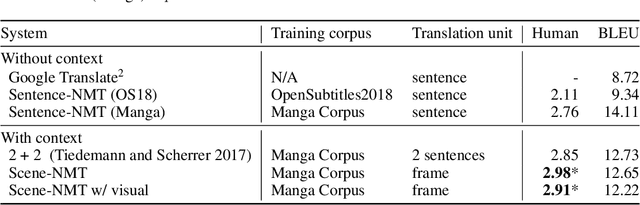
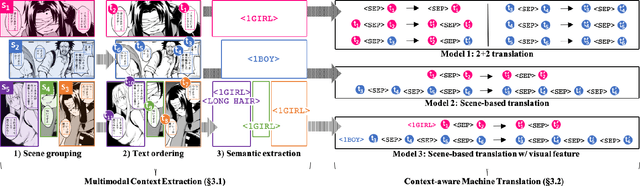
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.
Learning to Describe Phrases with Local and Global Contexts
Nov 01, 2018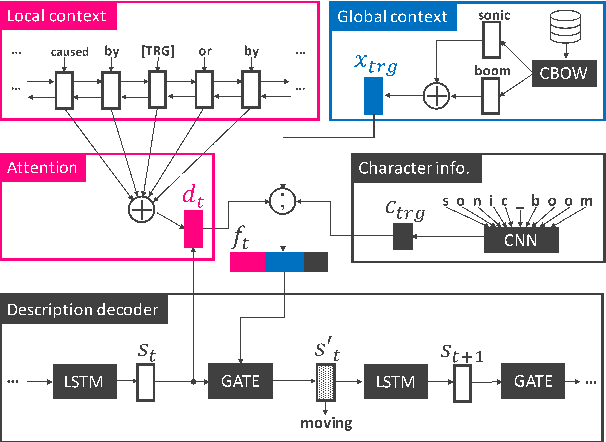
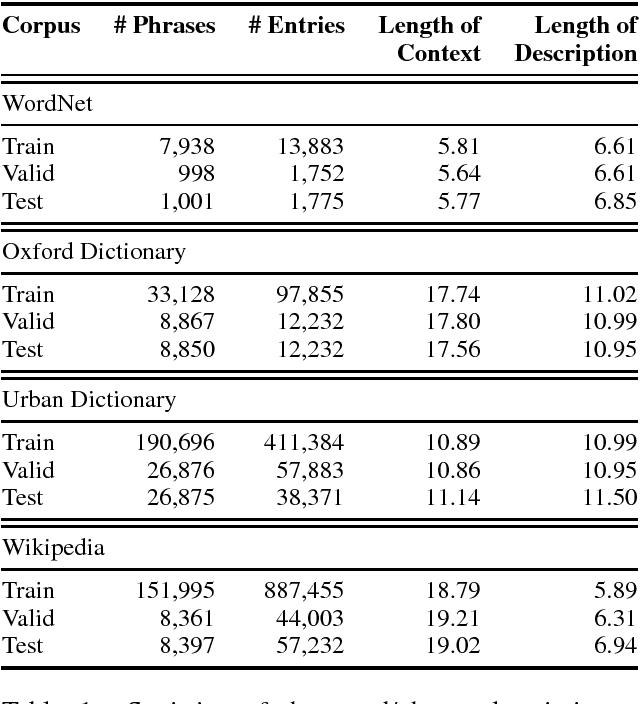

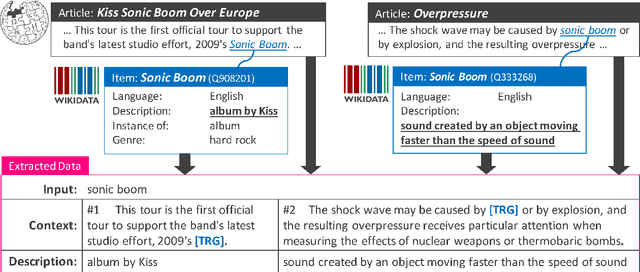
When reading a text, it is common to become stuck on unfamiliar words and phrases, such as polysemous words with novel senses, rarely used idioms, Internet slang, or emerging entities. At first, we attempt to figure out the meaning of those expressions from their context, and ultimately we may consult a dictionary for their definitions. However, rarely-used senses or emerging entities are not always covered by the hand-crafted definitions in existing dictionaries, which can cause problems in text comprehension. This paper undertakes a task of describing (or defining) a given expression (word or phrase) based on its usage contexts, and presents a novel neural-network generator for expressing its meaning as a natural language description. Experimental results on four datasets (including WordNet, Oxford and Urban Dictionaries, non-standard English, and Wikipedia) demonstrate the effectiveness of our method over previous methods for definition generation[Noraset+17; Gadetsky+18; Ni+17].