 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Learned Count-Min Sketch
Dec 13, 2025Count-Min Sketch (CMS) is a memory-efficient data structure for estimating the frequency of elements in a multiset. Learned Count-Min Sketch (LCMS) enhances CMS with a machine learning model to reduce estimation error under the same memory usage, but suffers from slow construction due to empirical parameter tuning and lacks theoretical guarantees on intolerable error probability. We propose Optimized Learned Count-Min Sketch (OptLCMS), which partitions the input domain and assigns each partition to its own CMS instance, with CMS parameters analytically derived for fixed thresholds, and thresholds optimized via dynamic programming with approximate feasibility checks. This reduces the need for empirical validation, enabling faster construction while providing theoretical guarantees under these assumptions. OptLCMS also allows explicit control of the allowable error threshold, improving flexibility in practice. Experiments show that OptLCMS builds faster, achieves lower intolerable error probability, and matches the estimation accuracy of LCMS.
Region-Wise Correspondence Prediction between Manga Line Art Images
Sep 11, 2025



Understanding region-wise correspondence between manga line art images is a fundamental task in manga processing, enabling downstream applications such as automatic line art colorization and in-between frame generation. However, this task remains largely unexplored, especially in realistic scenarios without pre-existing segmentation or annotations. In this paper, we introduce a novel and practical task: predicting region-wise correspondence between raw manga line art images without any pre-existing labels or masks. To tackle this problem, we divide each line art image into a set of patches and propose a Transformer-based framework that learns patch-level similarities within and across images. We then apply edge-aware clustering and a region matching algorithm to convert patch-level predictions into coherent region-level correspondences. To support training and evaluation, we develop an automatic annotation pipeline and manually refine a subset of the data to construct benchmark datasets. Experiments on multiple datasets demonstrate that our method achieves high patch-level accuracy (e.g., 96.34%) and generates consistent region-level correspondences, highlighting its potential for real-world manga applications.
Noisy Label Refinement with Semantically Reliable Synthetic Images
Sep 04, 2025Semantic noise in image classification datasets, where visually similar categories are frequently mislabeled, poses a significant challenge to conventional supervised learning approaches. In this paper, we explore the potential of using synthetic images generated by advanced text-to-image models to address this issue. Although these high-quality synthetic images come with reliable labels, their direct application in training is limited by domain gaps and diversity constraints. Unlike conventional approaches, we propose a novel method that leverages synthetic images as reliable reference points to identify and correct mislabeled samples in noisy datasets. Extensive experiments across multiple benchmark datasets show that our approach significantly improves classification accuracy under various noise conditions, especially in challenging scenarios with semantic label noise. Additionally, since our method is orthogonal to existing noise-robust learning techniques, when combined with state-of-the-art noise-robust training methods, it achieves superior performance, improving accuracy by 30% on CIFAR-10 and by 11% on CIFAR-100 under 70% semantic noise, and by 24% on ImageNet-100 under real-world noise conditions.
LotusFilter: Fast Diverse Nearest Neighbor Search via a Learned Cutoff Table
Jun 05, 2025Approximate nearest neighbor search (ANNS) is an essential building block for applications like RAG but can sometimes yield results that are overly similar to each other. In certain scenarios, search results should be similar to the query and yet diverse. We propose LotusFilter, a post-processing module to diversify ANNS results. We precompute a cutoff table summarizing vectors that are close to each other. During the filtering, LotusFilter greedily looks up the table to delete redundant vectors from the candidates. We demonstrated that the LotusFilter operates fast (0.02 [ms/query]) in settings resembling real-world RAG applications, utilizing features such as OpenAI embeddings. Our code is publicly available at https://github.com/matsui528/lotf.
Cascaded Learned Bloom Filter for Optimal Model-Filter Size Balance and Fast Rejection
Feb 06, 2025
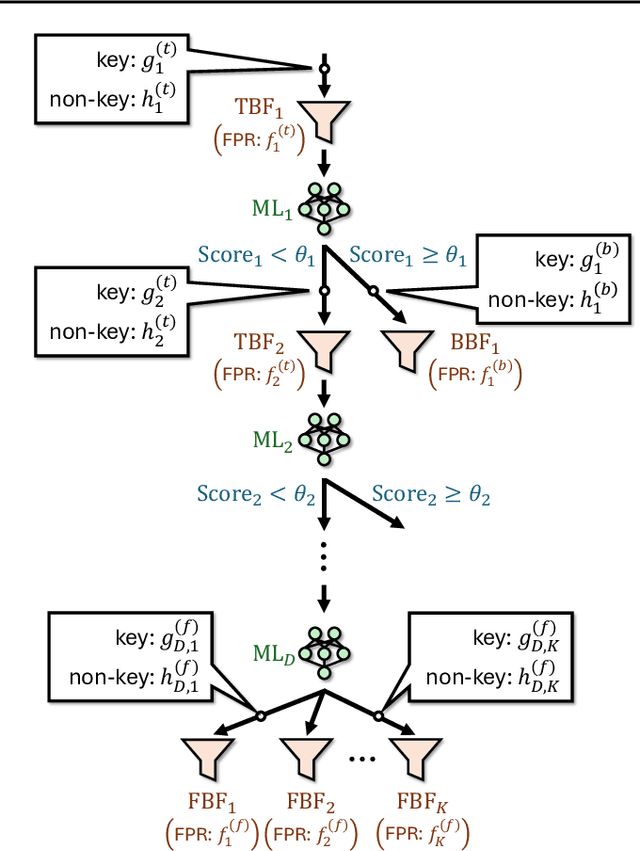

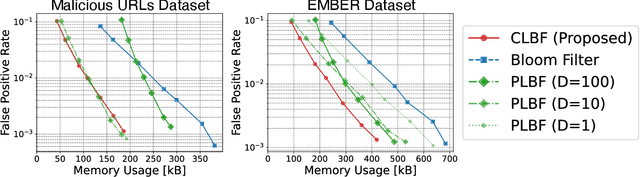
Recent studies have demonstrated that learned Bloom filters, which combine machine learning with the classical Bloom filter, can achieve superior memory efficiency. However, existing learned Bloom filters face two critical unresolved challenges: the balance between the machine learning model size and the Bloom filter size is not optimal, and the reject time cannot be minimized effectively. We propose the Cascaded Learned Bloom Filter (CLBF) to address these issues. Our dynamic programming-based optimization automatically selects configurations that achieve an optimal balance between the model and filter sizes while minimizing reject time. Experiments on real-world datasets show that CLBF reduces memory usage by up to 24% and decreases reject time by up to 14 times compared to state-of-the-art learned Bloom filters.
Broadcast Product: Shape-aligned Element-wise Multiplication and Beyond
Sep 26, 2024



We propose a new operator defined between two tensors, the broadcast product. The broadcast product calculates the Hadamard product after duplicating elements to align the shapes of the two tensors. Complex tensor operations in libraries like \texttt{numpy} can be succinctly represented as mathematical expressions using the broadcast product. Finally, we propose a novel tensor decomposition using the broadcast product, highlighting its potential applications in dimensionality reduction.
High-Frequency Anti-DreamBooth: Robust Defense Against Image Synthesis
Sep 12, 2024



Recently, text-to-image generative models have been misused to create unauthorized malicious images of individuals, posing a growing social problem. Previous solutions, such as Anti-DreamBooth, add adversarial noise to images to protect them from being used as training data for malicious generation. However, we found that the adversarial noise can be removed by adversarial purification methods such as DiffPure. Therefore, we propose a new adversarial attack method that adds strong perturbation on the high-frequency areas of images to make it more robust to adversarial purification. Our experiment showed that the adversarial images retained noise even after adversarial purification, hindering malicious image generation.
Revisiting Relevance Feedback for CLIP-based Interactive Image Retrieval
Apr 29, 2024Many image retrieval studies use metric learning to train an image encoder. However, metric learning cannot handle differences in users' preferences, and requires data to train an image encoder. To overcome these limitations, we revisit relevance feedback, a classic technique for interactive retrieval systems, and propose an interactive CLIP-based image retrieval system with relevance feedback. Our retrieval system first executes the retrieval, collects each user's unique preferences through binary feedback, and returns images the user prefers. Even when users have various preferences, our retrieval system learns each user's preference through the feedback and adapts to the preference. Moreover, our retrieval system leverages CLIP's zero-shot transferability and achieves high accuracy without training. We empirically show that our retrieval system competes well with state-of-the-art metric learning in category-based image retrieval, despite not training image encoders specifically for each dataset. Furthermore, we set up two additional experimental settings where users have various preferences: one-label-based image retrieval and conditioned image retrieval. In both cases, our retrieval system effectively adapts to each user's preferences, resulting in improved accuracy compared to image retrieval without feedback. Overall, our work highlights the potential benefits of integrating CLIP with classic relevance feedback techniques to enhance image retrieval.
Zero-Shot Character Identification and Speaker Prediction in Comics via Iterative Multimodal Fusion
Apr 24, 2024Recognizing characters and predicting speakers of dialogue are critical for comic processing tasks, such as voice generation or translation. However, because characters vary by comic title, supervised learning approaches like training character classifiers which require specific annotations for each comic title are infeasible. This motivates us to propose a novel zero-shot approach, allowing machines to identify characters and predict speaker names based solely on unannotated comic images. In spite of their importance in real-world applications, these task have largely remained unexplored due to challenges in story comprehension and multimodal integration. Recent large language models (LLMs) have shown great capability for text understanding and reasoning, while their application to multimodal content analysis is still an open problem. To address this problem, we propose an iterative multimodal framework, the first to employ multimodal information for both character identification and speaker prediction tasks. Our experiments demonstrate the effectiveness of the proposed framework, establishing a robust baseline for these tasks. Furthermore, since our method requires no training data or annotations, it can be used as-is on any comic series.
SVGEditBench: A Benchmark Dataset for Quantitative Assessment of LLM's SVG Editing Capabilities
Apr 21, 2024
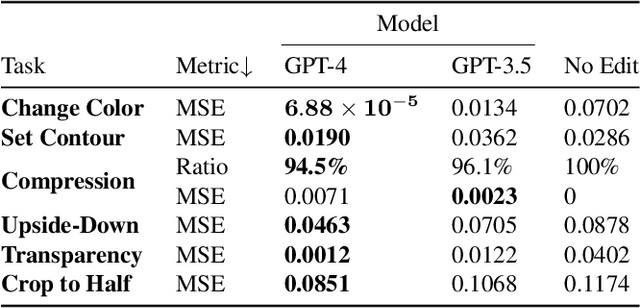
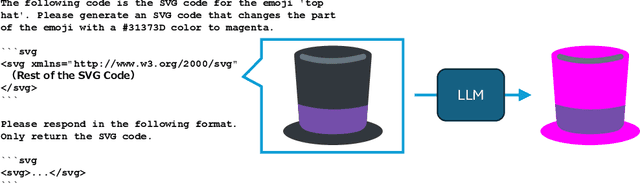

Text-to-image models have shown progress in recent years. Along with this progress, generating vector graphics from text has also advanced. SVG is a popular format for vector graphics, and SVG represents a scene with XML text. Therefore, Large Language Models can directly process SVG code. Taking this into account, we focused on editing SVG with LLMs. For quantitative evaluation of LLMs' ability to edit SVG, we propose SVGEditBench. SVGEditBench is a benchmark for assessing the LLMs' ability to edit SVG code. We also show the GPT-4 and GPT-3.5 results when evaluated on the proposed benchmark. In the experiments, GPT-4 showed superior performance to GPT-3.5 both quantitatively and qualitatively. The dataset is available at https://github.com/mti-lab/SVGEditBench.