 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJMMMU-Pro: Image-based Japanese Multi-discipline Multimodal Understanding Benchmark via Vibe Benchmark Construction
Dec 16, 2025This paper introduces JMMMU-Pro, an image-based Japanese Multi-discipline Multimodal Understanding Benchmark, and Vibe Benchmark Construction, a scalable construction method. Following the evolution from MMMU to MMMU-Pro, JMMMU-Pro extends JMMMU by composing the question image and question text into a single image, thereby creating a benchmark that requires integrated visual-textual understanding through visual perception. To build JMMMU-Pro, we propose Vibe Benchmark Construction, a methodology in which an image generative model (e.g., Nano Banana Pro) produces candidate visual questions, and humans verify the outputs and, when necessary, regenerate with adjusted prompts to ensure quality. By leveraging Nano Banana Pro's highly realistic image generation capabilities and its ability to embed clean Japanese text, we construct a high-quality benchmark at low cost, covering a wide range of background and layout designs. Experimental results show that all open-source LMMs struggle substantially with JMMMU-Pro, underscoring JMMMU-Pro as an important benchmark for guiding future efforts in the open-source community. We believe that JMMMU-Pro provides a more rigorous evaluation tool for assessing the Japanese capabilities of LMMs and that our Vibe Benchmark Construction also offers an efficient guideline for future development of image-based VQA benchmarks.
MangaVQA and MangaLMM: A Benchmark and Specialized Model for Multimodal Manga Understanding
May 26, 2025Manga, or Japanese comics, is a richly multimodal narrative form that blends images and text in complex ways. Teaching large multimodal models (LMMs) to understand such narratives at a human-like level could help manga creators reflect on and refine their stories. To this end, we introduce two benchmarks for multimodal manga understanding: MangaOCR, which targets in-page text recognition, and MangaVQA, a novel benchmark designed to evaluate contextual understanding through visual question answering. MangaVQA consists of 526 high-quality, manually constructed question-answer pairs, enabling reliable evaluation across diverse narrative and visual scenarios. Building on these benchmarks, we develop MangaLMM, a manga-specialized model finetuned from the open-source LMM Qwen2.5-VL to jointly handle both tasks. Through extensive experiments, including comparisons with proprietary models such as GPT-4o and Gemini 2.5, we assess how well LMMs understand manga. Our benchmark and model provide a comprehensive foundation for evaluating and advancing LMMs in the richly narrative domain of manga.
Toward Responsible Federated Large Language Models: Leveraging a Safety Filter and Constitutional AI
Feb 23, 2025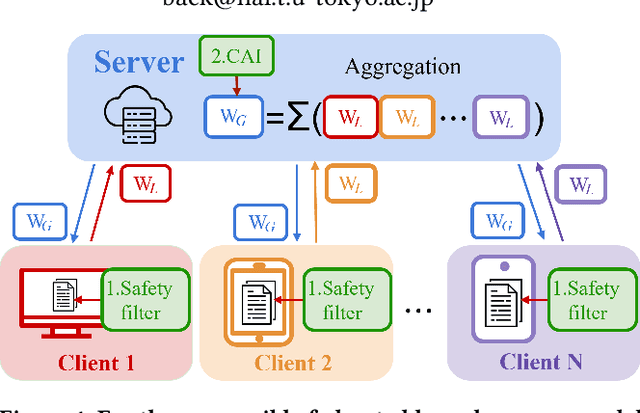
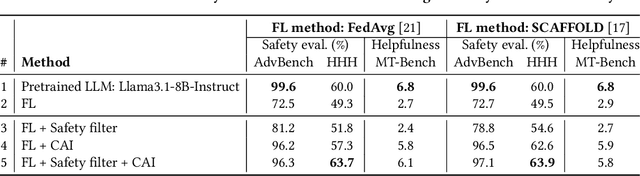
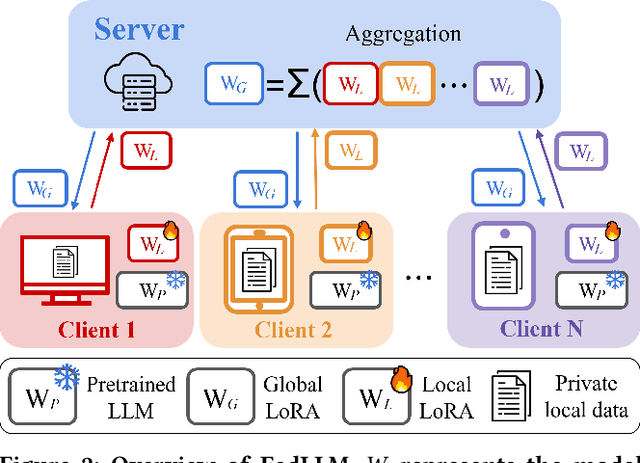

Recent research has increasingly focused on training large language models (LLMs) using federated learning, known as FedLLM. However, responsible AI (RAI), which aims to ensure safe responses, remains underexplored in the context of FedLLM. In FedLLM, client data used for training may contain harmful content, leading to unsafe LLMs that generate harmful responses. Aggregating such unsafe LLMs into the global model and distributing them to clients may result in the widespread deployment of unsafe LLMs. To address this issue, we incorporate two well-known RAI methods into FedLLM: the safety filter and constitutional AI. Our experiments demonstrate that these methods significantly enhance the safety of the LLM, achieving over a 20% improvement on AdvBench, a benchmark for evaluating safety performance.
Harnessing PDF Data for Improving Japanese Large Multimodal Models
Feb 20, 2025

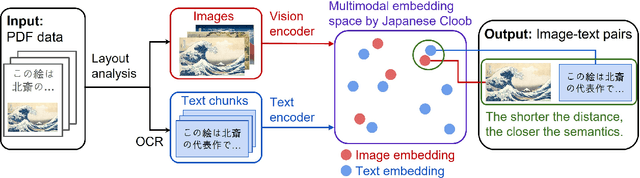

Large Multimodal Models (LMMs) have demonstrated strong performance in English, but their effectiveness in Japanese remains limited due to the lack of high-quality training data. Current Japanese LMMs often rely on translated English datasets, restricting their ability to capture Japan-specific cultural knowledge. To address this, we explore the potential of Japanese PDF data as a training resource, an area that remains largely underutilized. We introduce a fully automated pipeline that leverages pretrained models to extract image-text pairs from PDFs through layout analysis, OCR, and vision-language pairing, removing the need for manual annotation. Additionally, we construct instruction data from extracted image-text pairs to enrich the training data. To evaluate the effectiveness of PDF-derived data, we train Japanese LMMs and assess their performance on the Japanese LMM Benchmark. Our results demonstrate substantial improvements, with performance gains ranging from 3.9% to 13.8% on Heron-Bench. Further analysis highlights the impact of PDF-derived data on various factors, such as model size and language models, reinforcing its value as a multimodal resource for Japanese LMMs. We plan to make the source code and data publicly available upon acceptance.
JMMMU: A Japanese Massive Multi-discipline Multimodal Understanding Benchmark for Culture-aware Evaluation
Oct 22, 2024



Accelerating research on Large Multimodal Models (LMMs) in non-English languages is crucial for enhancing user experiences across broader populations. In this paper, we introduce JMMMU (Japanese MMMU), the first large-scale Japanese benchmark designed to evaluate LMMs on expert-level tasks based on the Japanese cultural context. To facilitate comprehensive culture-aware evaluation, JMMMU features two complementary subsets: (i) culture-agnostic (CA) subset, where the culture-independent subjects (e.g., Math) are selected and translated into Japanese, enabling one-to-one comparison with its English counterpart MMMU; and (ii) culture-specific (CS) subset, comprising newly crafted subjects that reflect Japanese cultural context. Using the CA subset, we observe performance drop in many LMMs when evaluated in Japanese, which is purely attributable to language variation. Using the CS subset, we reveal their inadequate Japanese cultural understanding. Further, by combining both subsets, we identify that some LMMs perform well on the CA subset but not on the CS subset, exposing a shallow understanding of the Japanese language that lacks depth in cultural understanding. We hope this work will not only help advance LMM performance in Japanese but also serve as a guideline to create high-standard, culturally diverse benchmarks for multilingual LMM development. The project page is https://mmmu-japanese-benchmark.github.io/JMMMU/.
Cross-Lingual Learning in Multilingual Scene Text Recognition
Dec 17, 2023



In this paper, we investigate cross-lingual learning (CLL) for multilingual scene text recognition (STR). CLL transfers knowledge from one language to another. We aim to find the condition that exploits knowledge from high-resource languages for improving performance in low-resource languages. To do so, we first examine if two general insights about CLL discussed in previous works are applied to multilingual STR: (1) Joint learning with high- and low-resource languages may reduce performance on low-resource languages, and (2) CLL works best between typologically similar languages. Through extensive experiments, we show that two general insights may not be applied to multilingual STR. After that, we show that the crucial condition for CLL is the dataset size of high-resource languages regardless of the kind of high-resource languages. Our code, data, and models are available at https://github.com/ku21fan/CLL-STR.
COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts
Jul 11, 2022



Recognizing irregular texts has been a challenging topic in text recognition. To encourage research on this topic, we provide a novel comic onomatopoeia dataset (COO), which consists of onomatopoeia texts in Japanese comics. COO has many arbitrary texts, such as extremely curved, partially shrunk texts, or arbitrarily placed texts. Furthermore, some texts are separated into several parts. Each part is a truncated text and is not meaningful by itself. These parts should be linked to represent the intended meaning. Thus, we propose a novel task that predicts the link between truncated texts. We conduct three tasks to detect the onomatopoeia region and capture its intended meaning: text detection, text recognition, and link prediction. Through extensive experiments, we analyze the characteristics of the COO. Our data and code are available at \url{https://github.com/ku21fan/COO-Comic-Onomatopoeia}.
What If We Only Use Real Datasets for Scene Text Recognition? Toward Scene Text Recognition With Fewer Labels
Mar 07, 2021



Scene text recognition (STR) task has a common practice: All state-of-the-art STR models are trained on large synthetic data. In contrast to this practice, training STR models only on fewer real labels (STR with fewer labels) is important when we have to train STR models without synthetic data: for handwritten or artistic texts that are difficult to generate synthetically and for languages other than English for which we do not always have synthetic data. However, there has been implicit common knowledge that training STR models on real data is nearly impossible because real data is insufficient. We consider that this common knowledge has obstructed the study of STR with fewer labels. In this work, we would like to reactivate STR with fewer labels by disproving the common knowledge. We consolidate recently accumulated public real data and show that we can train STR models satisfactorily only with real labeled data. Subsequently, we find simple data augmentation to fully exploit real data. Furthermore, we improve the models by collecting unlabeled data and introducing semi- and self-supervised methods. As a result, we obtain a competitive model to state-of-the-art methods. To the best of our knowledge, this is the first study that 1) shows sufficient performance by only using real labels and 2) introduces semi- and self-supervised methods into STR with fewer labels. Our code and data are available: https://github.com/ku21fan/STR-Fewer-Labels
Character Region Attention For Text Spotting
Jul 19, 2020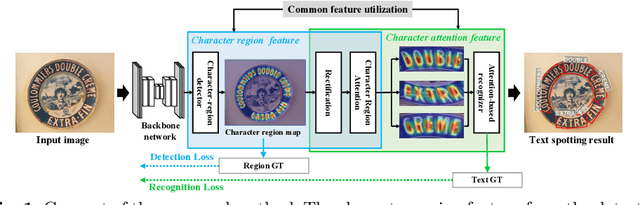

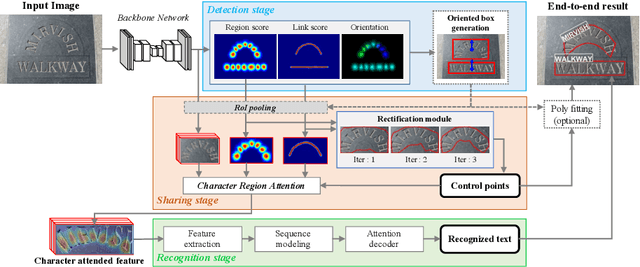
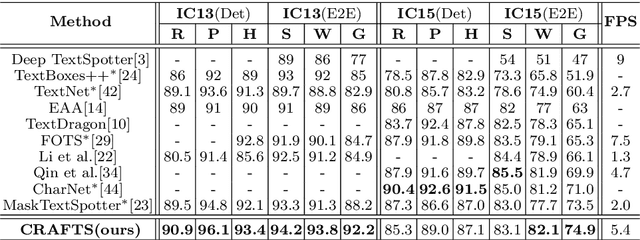
A scene text spotter is composed of text detection and recognition modules. Many studies have been conducted to unify these modules into an end-to-end trainable model to achieve better performance. A typical architecture places detection and recognition modules into separate branches, and a RoI pooling is commonly used to let the branches share a visual feature. However, there still exists a chance of establishing a more complimentary connection between the modules when adopting recognizer that uses attention-based decoder and detector that represents spatial information of the character regions. This is possible since the two modules share a common sub-task which is to find the location of the character regions. Based on the insight, we construct a tightly coupled single pipeline model. This architecture is formed by utilizing detection outputs in the recognizer and propagating the recognition loss through the detection stage. The use of character score map helps the recognizer attend better to the character center points, and the recognition loss propagation to the detector module enhances the localization of the character regions. Also, a strengthened sharing stage allows feature rectification and boundary localization of arbitrary-shaped text regions. Extensive experiments demonstrate state-of-the-art performance in publicly available straight and curved benchmark dataset.
CLEval: Character-Level Evaluation for Text Detection and Recognition Tasks
Jun 11, 2020



Despite the recent success of text detection and recognition methods, existing evaluation metrics fail to provide a fair and reliable comparison among those methods. In addition, there exists no end-to-end evaluation metric that takes characteristics of OCR tasks into account. Previous end-to-end metric contains cascaded errors from the binary scoring process applied in both detection and recognition tasks. Ignoring partially correct results raises a gap between quantitative and qualitative analysis, and prevents fine-grained assessment. Based on the fact that character is a key element of text, we hereby propose a Character-Level Evaluation metric (CLEval). In CLEval, the \textit{instance matching} process handles split and merge detection cases, and the \textit{scoring process} conducts character-level evaluation. By aggregating character-level scores, the CLEval metric provides a fine-grained evaluation of end-to-end results composed of the detection and recognition as well as individual evaluations for each module from the end-performance perspective. We believe that our metrics can play a key role in developing and analyzing state-of-the-art text detection and recognition methods. The evaluation code is publicly available at https://github.com/clovaai/CLEval.