 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCam: Low-Power Onboard Computer Vision for IoT Cameras
Jan 17, 2025We present HyperCam, an energy-efficient image classification pipeline that enables computer vision tasks onboard low-power IoT camera systems. HyperCam leverages hyperdimensional computing to perform training and inference efficiently on low-power microcontrollers. We implement a low-power wireless camera platform using off-the-shelf hardware and demonstrate that HyperCam can achieve an accuracy of 93.60%, 84.06%, 92.98%, and 72.79% for MNIST, Fashion-MNIST, Face Detection, and Face Identification tasks, respectively, while significantly outperforming other classifiers in resource efficiency. Specifically, it delivers inference latency of 0.08-0.27s while using 42.91-63.00KB flash memory and 22.25KB RAM at peak. Among other machine learning classifiers such as SVM, xgBoost, MicroNets, MobileNetV3, and MCUNetV3, HyperCam is the only classifier that achieves competitive accuracy while maintaining competitive memory footprint and inference latency that meets the resource requirements of low-power camera systems.
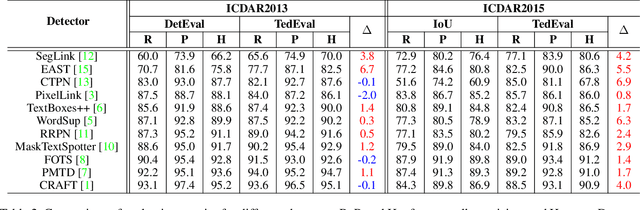
CLEval: Character-Level Evaluation for Text Detection and Recognition Tasks
Jun 11, 2020



Despite the recent success of text detection and recognition methods, existing evaluation metrics fail to provide a fair and reliable comparison among those methods. In addition, there exists no end-to-end evaluation metric that takes characteristics of OCR tasks into account. Previous end-to-end metric contains cascaded errors from the binary scoring process applied in both detection and recognition tasks. Ignoring partially correct results raises a gap between quantitative and qualitative analysis, and prevents fine-grained assessment. Based on the fact that character is a key element of text, we hereby propose a Character-Level Evaluation metric (CLEval). In CLEval, the \textit{instance matching} process handles split and merge detection cases, and the \textit{scoring process} conducts character-level evaluation. By aggregating character-level scores, the CLEval metric provides a fine-grained evaluation of end-to-end results composed of the detection and recognition as well as individual evaluations for each module from the end-performance perspective. We believe that our metrics can play a key role in developing and analyzing state-of-the-art text detection and recognition methods. The evaluation code is publicly available at https://github.com/clovaai/CLEval.
TedEval: A Fair Evaluation Metric for Scene Text Detectors
Jul 02, 2019

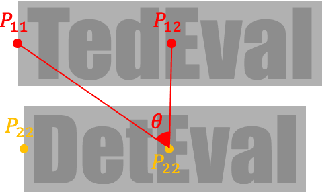
Despite the recent success of scene text detection methods, common evaluation metrics fail to provide a fair and reliable comparison among detectors. They have obvious drawbacks in reflecting the inherent characteristic of text detection tasks, unable to address issues such as granularity, multiline, and character incompleteness. In this paper, we propose a novel evaluation protocol called TedEval (Text detector Evaluation), which evaluates text detections by an instance-level matching and a character-level scoring. Based on a firm standard rewarding behaviors that result in successful recognition, TedEval can act as a reliable standard for comparing and quantizing the detection quality throughout all difficulty levels. In this regard, we believe that TedEval can play a key role in developing state-of-the-art scene text detectors. The code is publicly available at https://github.com/clovaai/TedEval.
Conditional WaveGAN
Sep 27, 2018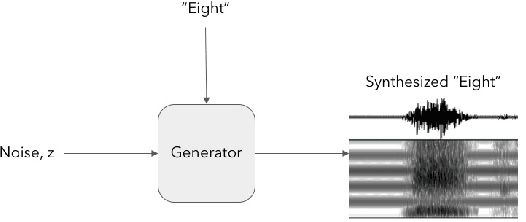

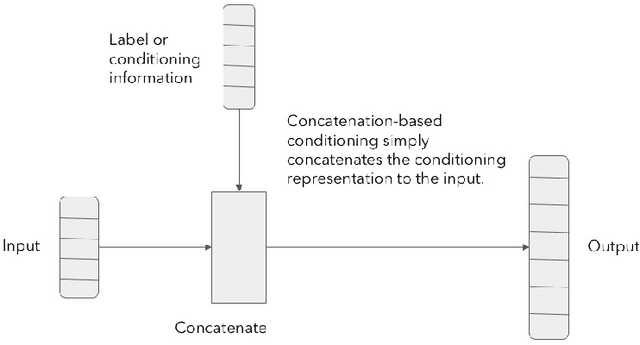
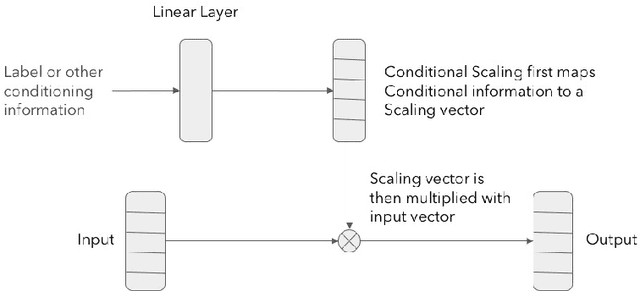
Generative models are successfully used for image synthesis in the recent years. But when it comes to other modalities like audio, text etc little progress has been made. Recent works focus on generating audio from a generative model in an unsupervised setting. We explore the possibility of using generative models conditioned on class labels. Concatenation based conditioning and conditional scaling were explored in this work with various hyper-parameter tuning methods. In this paper we introduce Conditional WaveGANs (cWaveGAN). Find our implementation at https://github.com/acheketa/cwavegan